( 참고 : Fastcampus 강의 )
[ YOLO v1 (2016) ]
1. Introduction of YOLO
[ Problem of R-CNNs ]
2-stage detector : Region Proposal & Classification이 순차적으로 이루어짐
\(\rightarrow\) 실시간성이 부족하다!
[ brief overview of YOLO ]
- (1) feature를 뽑아낸 뒤
- (2) FC Layer를 통해 한번에 region proposal & classification을 이뤄내자!
[ R-CNN vs YOLO ]
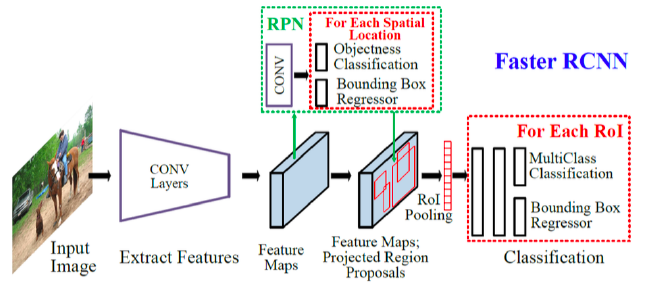
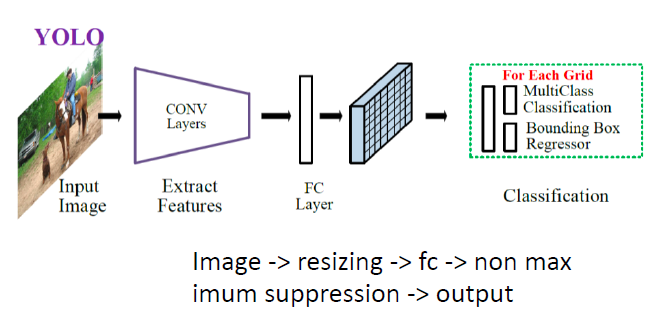
2. YOLO ( You Only Look Once )
YOLO는, 아래와 같이 단순히 보이는 구조를 가진다.
1) \(7 \times 7 \times 30\) convolution
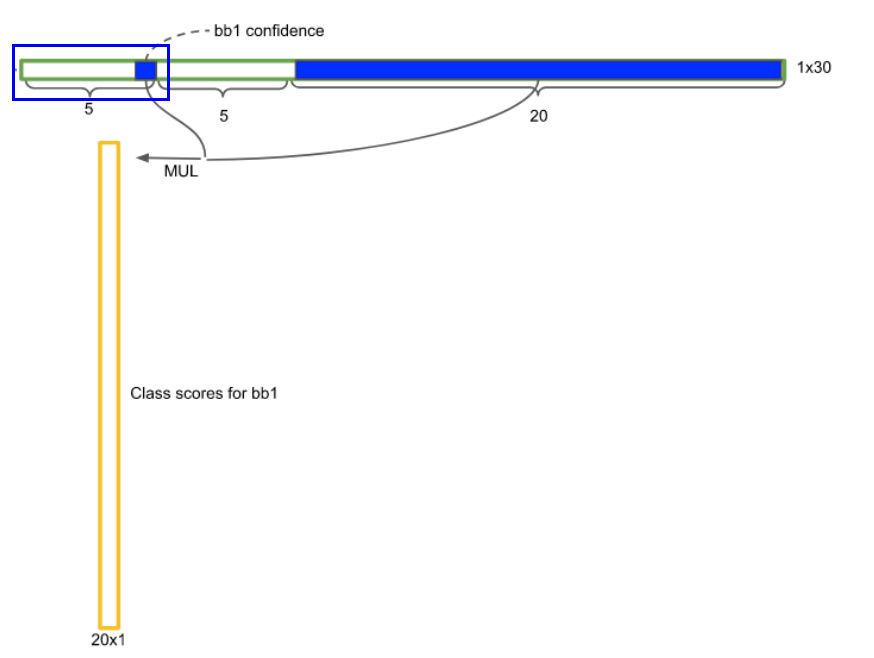
여기서 주목할 것은, 맨 마지막에 있는 \(7\times 7 \times 30\)의 Fully Connected Layer이다.
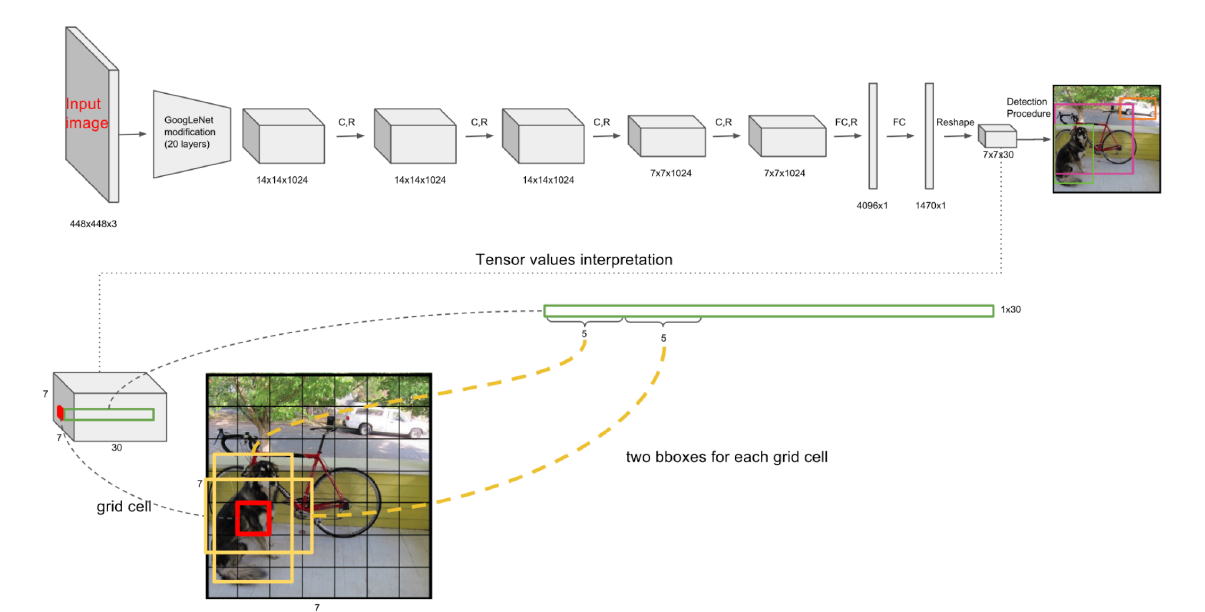
여기서 \(7 \times 7 \times 30\)의 의미를 생각해보자.
-
(1) \(7\times 7\) : 이미지를 7x7의 grid로 나누는 것을 의미한다.
( 여기서의 “이미지”는, proposal region이 아닌 하나의 통째 이미지다 )
( 각 grid를 중심으로 하는, \(k\)개의 Anchor Box를 생성한다 (여기서 \(k=2\)) )
-
(2) \(30\) = \((5 \times 2) +20\)

- \((5 \times 2)\) : 아래의 정보 5가지 x 2개의 Anchor Box
- 5가지 정보 : \(x,y,w,h,c\)
- 아래 그림의 빨간색 윤곽 사진
- \(20\) : 20가지 class에 대한 conditional class probability
- 아래 그림의 파란색 윤곽 사진
- \((5 \times 2)\) : 아래의 정보 5가지 x 2개의 Anchor Box

\(P(Class_i \mid Object) \times (P(Object) \times IOU) = P(Class_i) \times IOU\).
- \(P(Class_i \mid Object)\) : conditional class probability ( 위에서 나온 20개 class에 대한 값들 )
- \(P(Object)\) : Confidence score ( Object 포함 유무 )
- \(IOU\) : Intersect of Union ( 두 bouding box의 겹치는 영역 비중 / 두 bounding box의 합집합 )
- 여기서 두 box는, predicted box와 정답 label box이다
위의 수식을, 그림으로 나타낸 것은 아래와 같다.
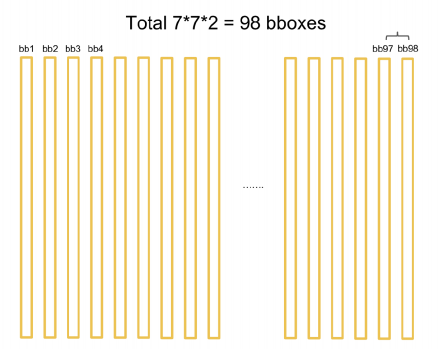
위와 같이, 모든 anchor box에 대해 할 경우, 아래와 같이 98개 (\(7 \times 7 \times 2(k)\)개)의 box가 나오게 될 것이다.
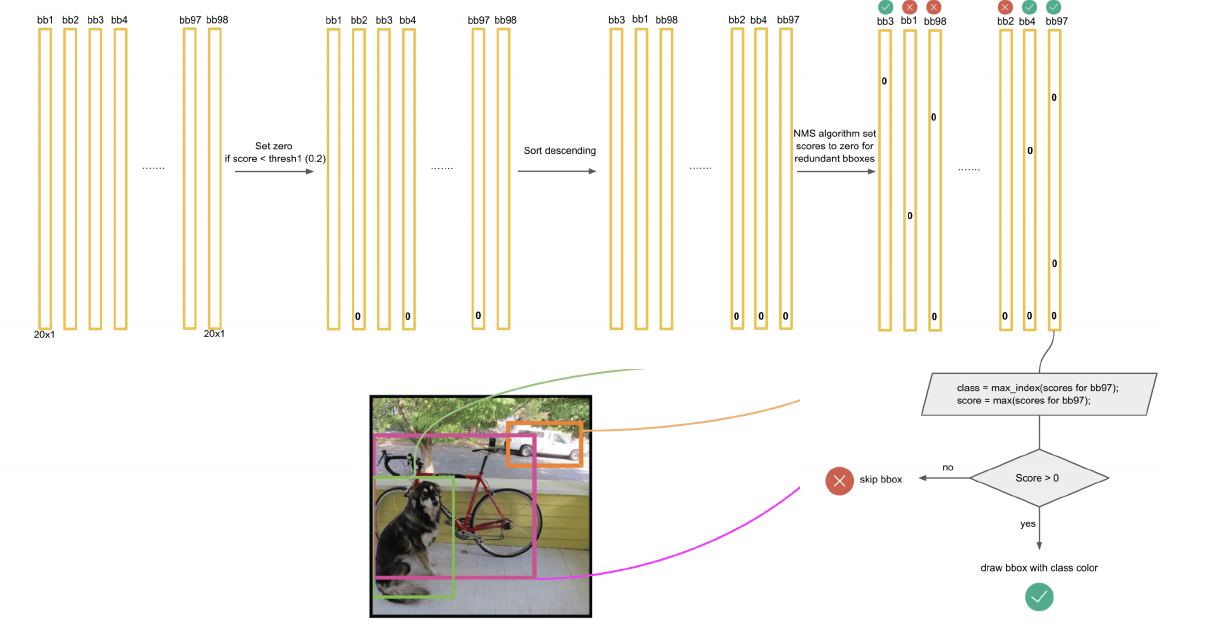
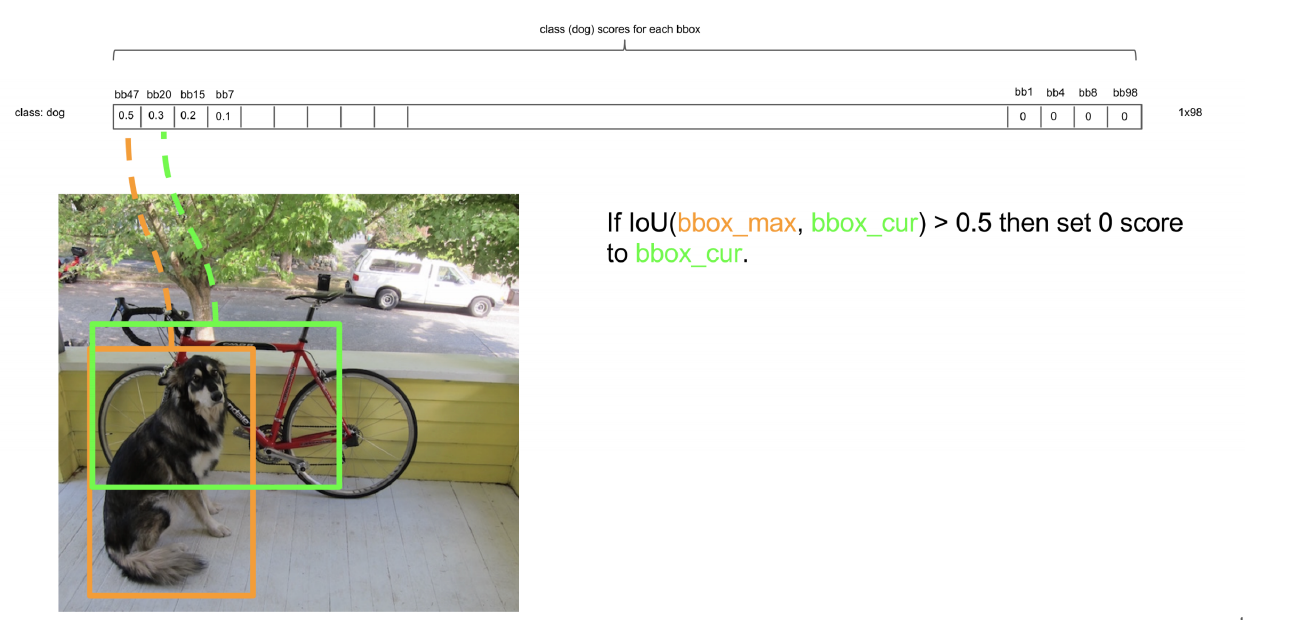
2) Non-maximal Suppression
위에서 나온 여러 개(98개)의 bounding box중,
“Object별 가장 적합한 bounding box 하나”만 남기고 다 없애는 과정을 수행한다.
그 과정은 아래와 같다.
-
step 1) 일정 threshold 이하의 score는 전부 0으로 만든다
-
step 2) sorting
-
step 3) NMS (Non-maximal Suppression)을 통해, redundant bounding box들을 제거한다
NMS의 구체적인 알고리즘을 그림으로 살펴보자면 아래와 같다.
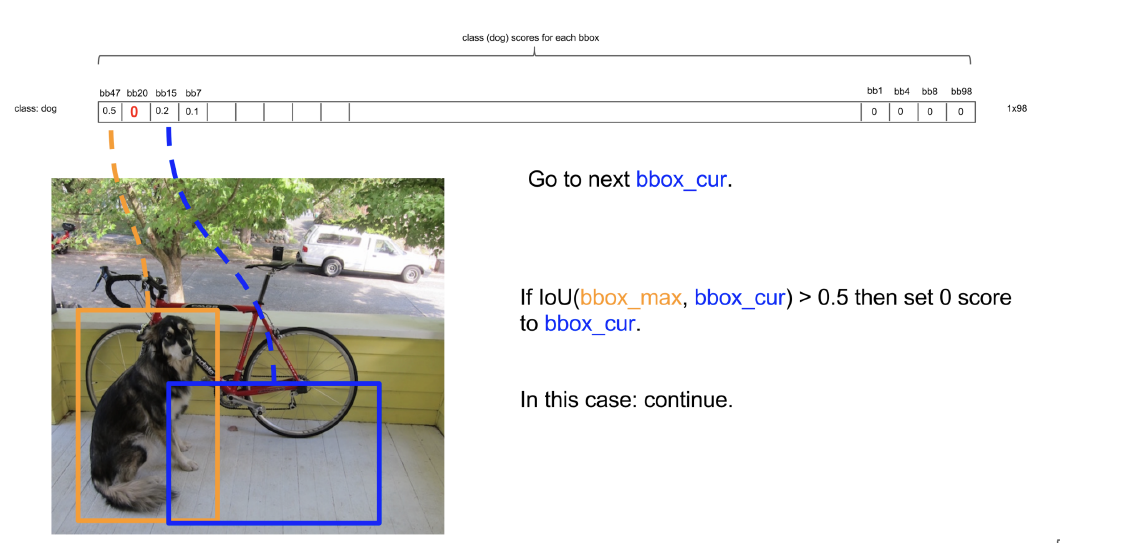
위 과정을 통해 끝까지 살아남은 bounding box의 경우, 해당 object의 물체로 인식하게 된다.
최종 Output