
( 참고 : 패스트 캠퍼스 , 한번에 끝내는 컴퓨터비전 초격차 패키지 )
Vision Transformer (ViT)
1. Introduction
-
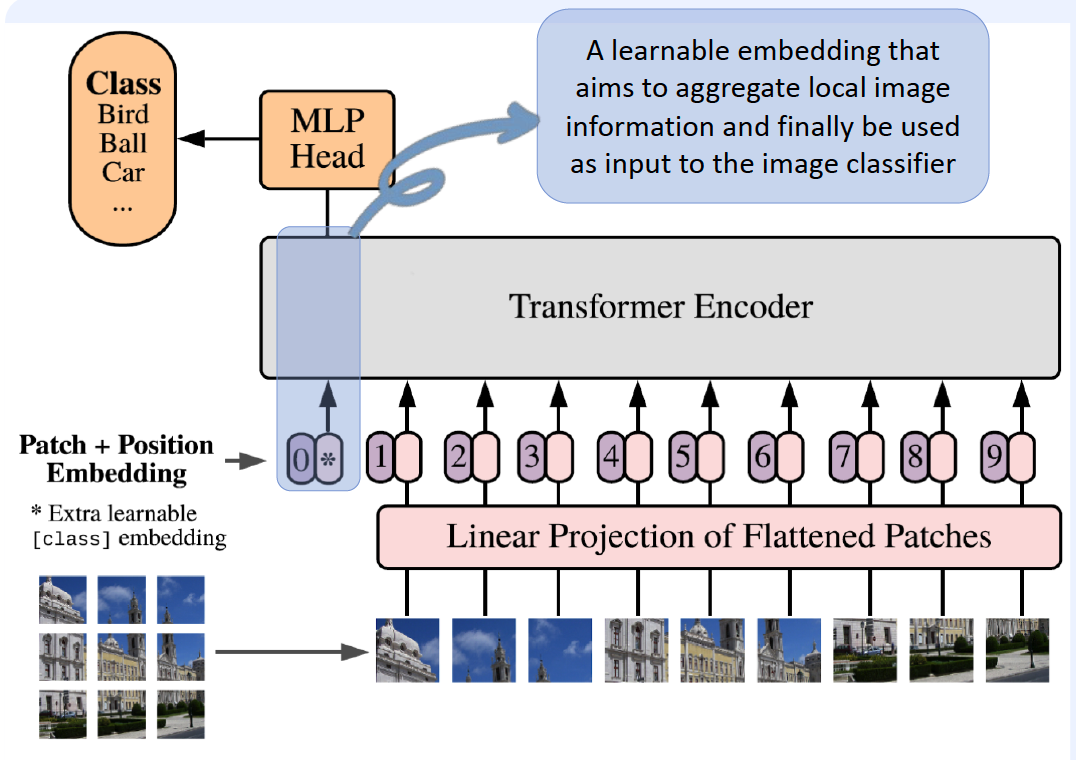
transformer encoder, which consists of alternating layers of Multi-head Self-attention
-
linear embeddings of image patches
( + 1d positional embeddings )
-
works well on very large-scale datasets
-
first token
- aggregate local information
- used as an input to image classifier
2. Variants
3. Code
(1) Transformer
transformer_model = nn.Transformer(nhead=16, num_encoder_layers=12)
src = torch.rand((10, 32, 512))
tgt = torch.rand((20, 32, 512))
out = transformer_model(src, tgt)
(2) ViT
import torchvision.models as models
vit_b_16 = models.vit_b_16(pretrained=True)
vit_b_32 = models.vit_b_32(pretrained=True)
vit_l_16 = models.vit_l_16(pretrained=True)
vit_l_32 = models.vit_l_32(pretrained=True)