
( 참고 : “FastCampus, 데이터 엔지니어링 올인원” )
[ Data Engineering ]
Presto & Athena
1. Presto란?
(Wikipedia) Presto is a high performance, distributed SQL query engine for big data. Its architecture allows users to query a variety of data sources such as Hadoop, AWS S3, Alluxio, MySQL, Cassandra, Kafka, MongoDB and Teradata. One can even query data from multiple data sources within a single query.
-
요약 : 다양한 데이터의 소스로부터, “SINGLE query”를 통해서 처리할 수 있다!
-
(trend) spark에서 Presto에서 넘어오는 양상!
( Spark는 어느 정도의 scripting이 필요하다 )
2. Serverless?
어떠한 서비스를 만들 때, 개인 PC를 항상 켜둘 수 없으므로 EC2라는 가상의 서버를 만든다. 이 서버의 용량을 정해야 하는데, 서비스에 접속하는 유저의 수는 그때 그때 다르다. 그렇다고 무작정 엄청 큰 서버를 사용할 수는 없는 법이다. (비용 문제)
그러기 위해 사용하는 것이 “Sereverless”!
Serverless = 서버가 없다?
-
실제로 서버가 없는건 아니고, 특정 작업을 수행하기 위해 가상 머신에 서버를 설정하고, 이를 통해 처리하는 것
-
지속적인 요청이 들어온다면, 지속적으로으로 병렬적인 server를 띄우는 것
( server안에서 용량을 정하는 것을 알아서 자동적으로 해결해 주므로 비용적인 문제 해결 )
-
ex) AWS의 Lambda, Athena
-
이를 통해, 변동하는 유저 수에도 잘 대비하여 서버를 효율적으로 잘 관리할 수 있다!
3. Athena
- presto 기반의 AWS 빅데이처 처리 플랫폼 ( serverless )
- partion을 기반으로, S3내의 data를 빠르게 가져와서 ad-hoc분석을 쉽게 할 수 있음
- parquet 형식의 데이터 처리하기 용이
create table 버튼을 누르면, 다음과 같이 query문을 입력할 수 있음
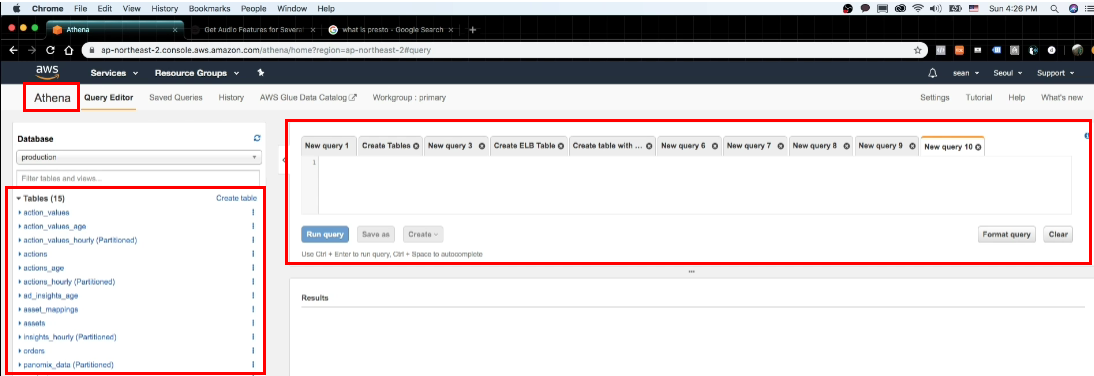
4. Athena 통해 테이블 생성하기
-
(1) Top Tracks 테이블 생성
- querey문에, parquet 형식의 데이터가 존재하는 path로 지정해준다.
- 파티션을 추가한 후,
MSCK REPAIR TABLE명령을 사용하여 데이터를 업데이트한다.

- (2) Audio Features 테이블 생성
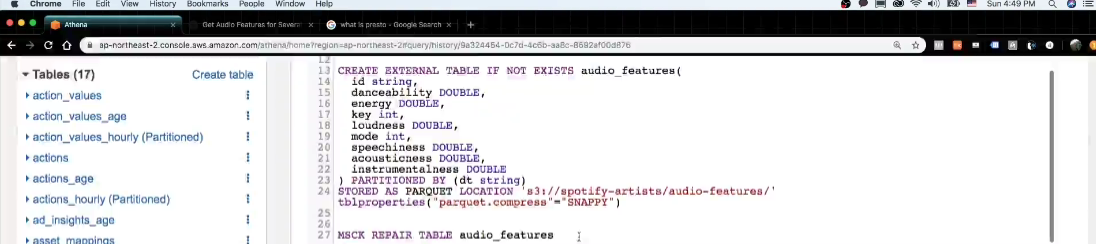
5. Presto - Functions & Operators
위 사이트를 통해서 구체적인 함수들을 확인할 수 있다.