
( 참고 : “FastCampus, 데이터 엔지니어링 올인원” )
[ Data Engineering ]
Data Lake & AWS S3 실습
Python을 통해, 이전에 만든 Bucket에 어떻게 데이터를 넣을 수 있는 지 알아볼 것이다.
순서
- 1) RDS에서 아티스트 ID를 가져온다
- 2) Spotify API를 통해 데이터를 불러온다
- 1) Top Track
- 2) Audio Feature
- 3) 이를 json 형태로 저장하고, S3에 import한다
1. Import Packages
boto3 : AWS python SDK
import sys
import os
import logging
import boto3
import requests
import base64
import json
import pymysql
from datetime import datetime
import pandas as pd
import jsonpath
2. Top Tracks 데이터
(2-1) Top Tracks 가져오기
jsonpath 패키지 : 해당 path안에 어떠한 data를 입력했을 때, 그 data 안에서 key값을 통해서 value를 찾음
1) RDS에서 아티스트 ID를 가져오기 ( 상위 10개의 아티스트 )
cursor.execute("SELECT id FROM artists LIMIT 10")
어떠한 정보들을 알아내고 싶은가? top_track_keys
- id / name / popularity / external url
top_track_keys = {
"id": "id",
"name": "name",
"popularity": "popularity",
"external_url": "external_urls.spotify"
}
2) 데이터 가져오기
-
top_track.update({k: jsonpath.jsonpath(i, v)}):jsonpath 패키지를 사용해서, key를 통해 바로 가져오기!
top_tracks = []
for (id, ) in cursor.fetchall():
URL = "https://api.spotify.com/v1/artists/{}/top-tracks".format(id)
params = {'country': 'US'}
r = requests.get(URL, params=params, headers=headers)
raw = json.loads(r.text)
for i in raw['tracks']:
top_track = {}
for k, v in top_track_keys.items():
top_track.update({k: jsonpath.jsonpath(i, v)})
top_track.update({'artist_id': id})
top_tracks.append(top_track)
(2-2) Parquet화
spark의 경우, json보다는 Parquet 형식이 더 낫다!
따라서 parquet화하는 방법에 대해서 알아볼 것이다. ( via Pandas )
- 형식 :
.parquet - engine :
pyarrow(패키지 이름) - compression (데이터 압축 방식) :
snappy
top_tracks = pd.DataFrame(top_tracks)
top_tracks.to_parquet('top-tracks.parquet', engine='pyarrow', compression='snappy')
(2-3) S3 사용
-
partition을 통해서 가져온다 ( 기준 :
dt(datetime) ) -
spotify artists 폴더(bucket)
- top-tracks 폴더
- dt=오늘날짜
- 여기에
top-tracks.parquet(파켓 형식)으로 데이터 저장
- 여기에
- dt=오늘날짜
- top-tracks 폴더
s3 = boto3.resource('s3')
object = s3.Object('spotify-artists', 'top-tracks/dt={}/top-tracks.parquet'.format(dt))
data = open('top-tracks.parquet', 'rb')
object.put(Body=data)
3. Audio Features
(3-1) Audio Features 가져오기
tracks_batch = [track_ids[i: i+100] for i in range(0, len(track_ids), 100)]
audio_features = []
for i in tracks_batch:
ids = ','.join(i)
URL = "https://api.spotify.com/v1/audio-features/?ids={}".format(ids)
r = requests.get(URL, headers=headers)
raw = json.loads(r.text)
audio_features.extend(raw['audio_features'])
(3-2) Parquet화
audio_features = pd.DataFrame(audio_features)
audio_features.to_parquet('audio-features.parquet', engine='pyarrow', compression='snappy')
(3-3) S3 사용
- spotify artists 폴더
- audio-features 폴더
- dt=오늘날짜
- 여기에
audio-features.parquet(파켓 형식)으로 데이터 저장
- 여기에
- dt=오늘날짜
- audio-features 폴더
s3 = boto3.resource('s3')
object = s3.Object('spotify-artists', 'audio-features/dt={}/top-tracks.parquet'.format(dt))
data = open('audio-features.parquet', 'rb')
object.put(Body=data)
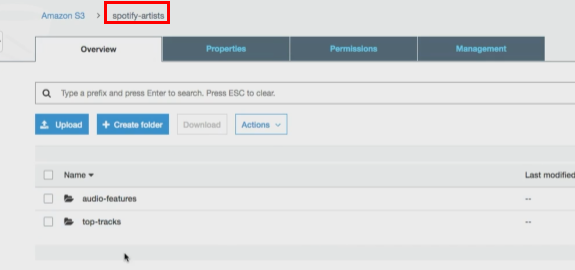
4. Result
spotify-artists라는 bucket안에, 아래와 같이 2개의 폴더가 생성된 것을 확인할 수 있다!
해당 폴더 안에는, parquet형식의 데이터가 저장되었다.
이렇게 완성된 데이터를, Spark나 Athena Presto를 통해서 어떻게 진행할 지 알아볼 것이다!