
( 참고 : 패스트 캠퍼스 , 한번에 끝내는 컴퓨터비전 초격차 패키지 )
Deformable DeTR
( Zhu, Xizhou, et al. “Deformable detr: Deformable transformers for end-to-end object detection.” arXiv preprint arXiv:2010.04159 (2020). )
1. Deformable Convolution

Original Convolution :
-
\(\mathbf{y}\left(\mathbf{p}_{0}\right)=\sum_{\mathbf{p}_{n} \in \mathcal{R}} \mathbf{w}\left(\mathbf{p}_{n}\right) \cdot \mathbf{x}\left(\mathbf{p}_{0}+\mathbf{p}_{n}\right)\).
-
fixed receptive field
Deformable Convolution :
- \(\mathbf{y}\left(\mathbf{p}_{0}\right)=\sum_{\mathbf{p}_{n} \in \mathcal{R}} \mathbf{w}\left(\mathbf{p}_{n}\right) \cdot \mathbf{x}\left(\mathbf{p}_{0}+\mathbf{p}_{n}+\Delta \mathbf{p}_{n}\right)\).
- add offset
- flexible receptive field
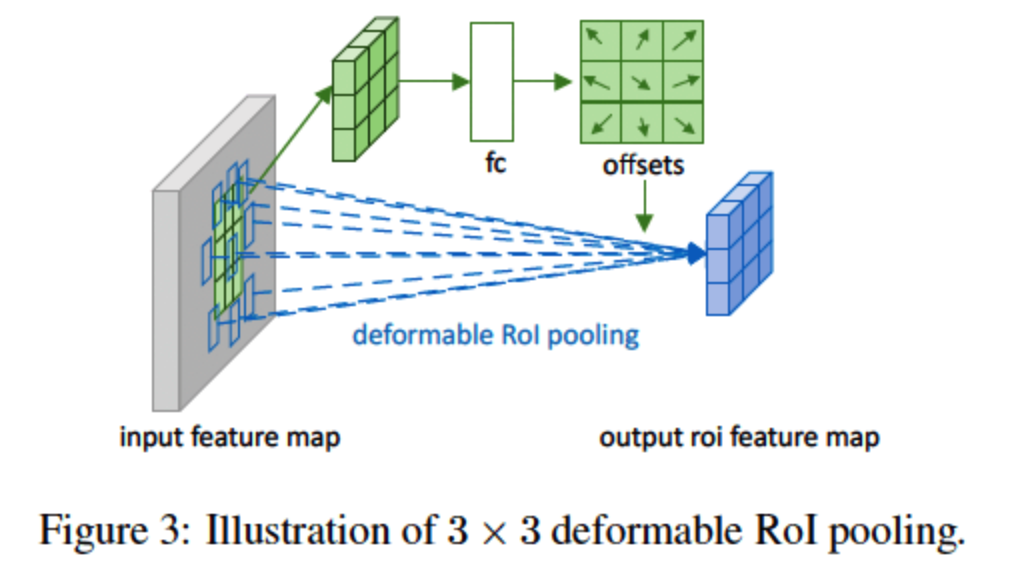
So, how to find offset?
\(\rightarrow\) use another CNN filer!
2. Deformable DeTR
(1) Multi-Scale
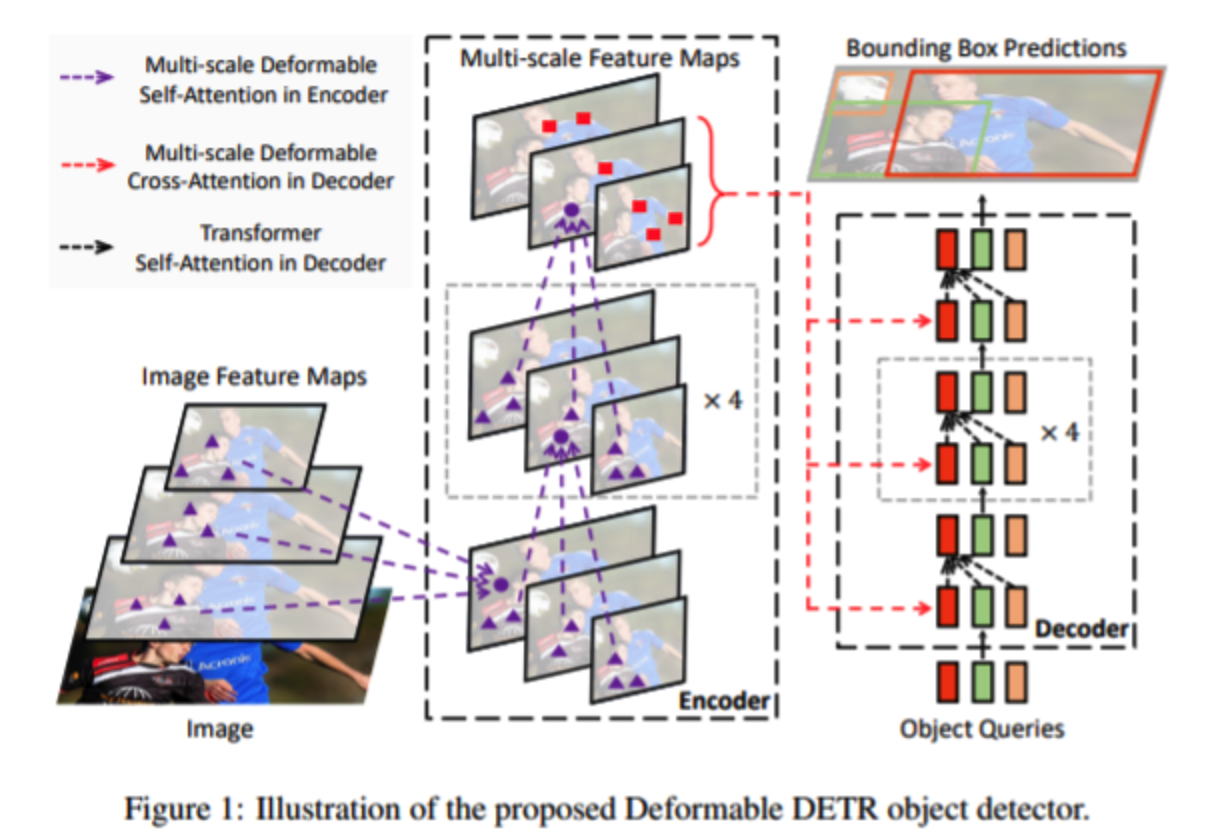
- use multi-scale feature map
(2) Deformable Attention
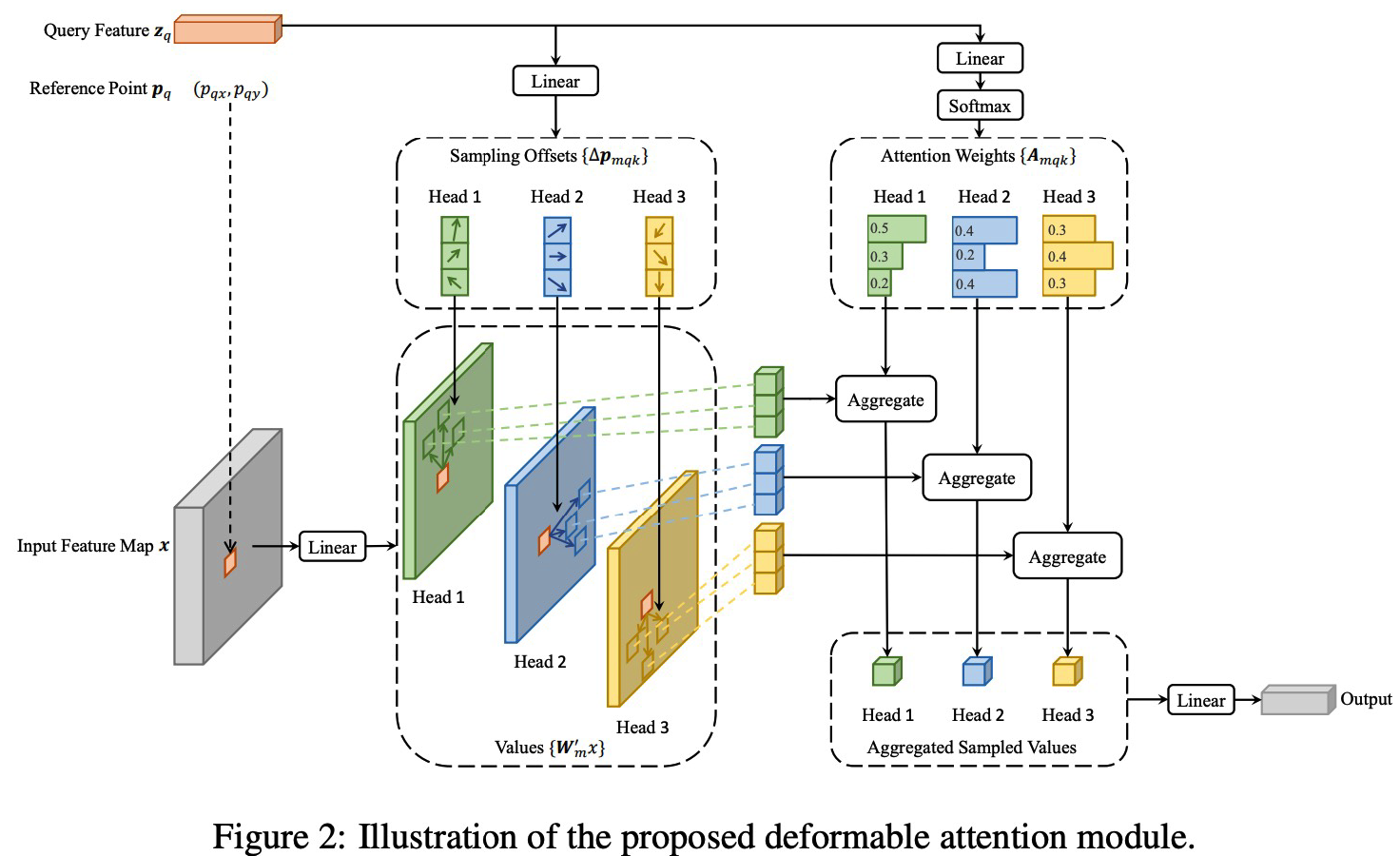
-
instead of attention on all pixels…. only selected pixels using deformation
-
with linear layer…. get
- (1) sampling offset
- (2) attention weights