
Masked Image Modeling with Denoising Contrast
Contents
- Abstract
- Introduction
- Related Work
- SSL via vision dictionary look-up
- Tokenizer-free MIM methods
- Dense Contrast vs. Denoising Contrast
- Preliminaries
- CL: INSTANCE-LEVEL vision dictionary look-up
- MIM: PATCH-LEVEL vision dictionary look-up
- MIM with Denoising Contrast
- Patch-level dynamic dictionary
- Denoising contrastive objective
- Asymmetric design
- Pseudocode
0. Abstract
How to design proper pretext tasks for vision dictionary look-up?
- MIM recently dominates, using ViTs
- key point : enhance the patch-level visual context capturing of the network ( via denoising auto-encoding mechanism )
Rather than tailoring image tokenizers with extra training stages …
\(\rightarrow\) unleash the great potential of CL on “denoising auto-encoding”
& introduce a pure MIM method, ConMIM
1. Introduction
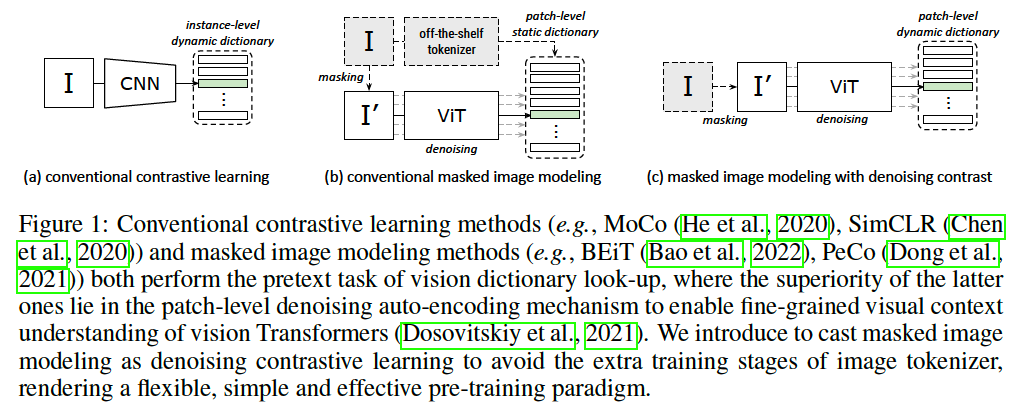
Figure 1-(a) : SSL with a pretext task of “instance-level” dictionary look-up via “CL”
Figure 1-(b) : ( thanks to ViTs ! ) introduction of “patch-level” dictionary look-up via “MIM”
- portion of vision tokens are randomly masked & recovered by the Transformer
Concurrent works
-
efforts to design “patch-level” dictionaries ( = image tokenizers ) for MIM
-
ex) discrete VAE used in BEiT
- depend on “extra” training stages and data knowledge
- inflexible “two-stage” pre-training paradigm.
We would like to call for a revisit of the superiority of MIM over CL
- they are essentially both designed towards vision dictionary look-up
- CL : instance-level dictionary look-up
- MIM : patch-level dictionary look-up
- key difference :
- lies in the “PATCH-level” denoising auto-encoding mechanism in MIM
- encourages the network’s capability to capture fine-grained visual context and semantics.
- lies in the “PATCH-level” denoising auto-encoding mechanism in MIM
For AE objective, we do not have to intentionally discretize the continuous visual signals
- Instead, we can give full play to the wisdom of CL
- CL : has good capability to structure the visual space with semantically meaningful representations.
Proposal: ConMIM
Summary
-
introduce a new pre-training method for MIM
-
get rid of extra tokenizing networks by revitalizing CONTRASTIVE LEARNING ( Figure 1-(c) )
Details:
casts masked patch prediction as denoising CL
-
(1 The corrupted input ( with a large proportion of patches masked ) is fed into the encoder
-
(2) Encoder learns to recover the representations of the masked patches
-
Objective : intra-image inter-patch contrastive loss.
- patch representations of a full input image build a dynamic dictionary
-
Keys :
- (Positive Keys) patches from the SAME positions ( as the masked ones of the corrupted input )
- (Negative Keys) remaining patches from DIFFERENT positions but in a same image
-
To further improve the network via a stronger denoising auto-encoding mechanism …
\(\rightarrow\) introduce asymmetric designs in ConMIM training
- (1) asymmetric image perturbations
- strong augmentation for the full input
- weak augmentation for the corrupted input
- (2) asymmetric model progress rates
-
image encoder: slowly progressing momentum encoder
( for the full input to embed more challenging but semantically consistent learning targets )
-
- (1) asymmetric image perturbations
2. Related Work
(1) SSL via vision dictionary look-up
a) Contrastive Learning
CL generally perform instance-level dictionary lookup
\(\rightarrow\) establishment of vision dictionaries is critical for the contrast regularization!!
Examples)
- [MoCo] builds the vision dictionary with a FIFO queue & momentum encoder
- [SimCLR] uses a large batch size to enlarge the dictionary with more negative keys
- [SwAV] introduces an online clustering algorithm in an unsupervised manner
- cluster assignments serve for the dictionary keys
\(\rightarrow\) these methods are gradually abandoned with the introduction of ViTs
- due to the lack of inductive bias, which requires stronger supervision for better pre-training performance.
b) Masked Image Modeling
Attempt to use MLM in Image … MIM
\(\rightarrow\) self-supervised learning of ViTs via patch-level dictionary look-up.
Examples)
- [BEiT] introduces a new pretext task, MIM
- tokenize high-dimensional images into discrete vision tokens by a discrete VAE
- a proportion of image patches are randomly masked
- further works to improve static dictionaries
- [mc-BEiT] introduces eased and refined dictionaries with multiple choices.
- [PeCo] proposes to produce perceptual-aware keys in the patch-level dictionary
Still ….. these methods all require extra training stages and even extra data for obtaining a proper image tokenizer.
(2) Tokenizer-free MIM methods
Other works : cast MIM as ….
- MAE (He et al., 2022) : a pixel-level reconstruction task
- iBOT (Zhou et al., 2022) : a self-distillation task
rather than dictionary look-up
\(\rightarrow\) fail to achieve competitive results & unsatisfactorily on small-scale architectures
iBOT : not a pure MIM method
-
heavily depends on the vanilla DINO (Caron et al., 2021) loss (i.e., the global self-distillation loss on [CLS] tokens).
-
conducts MIM on top of DINO & argues that MIM alone hardly captures visual semantics.
\(\rightarrow\) but actually, it is due to the improper MIM constraints
This paper proposes a flexible pure MIM method without extra dependencies
( including offline tokenizer or global discrimination loss )
(3) Dense Contrast vs. Denoising Contrast
Previous works on CL
[ DenseCL (Wang et al., 2021) ] devoted to taking local feature representations into consideration
-
form of InfoNCE is similar as ours
-
but they focus onhow to learn better pre-trained weights for “dense downstream tasks”
-
hardly encourage the patch-level visual context reasoning as it is a contrastive-only task,
showing inferior performance on ViT pre-training.
-
depends on the global discrimination loss to ensure correct local correspondences
& needs to carefully balance the global and local constraints.
3. Preliminaries
Pretraining-and-then-Finetuning paradigm
- effective for visual representation learning & various downstream tasks
- self-supervised pre-training is the most popular
- the design of pretext tasks is critical to thepre-training performance.
- even though various …. the pretext task of visual self-supervised learning is essentially to perform vision dictionary look-up
(1) CL: INSTANCE-LEVEL vision dictionary look-up
Examples) establish instance-level vision dictionaries via …
- MoCo (He et al., 2020) : a fixed-length queue
- SimCLR (Chen et al., 2020) :batch-wise samples
\(\rightarrow\) the keys in the dictionary are dynamically updated as pre-training proceeds
Process
- input : \(x\)
- representation : \(f(x)\)
- InfoNCE loss : \(\mathcal{L}_{\text {con }}(x)=-\log \frac{\exp \left(\left\langle f(x), k_{+}\right\rangle / \tau\right)}{\sum_{i=1}^K \exp \left(\left\langle f(x), k_i\right\rangle / \tau\right)}\)
- \(k\) : the dynamic key
- \(K\) : dictionary size
- Generally, the positive key is built by another view of the same instance ( = different image augmentations. )
(2) MIM: PATCH-LEVEL vision dictionary look-up
pretext task of MIM : gradually dominates visual representation learning
- randomly masks a large percentage of image patches
- trains the backbone network to recover the token ids of corrupted image
- via more fine-grained patch-level vision dictionary look-up
(Previous) Dictionaries :
-
generally static and pre-defined by an off-the-shelf image tokenizer
- which converts continuous visual signals into discrete keys
-
examples) BEiT (Bao et al., 2022)
-
pre-learned discrete VAE
-
masked patch prediction = casted as CLS with CE loss
\(\mathcal{L}_{\operatorname{mim}}(x)=\mathbb{E}_{j \in \mathcal{M}}\left[-\log p\left(y_j \mid f(\hat{x})_j\right)\right]\).
- \(\mathcal{M}\) : the set of masked patch indices
- \(\hat{x}\) : corrupted image after randomly masking
- \(y_j\) : positive key index in the patch-level dictionary
- \(p(\cdot \mid \cdot)\) : the probability that correctly identifies the recovered patch \(f(\hat{x})_j\) with a patch index of \(j\).
-
4. MIM with Denoising Contrast
CL & MIM
- both attempt to learn discriminative visual representations via dictionary look-up
Two key factors lead to the SOTA of masked image modeling.
- (1) More fine-grained supervision from instance-level to patch-level
- (2) The denoising auto-encoding mechanism :
- encourages the capability of the backbone network to capture “contextualized” representations.
But previous MIM methods :
- either require extra training stages to establish static vision dictionaries with offline image tokenizers!
ConMIM
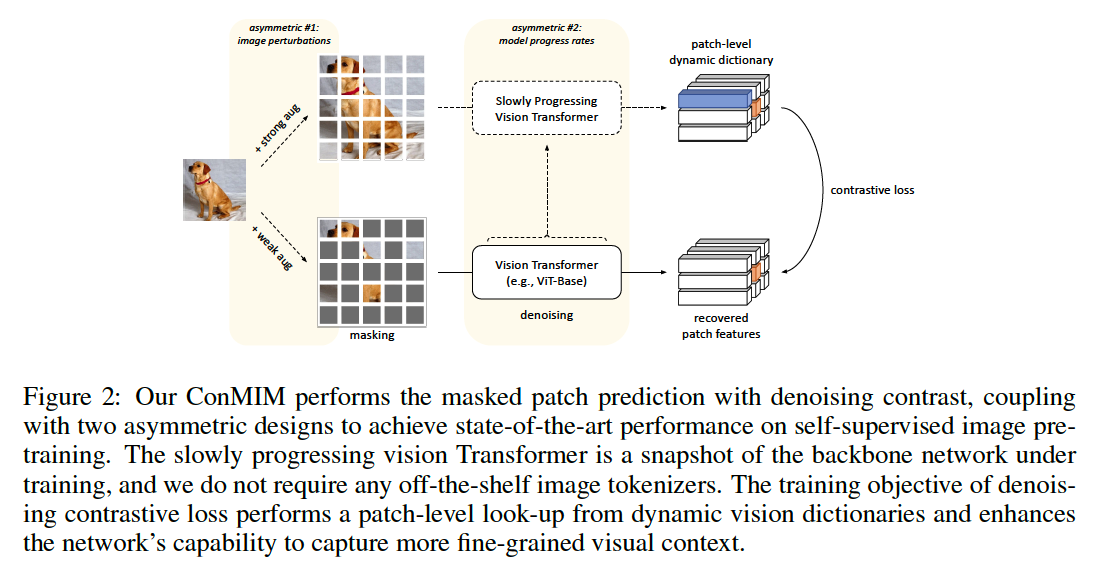
Revitalization of CL! good capability to structure the latent space for SSL
\(\rightarrow\) proposes ConMIM, to perform pure masked image modeling with denoising contrastive objectives
( do not need pre-learned image tokenizers )
(1) Patch-level dynamic dictionary
build dynamic patch-level dictionaries
- to form the learning targets for masked patch prediction on-the-fly
Procedure: ( during each training iteration … )
-
input \(x\) is fed into backbone to embed the patch feature representations
\(\rightarrow\) serve as keys in the dynamic dictionary, i.e., \(\{\left.f(x)_i \mid _{i=1} ^K\right\}\)
- \(i\) : patch index
- \(K\) : dictionary size ( as well as the total number of patches within an image )
- ex) \(K\)=196 keys for a \(224 \times 224\) image with a patch size of \(16 \times 16\)
-
build separate dictionaries for each image
( = only operate patch-level dictionary look-up within each image )
(2) Denoising contrastive objective
Procedure
- corrupted image \(\hat{x}\), is fed into the backbone
- denote the encoded patch feature representation of a certain masked patch as \(f(\hat{x})_j, j \in \mathcal{M}\).
- backbone : trained to denoise the corrupted image & recover the masked patches
- masked patch recovery : regularized by a patch-level dictionary look-up ( InfoNCE form )
- \(\mathcal{L}_{\text {conmim }}(x)=\mathbb{E}_{j \in \mathcal{M}}\left[-\log \frac{\exp \left(\left\langle f(\hat{x})_j, \operatorname{sg}\left[f(x)_j\right]\right\rangle / \tau\right)}{\sum_{i=1}^K \exp \left(\left\langle f(\hat{x})_j, \operatorname{sg}\left[f(x)_i\right]\right\rangle / \tau\right)}\right]\).
- only backpropagate the gradients of the corrupted inputs \(f(\hat{x})\)
- \(\because\) backpropagating the gradients of the full input \(f(x)\) may lead to information leakage
\(\rightarrow\) backbone is encouraged to better capture the visual context & learns to encode local discriminative representations.
(3) Asymmetric design
Patchs = small-scale inputs with less useful information & highly redundant semantics
\(\rightarrow\) need to make the pre-training task more challenging!
Previous works
- MAE (He et al., 2022) : proposes to mask a large proportion of patches
- ConMIM (proposed) : further introduce two asymmetric designs to enable a stronger denoising regularization during pre-training.
Two asymmetric designs
-
(1) Asymmetric image perturbations
-
adopt different data augmentations for the \(x\) and \(\hat{x}\)
( stronger augmentations for \(x\) )
-
-
(2) Asymmetric model progress rates
-
employ different model progress rates of the backbone
-
momentum encoder (He et al., 2020) : slowly progressing model that can encode more challenging but semantically consistent key feature representations for building dictionaries.
-
Notation
-
parameter \(\theta\)
-
parameters of the momentum updated \(\tilde{\theta}\)
-
via \(\tilde{\theta}=(1-\alpha) \theta+\alpha \tilde{\theta}\) in each iteration,
-
where \(\alpha \in[0,1]\) is the momentum coefficient.
( Larger coefficients = slower model progress )
-
-
-
5. Pseudocode
