17. Improving Language Understanding by Generative Pre-Training (2018)
(notice) GPT-1으로 알려진 Paper!
목차
- Abstract
- Introduction
- Related Work
- Framework
- Unsupervised pre-training
- Supervised fine-tuning
- Task-specific input transformation
Abstract
Labled text : scarce!
Solve this by (1) generative pre-training of a language model on UNLABELD text
Then, do (2) discriminative fine-tuning !
-
task-aware input transformation during fine-tuning
( to achieve effective transfer, while requiring minimal changes to the model architecture )
1. Introduction
Recently…extensive use of PRE-TRAINED word embeddings!
But, challenging for 2 reasons
- 1) unclear what type of optimization objectives are most effective
- 2) no consensus on the most effective way to transfer these learned representations to the target task
This paper explores a semi-supervised approach for language understanding tasks, using…
“combination of (1) unsupervised pre-training & (2) supervised fine-tuning”
Goal : learn a universal representation that transfers with little adaptation to a wide range of tasks!
Uses Transformer as a model architecture
Evaluate on 4 tasks.
- 1) NLI ( Natural Language Inference )
- 2) QA ( Question Answering )
- 3) Semantic similarity
- 4) Text classification
2. Related Works
- semi-supervised learning for NLP
- unsupervised pre-training
- auxiliary training objectives
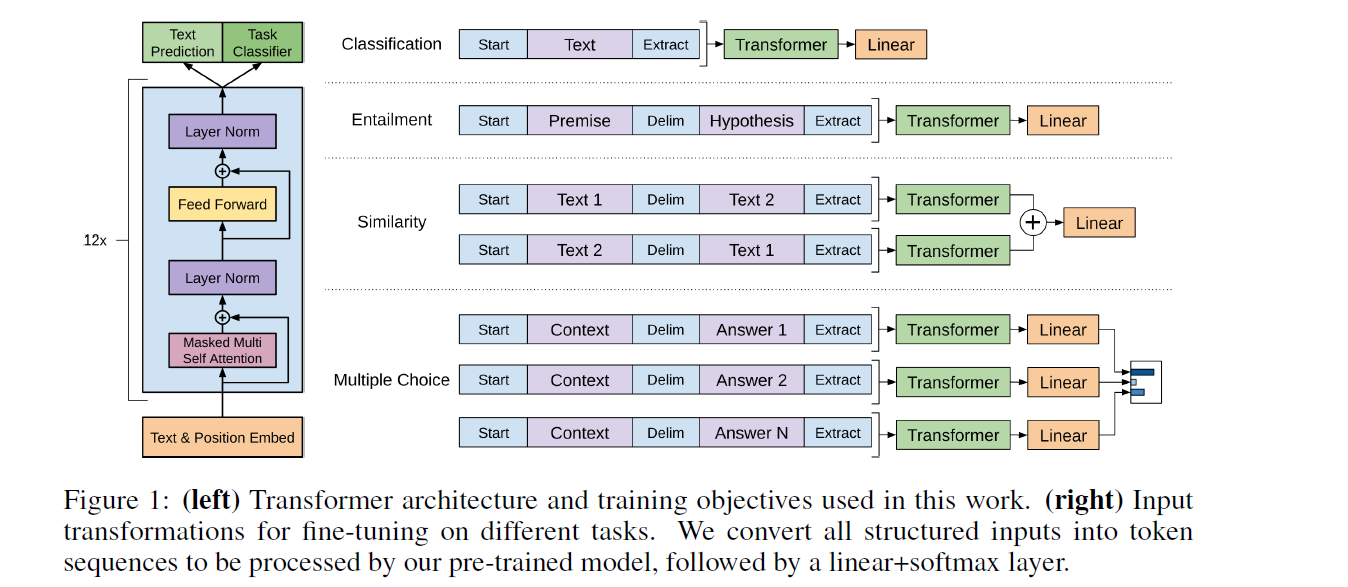
3. Framework
training consists of 2 stages
- 1) learning a high-capacity language model
- 2) fine-tuning stage
- adapt the model to a discriminative task with labeled data
3-1. Unsupervised pre-training
unsupervised corpus of tokens : \(\mathcal{U}=\left\{u_{1}, \ldots, u_{n}\right\}\)
-
maximize log likelihood : \(L_{1}(\mathcal{U})=\sum_{i} \log P\left(u_{i} \mid u_{i-k}, \ldots, u_{i-1} ; \Theta\right)\)
-
use SGD
Use Transformer decoder
- applies multi-head self-attention operation over the input context tokens
- followed by position-wide FFNN
\(\begin{aligned} h_{0} &=U W_{e}+W_{p} \\ h_{l} &=\text { transformer_block }\left(h_{l-1}\right) \forall i \in[1, n] \\ P(u) &=\operatorname{softmax}\left(h_{n} W_{e}^{T}\right) \end{aligned}\).
- \(U=\left(u_{-k}, \ldots, u_{-1}\right)\): context vector of tokens
- \(n\) : number of layers
- \(W_e\) : token embedding matrix
- \(W_p\) : position embedding matrix
3-2. Supervised fine-tuning
After 3-1, adapt the parameters to the supervised target task ( labeled dataset \(C\) )
predict \(y\) as..
- \(P\left(y \mid x^{1}, \ldots, x^{m}\right)=\operatorname{softmax}\left(h_{l}^{m} W_{y}\right)\).
- maximize \(L_{2}(\mathcal{C})=\sum_{(x, y)} \log P\left(y \mid x^{1}, \ldots, x^{m}\right)\).
Also found out that including LM as an auxiliary objective to fine-tuning helped..
- 1) improving generalization
- 2) accelerating convergence
Optimize \(L_{3}(\mathcal{C})=L_{2}(\mathcal{C})+\lambda * L_{1}(\mathcal{C})\).
3-3. Task-specific input transformation
for some tasks (ex. text classification), we can directly fine-tune our model as below.