
06. NLP in TF
(참고) udemy - TF Developer in 2022
Contents
- Text Vectorization
- Embedding
- Modeling a text dataset
- model 1 : Naive Bayes
- model 2 : FC
- model 3 : LSTM
- model 4 : GRU
- model 5 : biLSTM
- model 6 : 1d-Conv
- model 7 : TF Hub pretrained Feature Extractor
- Save & Load trained model
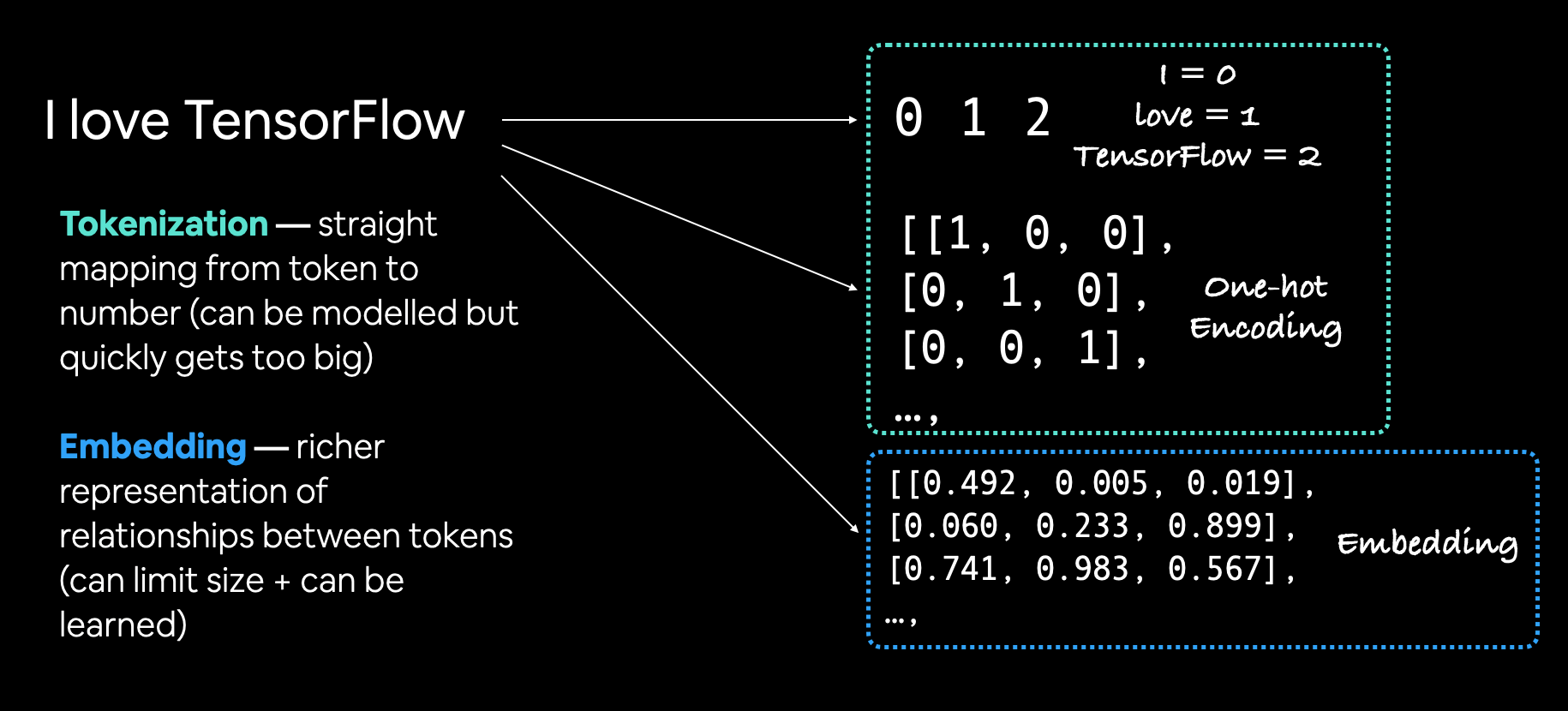
(1) Text Vectorization
with TextVectorization
Arguments
-
max_tokens standardize: default ="lower_and_strip_punctuation"- lowers text and removes all punctuation marks
split: default ="whitespace"ngrams:- ex)
ngrams=2: splits tokens into continuous sequences of 2
- ex)
output_mode: how to output tokens- ex)
"int"(integer mapping),"binary"(one-hot encoding),"count"or"tf-idf"
- ex)
output_sequence_length: length of tokenized sequence- ex)
output_sequence_length=150: all tokenized sequences will be 150 tokens long.
- ex)
pad_to_max_tokens: default =False- if
True: padded tomax_tokens
- if
import tensorflow as tf
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
max_vocab_length = 10000
max_length = 15
text_vectorizer = TextVectorization(max_tokens=max_vocab_length,
output_mode="int",
output_sequence_length=max_length)
text_vectorizer.adapt(train_sentences)
Example
sample_sentence = "There's a flood in my street!"
text_vectorizer([sample_sentence])
<tf.Tensor: shape=(1, 15), dtype=int64, numpy=
array([[264, 3, 232, 4, 13, 698, 0, 0, 0, 0, 0, 0, 0,
0, 0]])>
Unique Vocabulary Sets
words_in_vocab = text_vectorizer.get_vocabulary()
top_5_words = words_in_vocab[:5] # Top 5 FREQUENT
(2) Embedding
can be learned during training
use tf.keras.layers.Embedding layer!
-
input_dim: size of vocab ( ex. 20000 ) -
output_dim: embedding vector 차원 수 embeddings_initializer- ex) (default)
uniform - ex) pre-learned embedding
- ex) (default)
input_length: length of sequences
tf.random.set_seed(42)
from tensorflow.keras import layers
embedding = layers.Embedding(input_dim=max_vocab_length,
output_dim=128,
embeddings_initializer="uniform",
input_length=max_length,
name="embedding_1")
random_sentence = random.choice(train_sentences)
sample_embed = embedding(text_vectorizer([random_sentence]))
print(sample_embed.shape)
# (1, 15, 128)
(3) Modeling a text dataset
Types of Models
- model 1) Naive Bayes
- model 2) FC
- model 3) LSTM
- model 4) GRU
- model 5) biLSTM
- model 6) 1d-conv
- model 7) TF Hub pretrained Feature Extractor
Steps
- (1) construct a model
- (2) train the model
- (3) evaluation
- (4) make predictions
(4) model 1 : Naive Bayes
(1) construct & train the model
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
model_0 = Pipeline([
("tfidf", TfidfVectorizer()), # words ---(tfidf) ---> numbers
("clf", MultinomialNB()) # Naive Bayes Classifier
])
model_0.fit(train_sentences, train_labels)
(2) evaluation
baseline_score = model_0.score(val_sentences, val_labels)
(3) make predictions
baseline_preds = model_0.predict(val_sentences)
baseline_preds[:20]
array([1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1])
(5) model 2 : FC
(1) construct & train the model
- with Functional API
from tensorflow.keras import layers
inputs = layers.Input(shape=(1,), dtype="string") # inputs : 1d string
#-----------------------------------------------------------------#
x = text_vectorizer(inputs) # text -> number
x = embedding(x) # number -> embedding
x = layers.GlobalAveragePooling1D()(x) # lower embedding dimension
#-----------------------------------------------------------------#
outputs = layers.Dense(1, activation="sigmoid")(x)
model_1 = tf.keras.Model(inputs, outputs, name="model_1_dense")
model_1.compile(loss="binary_crossentropy",
optimizer=tf.keras.optimizers.Adam(),
metrics=["accuracy"])
model_1_history = model_1.fit(train_sentences,
train_labels,
epochs=5,
validation_data=(val_sentences, val_labels),
callbacks=[create_tensorboard_callback(dir_name=SAVE_DIR,
experiment_name="simple_dense_model")])
(2) evaluation
model_1.evaluate(val_sentences, val_labels)
(3) get embedding of ceratin word
#embedding.weights
embed_weights = model_1.get_layer("embedding_1").get_weights()[0]
(4) make predictions
- Probabilities
model_1_pred_probs = model_1.predict(val_sentences)
- Argmax
model_1_preds = tf.squeeze(tf.round(model_1_pred_probs))
10000개의 단어가 각각 128차원으로 임베딩됨
embed_weights = model_1.get_layer("embedding_1").get_weights()[0]
print(embed_weights.shape)
# (10000, 128)
(6) model 3 : LSTM

순서
- step 1) Input (text)
- step 2) Tokenize
- step 3) Embedding
- step 4) pass layers
- step 5) Output (probability)
(1) construct & train model
tf.random.set_seed(42)
from tensorflow.keras import layers
model_2_embedding = layers.Embedding(input_dim=max_vocab_length,
output_dim=128,
embeddings_initializer="uniform",
input_length=max_length,
name="embedding_2")
inputs = layers.Input(shape=(1,), dtype="string")
#------------------------------------------------------------------------------------#
x = text_vectorizer(inputs)
x = model_2_embedding(x)
x = layers.LSTM(64)(x)
x = layers.Dense(64, activation="relu")(x) # ( optional )
#------------------------------------------------------------------------------------#
outputs = layers.Dense(1, activation="sigmoid")(x)
model_2 = tf.keras.Model(inputs, outputs, name="model_2_LSTM")
model_2.compile(loss="binary_crossentropy",
optimizer=tf.keras.optimizers.Adam(),
metrics=["accuracy"])
model_2_history = model_2.fit(train_sentences,
train_labels,
epochs=5,
validation_data=(val_sentences, val_labels),
callbacks=[create_tensorboard_callback(SAVE_DIR,
"LSTM")])
(2) make predictions
model_2_pred_probs = model_2.predict(val_sentences)
model_2_preds = tf.squeeze(tf.round(model_2_pred_probs))
(7) model 4 : GRU
위에서
x = layers.LSTM(64)(x)가x = layers.GRU(64)(x)로 바뀌면 됨
(8) model 5 : biLSTM
위에서
x = layers.LSTM(64)(x)가x = layers.Bidirectional(layers.LSTM(64))(x)로 바뀌면 됨
(9) model 6 : 1d-conv
(1) construct & train model
tf.random.set_seed(42)
from tensorflow.keras import layers
model_5_embedding = layers.Embedding(input_dim=max_vocab_length,
output_dim=128,
embeddings_initializer="uniform",
input_length=max_length,
name="embedding_5")
inputs = layers.Input(shape=(1,), dtype="string")
#------------------------------------------------------------------------#
x = text_vectorizer(inputs)
x = model_5_embedding(x)
x = layers.Conv1D(filters=32, kernel_size=5, activation="relu")(x)
x = layers.GlobalMaxPool1D()(x)
x = layers.Dense(64, activation="relu")(x) # ( optional )
#------------------------------------------------------------------------#
outputs = layers.Dense(1, activation="sigmoid")(x)
model_5 = tf.keras.Model(inputs, outputs, name="model_5_Conv1D")
model_5.compile(loss="binary_crossentropy",
optimizer=tf.keras.optimizers.Adam(),
metrics=["accuracy"])
model_5_history = model_5.fit(train_sentences,
train_labels,
epochs=5,
validation_data=(val_sentences, val_labels),
callbacks=[create_tensorboard_callback(SAVE_DIR,
"Conv1D")])
(2) make predictions
model_5_pred_probs = model_5.predict(val_sentences)
model_5_preds = tf.squeeze(tf.round(model_5_pred_probs))
(10) model 7 : TF Hub pretrained Feature Extractor
will use Universal Sentence Encoder from TensorFlow Hub
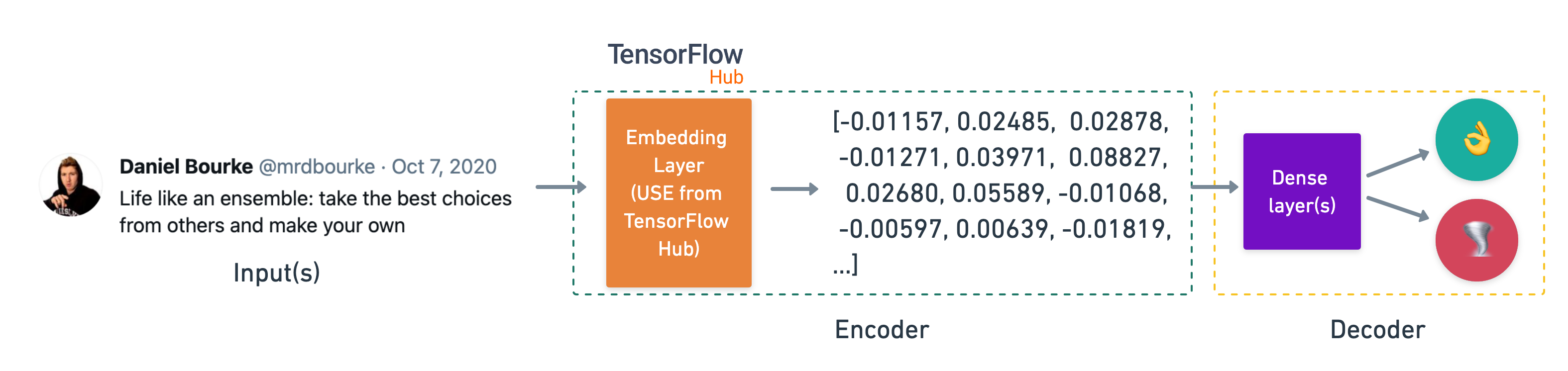
import tensorflow_hub as hub
# load Universal Sentence Encoder
embed = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4")
embed_samples = embed([sample_sentence1,sample_sentence2])
# get 1~50 dim of "sample_sentence1"
print(embed_samples[0][:50])
tf.Tensor(
[-0.01157032 0.02485909 0.02878048 -0.01271501 0.03971539 0.0882776
0.02680985 0.05589837 -0.0106873 -0.00597291 0.00639325 -0.0181952
0.00030816 0.09105889 0.05874643 -0.03180627 0.01512473 -0.05162929
0.00991365 -0.06865346 -0.04209305 0.02678981 0.03011008 0.00321067
-0.0033797 -0.04787361 0.02266722 -0.00985925 -0.04063613 -0.0129209
-0.04666385 0.056303 -0.03949255 0.00517688 0.02495828 -0.07014443
0.02871508 0.04947681 -0.00633976 -0.08960193 0.02807116 -0.00808363
-0.01360604 0.0599865 -0.10361787 -0.05195372 0.00232956 -0.02332528
-0.03758106 0.03327731], shape=(50,), dtype=float32)
Total dimension : 512
embed_samples[0].shape
# TensorShape([512])
Convert the TensorFlow Hub USE module into a Keras layer
- by using the
hub.KerasLayerclass.
# We can use this encoding layer in place of our text_vectorizer and embedding layer
sentence_encoder_layer = hub.KerasLayer("https://tfhub.dev/google/universal-sentence-encoder/4",
input_shape=[], # shape of inputs coming to our model
dtype=tf.string, # data type of inputs coming to the USE layer
trainable=False, # keep the pretrained weights (we'll create a feature extractor)
name="USE")
(1) Build model ( with Sequential API )
model_6 = tf.keras.Sequential([
sentence_encoder_layer,
layers.Dense(64, activation="relu"),
layers.Dense(1, activation="sigmoid")],
name="model_6_USE")
(2) Complie & Train Model
model_6.compile(loss="binary_crossentropy",
optimizer=tf.keras.optimizers.Adam(),
metrics=["accuracy"])
model_6_history = model_6.fit(train_sentences,
train_labels,
epochs=5,
validation_data=(val_sentences, val_labels),
callbacks=[create_tensorboard_callback(SAVE_DIR,
"tf_hub_sentence_encoder")])
(3) make predictions
model_6_pred_probs = model_6.predict(val_sentences)
model_6_preds = tf.squeeze(tf.round(model_6_pred_probs))
(11) Save & Load trained model
a) h5 format
- weight만 저장
- custom_objects를 통해 구조를 가져와야
model_6.save("model_6.h5")
loaded_model_6 = tf.keras.models.load_model("model_6.h5",
custom_objects={"KerasLayer": hub.KerasLayer})
b) SavedModel format
- weight & 구조 모두 저장
model_6.save("model_6_SavedModel_format")
loaded_model_6_SavedModel = tf.keras.models.load_model("model_6_SavedModel_format")