Contrastive Learning for Unsupervised Domain Adaptation of Time Series
Contents
- Abstract
- Introduction
- Related Works
- Unsupervised Domain Adaptation (UDA)
- UDA for TS
- Problem Definition
- Proposed CLUDA Framework
- Architecture
- Adversarial Training for UDA
- Capturing Contextual Representations
- Aligning the Contextual Representation Across Domains
- Experimental Setups
- Results
0. Abstract
Unsupervised domain adaptation (UDA)
- learn model using LABELED source domain that performs well on UNLABELED target domain
CLUDA
develop a novel framework for UDA of TS data
propose a CL framework in MTS
- preserve label information for the prediction task.
capture the variation in the contextual representations between SOURCE & TARGET domain
- via a custom nearest-neighbor CL
First framework to learn domain-invariant representation for UDA of TS data
1. Introduction
Need for effective domain adaptation of TS, to learn **domain-invariant representations **
Unsupervised domain adaptation (UDA)
Few works have focused on UDA of TS
Previous works
-
utilize a tailored feature extractor to capture temporal dynamics of MTS via RNNs, LSTM, CNNs …
-
minimize the “domain discrepancy” of learned features via ..
- (1) adversarial-based methods (Purushotham et al., 2017; Wilson et al., 2020; 2021; Jin et al., 2022)
- (2) restrictions through metric-based methods (Cai et al., 2021; Liu \& Xue, 2021).
Transfer Learning
pre-train a NN via CL …
to capture the contextual representation of TS from UN-LABELED source domain
- BUT … operate on a LABELED target domain ( \(\neq\) UDA )
No method for UDA of TS
\(\rightarrow\) propose a novel framework for UDA of TS based on CL ( = CLUDA )
Components of CLUDA
(1) Adversarial training
- to minimize the domain discrepancy between source & target domains
(2) Semantic-preserving augmentations
(3) Custom nearest-neighborhood CL
- further align the contextual representation across source and target domains
Experiments
Datasets 1
- WISDM (Kwapisz et al., 2011)
- HAR (Anguita et al., 2013)
- HHAR (Stisen et al., 2015)
\(\rightarrow\) CLUDA leads to increasing accuracy on target domains by an important margin.
Datasets 2
( two largescale real-world medical datasets )
- MIMIC-IV (Johnson et al., 2020)
- AmsterdamUMCdb (Thoral et al., 2021)
Contributions
-
Propose CLUDA
( unsupervised domain adaptation of time series )
-
Capture domain-invariant, contextual representations in CLUDA
- via a custom approach combining (1) nearest-neighborhood CL & (2) adversarial learning
2. Related Work
(1) Unsupervised Domain Adaptation (UDA)
LABELED source \(\rightarrow\) UNLABELED target
Typically aim to minimize domain discrepancy
3 Categories
(1) Adversarial-based
-
reduce domain discrepancy via domain discriminator networks
( force to learn domain-invariant feature representations )
(2) Contrastive
- via minimization of CL loss, aims to bring source & target embeddings of the same class
- labels are UNKNONWN … rely on pseudo-labels
(3) Metric-based
(2) UDA for TS
a) Variational recurrent adversarial deep domain adaptation (VRADA)
first UDA method for MTS that uses adversarial learning for reducing domain discrepancy.
- Feature extractor = variational RNN
- trains the (1) classifier and the (2) domain discriminator (adversarially)
b) Convolutional deep domain adaptation for time series (CoDATS)
VRADA + ( Feature extractor = CNN )
c) Time series sparse associative structure alignment (TS-SASA)
Metric-based method
- Intra-variables & Inter-variables attention mechanisms are aligned between the domains via the minimization of maximum mean discrepancy (MMD).
d) Adversarial spectral kernel matching (AdvSKM)
Metric-based method
-
aligns the two domains via MMD
-
introduces a spectral kernel mapping,
from which the output is used to minimize MMD between the domains.
\(\rightarrow\) [ Common ] Aim to align the features across SOURCE and TARGET domains.
Research Gap
Existing works merely align the features across source & target domains.
Even though the source and target distributions overlap … this results in mixing the source and target samples of different classes.
3. Problem Definition
Classification task
2 distributions over the TS
- a) SOURCE domain \(\mathcal{D}_S\)
- b) TARGET domain \(\mathcal{D}_t\)
Labeled samples from the SOURCE domain
- given by \(\mathcal{S}=\left\{\left(x_i^s, y_i^s\right)\right\}_{i=1}^{N_s} \sim \mathcal{D}_S\),
Unlabeled samples from the TARGET domain
- given by \(\mathcal{T}=\left\{x_i^t\right\}_{i=1}^{N_t} \sim \mathcal{D}_T\)
Each \(x_i\) is a sample of MTS,
- denoted by \(x_i=\left\{x_{i t}\right\}_{t=1}^T \in \mathbb{R}^{M \times T}\)
Goal : build a classifier
- that generalizes well over \(\mathcal{T}\)
- by leveraging the labeled \(\mathcal{S}\).
( At evaluation ) use the labeled \(\mathcal{T}_{\text {test }}=\left\{\left(x_i^t, y_i^t\right)\right\}_{i=1}^{N_{\text {test }}} \sim \mathcal{D}_T\)
4. Proposed CLUDA Framework
Overview of our CLUDA framework
- Domain adversarial training
- Capture the contextual representation
- Align contextual representation across domains.
(1) Architecture
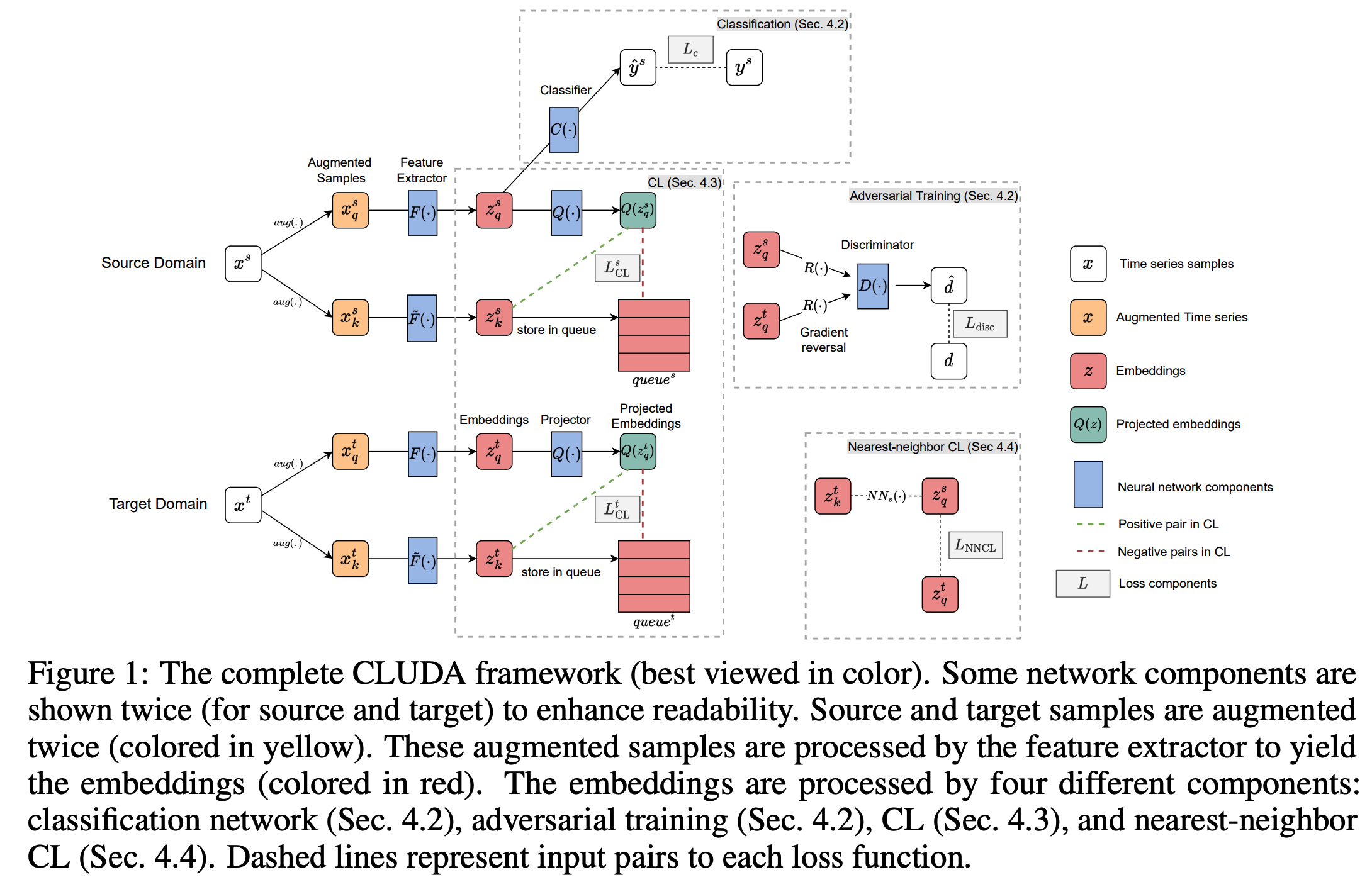
(1) Feature extractor \(F(\cdot)\)
- Input = \(x^s\) and \(x^t\)
- Output = \(z^s\) and \(z^t\)
- Momentum updated version = \(\tilde{F}(\cdot)\)
(2) Classifier network \(C(\cdot)\)
- Predict \(y^s\) using \(z^s\).
(3) Discriminator network \(D(\cdot)\)
- Trained to distinguish \(z^s\) & \(z^t\).
- Introduce domain labels
- \(d=0\) for SOURCE
- \(d=1\) for TARGET
(2) Adversarial Training for UDA
Minimize a combination of two losses:
(1) Prediction loss \(L_c\)
\(L_c=\frac{1}{N_s} \sum_i^{N_s} L_{\mathrm{pred}}\left(C\left(F\left(x_i^s\right)\right), y_i^s\right)\).
(2) Domain classification loss \(L_{\mathrm{disc}}\)
\(L_{\text {disc }}=\frac{1}{N_s} \sum_i^{N_s} L_{\text {pred }}\left(D\left(R\left(F\left(x_i^s\right)\right)\right), d_i^s\right)+\frac{1}{N_t} \sum_i^{N_t} L_{\text {pred }}\left(D\left(R\left(F\left(x_i^t\right)\right)\right), d_i^t\right)\).
-
Adversarial learning
- \(D(\cdot)\) = trained to MINIMIZE the loss
- \(F(\cdot)\) = trained to MAXIMIZE the loss
-
achieved by the gradient reversal layer \(R(\cdot)\) between \(F(\cdot)\) and \(D(\cdot)\),
defined by \(R(x)=x, \quad \frac{\mathrm{d} R}{\mathrm{~d} x}=-\mathbf{I}\)
(3) Capturing Contextual Representations
(1) Encourage \(F(\cdot)\) to learn label-preserving information captured by the context.
(2) Hypothesize that (a) < (b)
- (a) discrepancy between the contextual representations of two domains
- (b) discrepancy between their feature space
Leverage CL in form of MoCo
-
apply semantic-preserving augmentations to each sample of MTS
-
2 views of each sample
- query \(x_q\) …… \(z_q=F\left(x_q\right)\)
- key \(x_k\) ……. \(z_k=\tilde{F}\left(x_k\right)\)
Momentum-updated feature extractor
- \(\theta_{\tilde{F}} \leftarrow m \theta_{\tilde{F}}+(1-m) \theta_F\).
Contrastive loss
- \(L_{\mathrm{CL}}=-\frac{1}{N} \sum_{i=1}^N \log \frac{\exp \left(Q\left(z_{q i}\right) \cdot z_{k i} / \tau\right)}{\exp \left(Q\left(z_{q i}\right) \cdot z_{k i} / \tau\right)+\sum_{j=1}^J \exp \left(Q\left(z_{q i}\right) \cdot z_{k j} / \tau\right)}\).
Since we have two domains (i.e., source and target)
\(\rightarrow\) two CL loss ( \(L_{\mathrm{CL}}^s\) & \(L_{\mathrm{CL}}^t\) )
(4) Aligning the Contextual Representation Across Domains
Further aligns the contextual representation across the SOURCE & TARGET
First nearest-neighbor CL approach for UDA of TS
**Nearest-neighbor CL (NNCL) **
- facilitate the classifier \(C(\cdot)\) to make accurate predictions for the target domain
- by creating positive pairs between domains
- explicitly align the representations across domains.
\(L_{\mathrm{NNCL}}=-\frac{1}{N_t} \sum_{i=1}^{N_t} \log \frac{\exp \left(z_{q i}^t \cdot N N_s\left(z_{k i}^t\right) / \tau\right)}{\sum_{j=1}^{N_s} \exp \left(z_{q i}^t \cdot z_{q j}^s / \tau\right)}\).
- retrieves the nearest-neighbor of an embedding from the source queries \(\left\{z_{q i}^s\right\}_{i=1}^{N_s}\).
(5) Training
\(L=L_c+\lambda_{\mathrm{disc}} \cdot L_{\mathrm{disc}}+\lambda_{\mathrm{CL}} \cdot\left(L_{\mathrm{CL}}^s+L_{\mathrm{CL}}^t\right)+\lambda_{\mathrm{NNCL}} \cdot L_{\mathrm{NNCL}}\).
5. Experimental Setup
Earlier works of UDA on time series
- Wilson et al., 2020; 2021; Cai et al., 2021; Liu \& Xue, 2021
(1) Datasets
- Established benchmark datasets
- WISDM (Kwapisz et al., 2011), HAR (Anguita et al., 2013), and HHAR (Stisen et al., 2015).
- each patient = each domain
- randomly sample 10 source-target domain pairs for evaluation.
- Real-world setting with medical datasets
- MIMIC-IV (Johnson et al., 2020) and AmsterdamUMCdb (Thoral et al., 2021).
- each age group = each domain
(2) Baselines
Model w/o UDA
- use feature extractor \(F(\cdot)\) and the classifier \(C(\cdot)\) using the same architecture as in our CLUDA.
- only trained on the source domain.
Model w/ UDA ( for TS )
- (1) VRADA (Purushotham et al., 2017)
- (2) CoDATS (Wilson et al., 2020)
- (3) TS-SASA (Cai et al., 2021)
- (4) AdvSKM (Liu \& Xue, 2021)
Model w/ UDA ( not CV )
- (5) CAN (Kang et al., 2019)
- (6) CDAN (Long et al., 2018)
- (7) DDC (Tzeng et al., 2014)
- (8) DeepCORAL (Sun \& Saenko, 2016)
- (9) DSAN (Zhu et al., 2020)
- (10) HoMM (Chen et al., 2020a)
- (11) MMDA (Rahman et al., 2020).
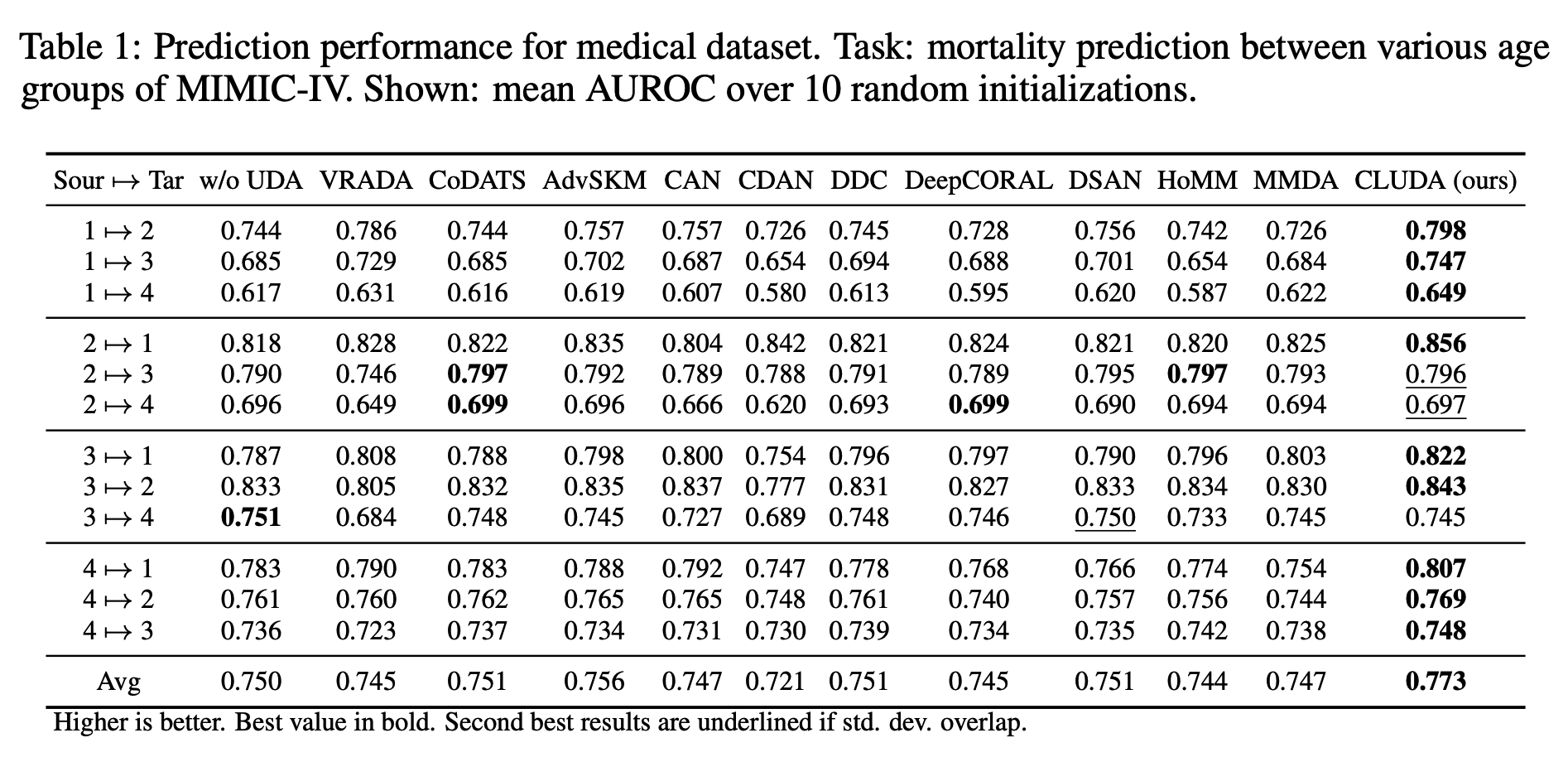
6. Results
(1) Established benchmark datasets
Average accuracy of each method for 10 source-target domain pairs
- on the WISDM, HAR, and HHAR datasets

-
to study the domain discrepancy
-
(a) The embeddings of w/o UDA
- significant domain shift between source and target
- two clusters of each class (i. e., one for each domain)
-
(b) CDAN as the best baseline
-
reduces the domain shift
-
by aligning the features of source and target for some classes,
( BUT mixes the different classes of the different domains (e.g., blue class of source and green class of target overlap). )
-
-
(c) CLUDA
- pulls together the source (target) classes for the source (target) domain (due to the CL)
- pulls both source and target domains together for each class (due to the alignment).
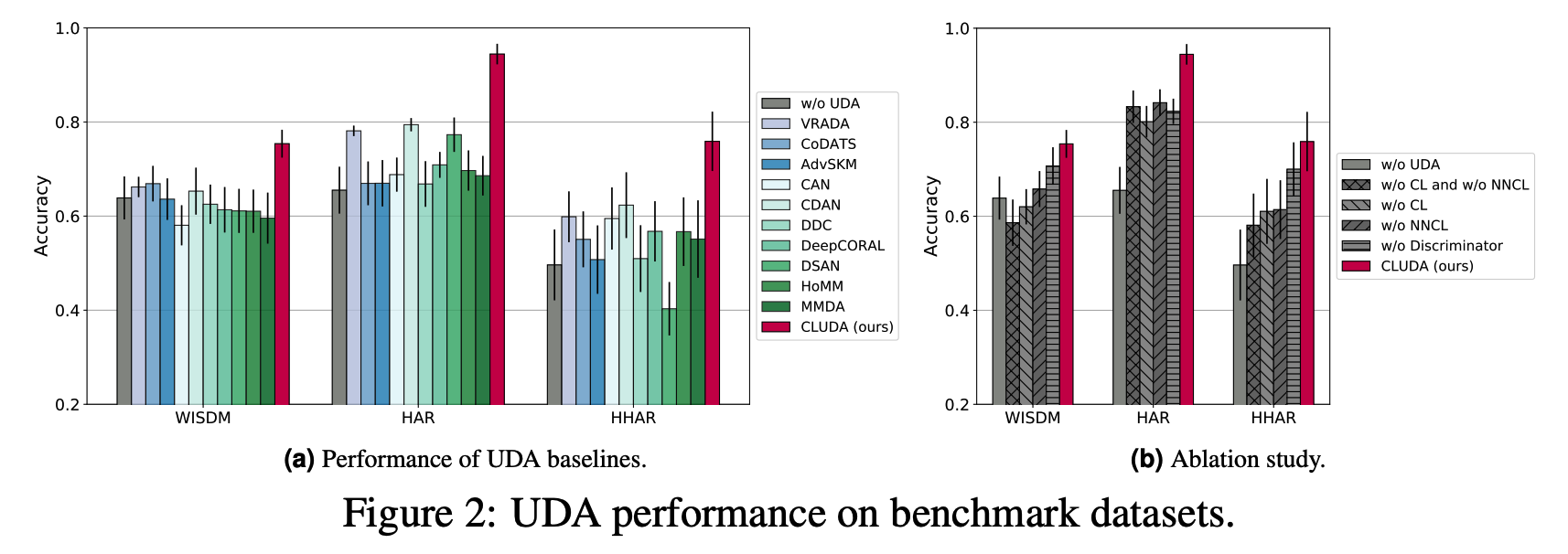
Ablation Study
Figure 2-(b)
(2) Real-world setting with medical datasets