
( 참고 : Fastcampus 강의 )
[ SSD (Single Shot MultiBox Detector) ]
1. Object Detection 알고리즘들
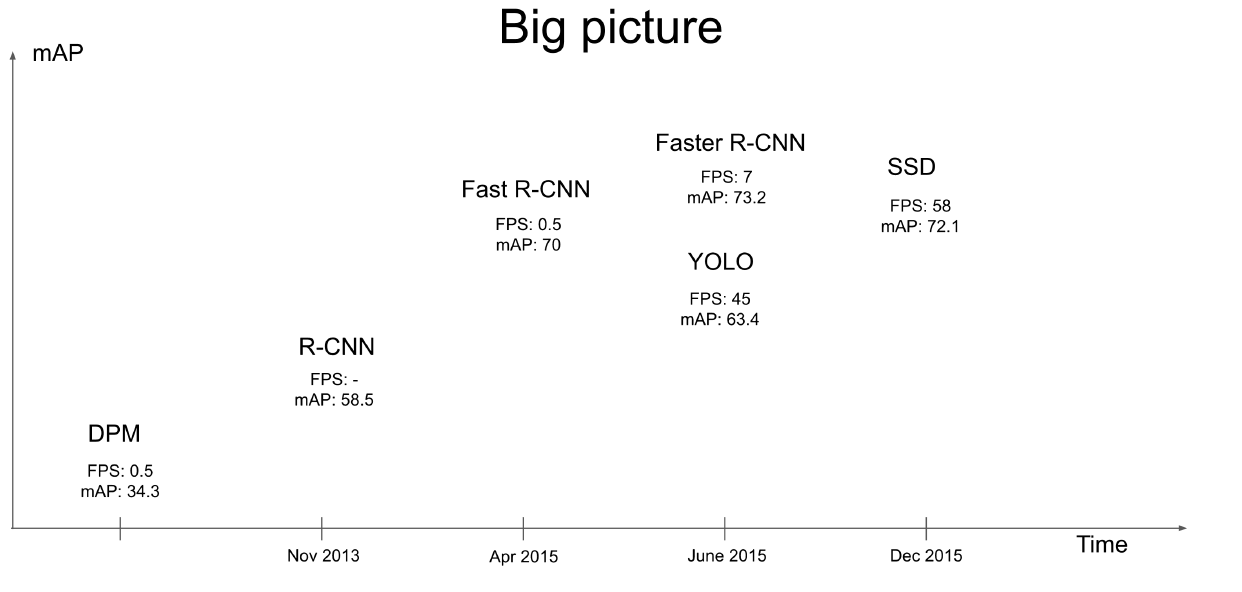
- FPS : Frame Per Second
2. SSD (Single Shot MultiBox Detector) (2016)
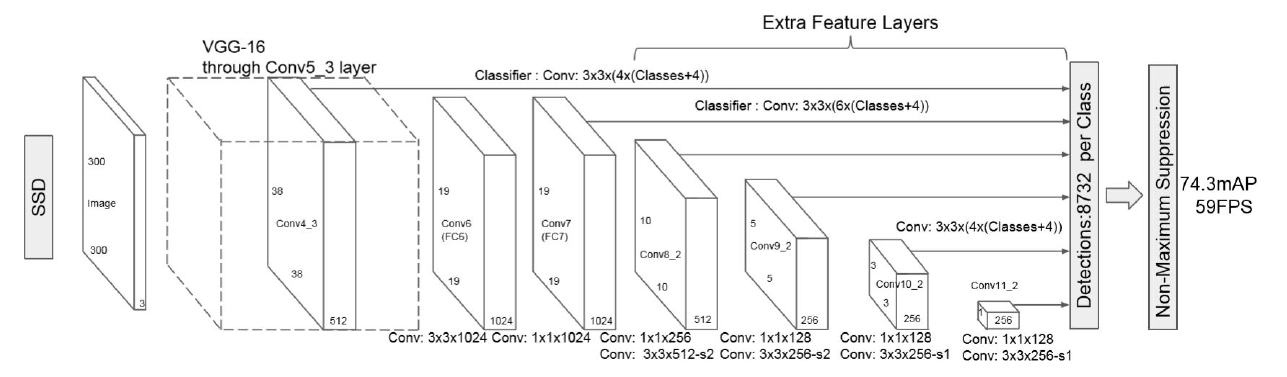
SSD = Single Shot MultiBox Detector
-
Backbone : VGG16 사용
- 중간중간에서 발생하는 각각의 feature map들이, detection하는 output layer에 모두 연결(concatenate)되어 있다.
- YOLO와 마찬가지로, Non-Maximum Suppresion 사용
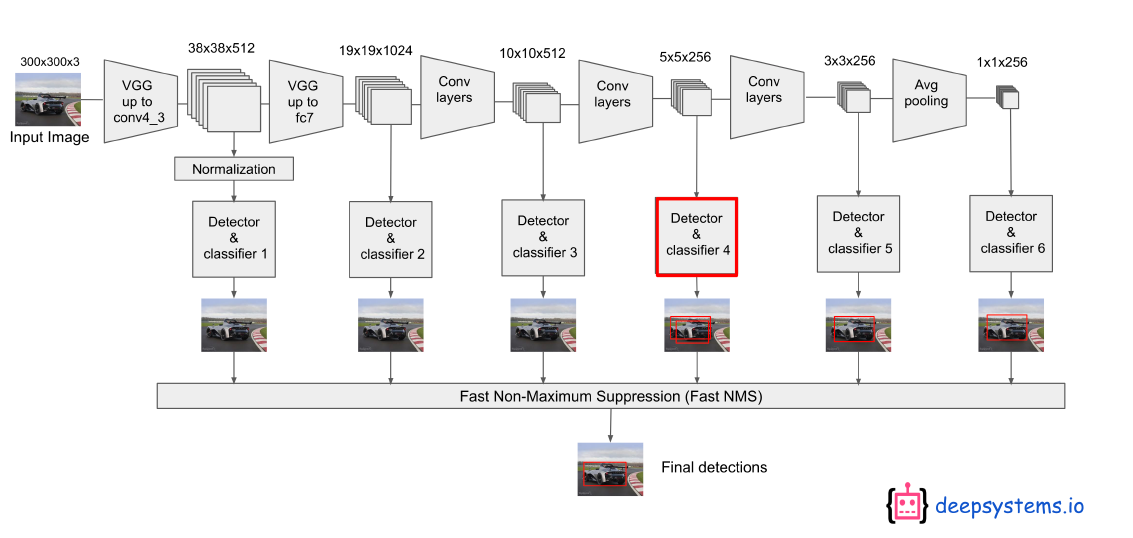
1) Multi-scale feature maps for detection
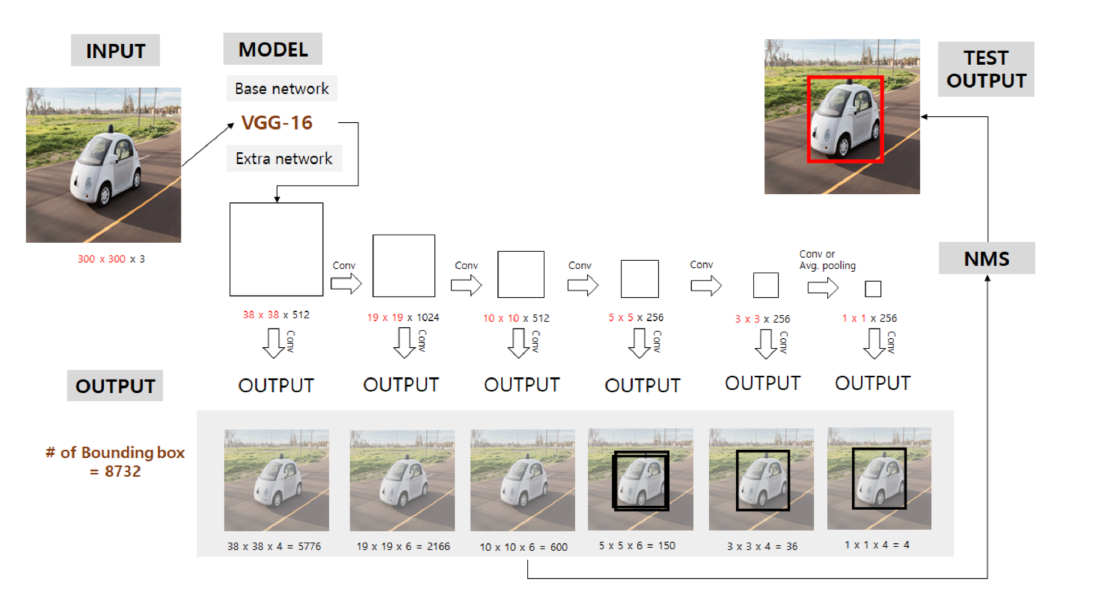
-
Layer를 지날 수록, Feature Map의 크기는 감소 \(\rightarrow\) 다양한 배율에서의 Object Detection 가능!
- (쉬운 해석) 오른쪽으로 갈 수록, ( 더 작은 H & W 이므로 ) 물체의 더 큰 영역을 잡아낸다.
- 왼쪽 : 작은 물체 포착
- 오른쪽 : 큰 물체 포착
-
어느 정도 Layer 지나서, 배율이 좀 높아지면, 그때부터는 bounding box 사용
- example) 아래 그림 참조
- 8 × 8 Feature Map에서는 작은 object인 고양이를 찾음
- 4 × 4 Feature Map에서는 큰 물체인 개를 찾음
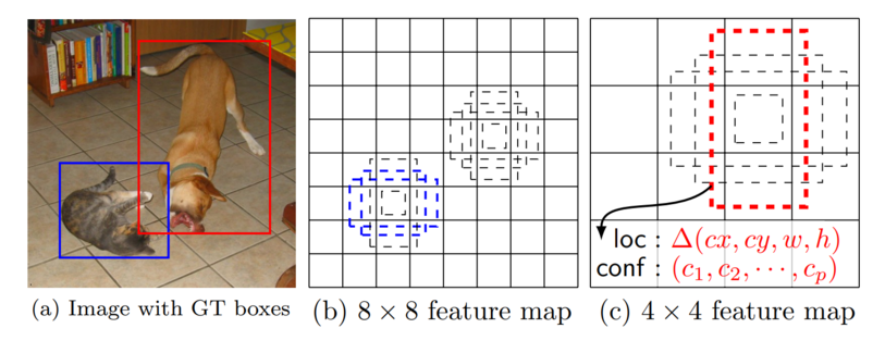
2) Default Box & Aspect Ratio
-
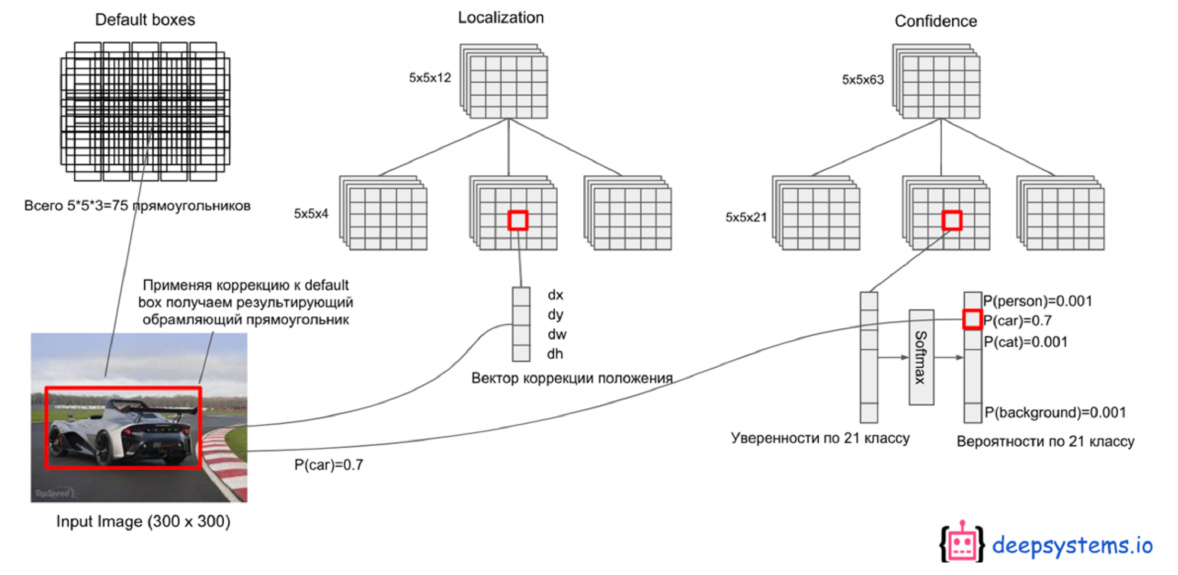
Output layer 부근의 layer들에서 생성된 feature map들에서, 각 feature map 내의 각 cell들에 대해 default box를 적용함
-
Default Box?
-
위의 image에서, 점선으로 표시된 박스와 같이,
미리 정해진 크기의 Box에 aspect ratio를 적용한 Box를 의미
-
-
각 Default Box의 위치는 고정됨
-
각 cell들은 이 Default Box를 이용하여…
- 1) Bounding Box의 offset과
- 2) 각 Class에 해당하는 Object 존재 여부에 대한 score
를 계산한다
Default Box 생성 Rule
Notation
- \(k\) : feature map의 size ( \(k \times k\) ), where \(k \in[1, m]\)
- \(a_r\) : aspect ratio
- \(w_k\) & \(h_k\) : width & height
- \(s_{min}=0.2\), \(s_{max}=0.9\)
\(s_{k}=s_{\min }+\frac{s_{\max }-s_{\min }}{m-1}(k-1)\).
- feature map의 크기가 달라짐에 따라, scaling값도 변화함을 알 수 있다
- 5가지 종류의 aspect ratio
\(\begin{array}{r} w_{k}^{a}=s_{k} \sqrt{a_{r}} \\ h_{k}^{a}=s_{k} / \sqrt{a_{r}} \end{array}\).
- width & height 계산
Aspect ratio가 1인 경우, 아래의 default box 하나가 더해진다. 해당 box의 scale은
- \(s_{k}^{\prime}=\sqrt{s_{k} s_{k+1}}\).
3) IOU (Intersection over Union)
( Jaccard Overlap이라고 부름 )
두 box(영역)의 overlapping 정도를 나타내는 (상대적인) 값
- box 1) 제안된 default box
- box 2) ground truth box
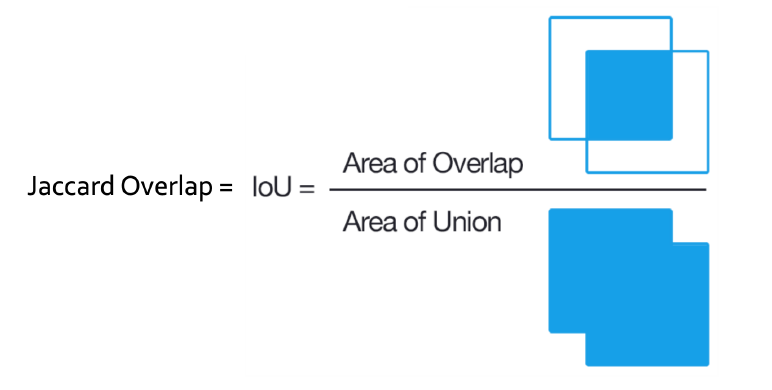
IoU값이 0.5이상이 되면, 해당 default box는 적합한 bounding box이다!
( 하나의 cell에 대해 여러 개의 bounding box가 있을 수 있음 )
3. Training Loss of SSD
Faster R-CNN과 유사하다.
\(L(x, c, l, g)=\frac{1}{N}\left(L_{\text {conf }}(x, c)+\alpha L_{l o c}(x, l, g)\right)\).
- \(N\) : matching된 default box의 개수
- \(L_{conf}\) : confidence score에 해당하는 classification loss ( cross entropy )
- \(L_{loc}\) : localization에 해당하는 regression loss ( smooth L1 loss )
4. Data Augmentation
Sample a patch
-
minimum IOU가 최소 0.1/0,3/0.5/0.7/0.9가 되도록 patch 생성
-
patch size 또한 랜덤하게 샘플
Horizontal Flip 0.5 확률
