
18. BERT ; Pre-training of Deep Bidirectional Transformers for Language Understanding (2019)
( https://seunghan96.github.io/dl/nlp/28.-nlp-BERT-%EC%9D%B4%EB%A1%A0/ 부터 먼저 읽기 )
목차
- Abstract
- Introduction
- BERT
- Pre-tranining BERT
- Fine-tuning BERT
Abstract
introduce BERT ( Bidirectional Encoder Representations from Transformer )
-
1) pre-train deep bidirectional representations from unlabeled text
( by jointly conditioning on both left & right context in all layers )
-
2) can be fine-tuned with just one additional output layer
1. Introduction
LM pretraining is hot!
2 existing strategies for applying pre-trained language representations to down-stream tasks :
-
1) feature-based
-
ex) ELMo uses task-specific architecture,
that include pre-trained representations as additional features
-
-
2) fine-tuning
-
ex) GPT introduces minimal task-specific parameters &
trained on the downstream tasks by simply fine-tuning all pre-trained parameters
-
2 approaches share the same objective function during pre-training, where they use UNI-directional LM!
This paper improve the fine-tuning based approaches by proposing BERT
Contributions
- 1) importance of bidirectional pre-training for language representations
- 2) reduce the need for many heavily-engineered task-specific architectures
- 3) advances the SOTA at for 11 NLP tasks
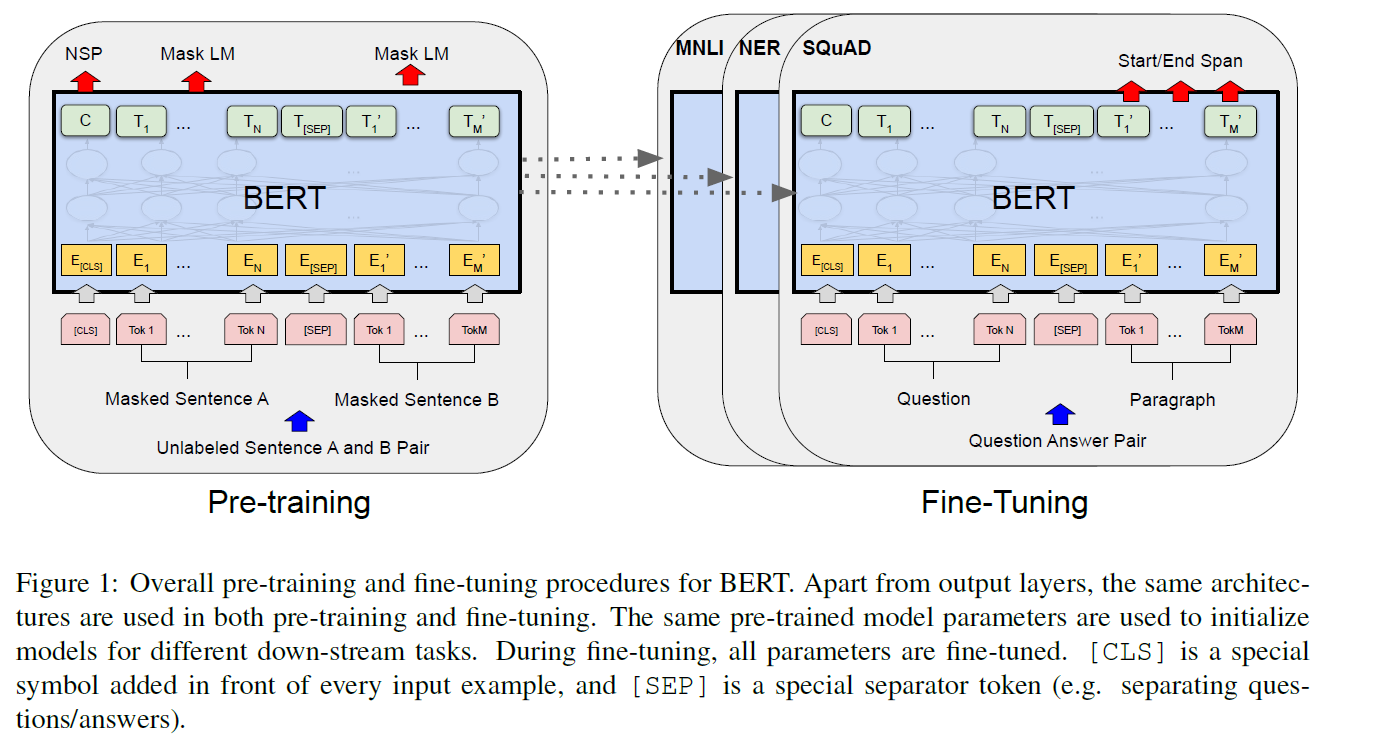
2. BERT
2 steps in this framework :
- (1) pre-training : trained on unlabeled data, over different pre-training tasks
- (2) fine-tuning : first initialized with the pre-trained parameters
- each downstream task has separate fine-tuend models
Distinctive feature of BERT : UNIFIED architecture architecture across different tasks
Model architecture
- multi-layer bidirectional Transformer
- notation
- \(L\) : number of layers ( Transformer blocks )
- \(H\) : hidden size
- \(A\) : number of self-attention heads
- type
- \(\mathbf{B E R T}_{\text {BASE }}(\mathrm{L}=12, \mathrm{H}=768, \mathrm{~A}=12,\) Total Parameters \(=110 \mathrm{M}\) )
- \(\mathbf{B E R T}_{\text {LARGE }}(\mathrm{L}=24, \mathrm{H}=1024\), \(\mathrm{A}=16\), Total Parameters \(=340 \mathrm{M}\) ).
BERT vs GPT
- BERT) uses bi-directional self-attention
- GPT) uses constrained self-attention
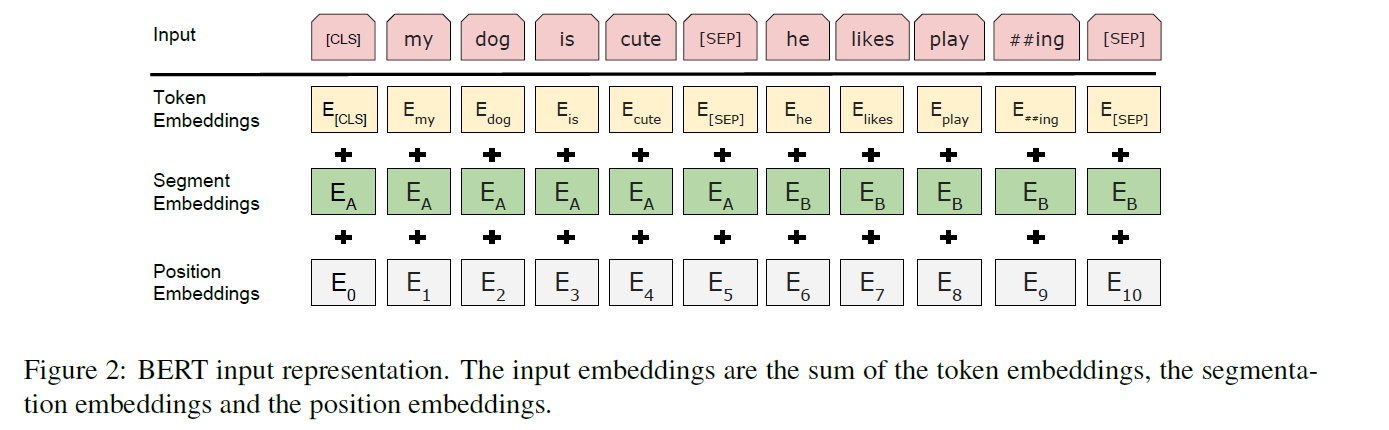
Input & Output Representations
- use WordPiece embeddings with a 30,000 token vocabulary
- ([CLS]) :first token
- ([SEP]) : separate sentences pairs
2-1. Pre-tranining Bert
Task 1) Masked LM
Task 2) Next Sentence Prediction (NSP)
2-2. Fine-tuning Bert
-
Self-attention mechanism in the Transformer allows BERT to model many downstream tasks
-
Bidirectional cross attention between two sentences!
- For each task, simply plug in the task-specific inputs & outputs into BERT & fine-tune all the parameters end-to-end!
- (compared to pre-training) fine-tuning is relatively inexpensive