[Paper Review] 10. Conditional GAN
Contents
- Abstract
- Introduction
- Related work
- Multi-modal Learning for Image labeling
- Conditional Adversarial Nets
- GAN
- CGAN
- Experimental Results
- Unimodal ( data : MNIST )
- Multimodal ( data : Flickr )
0. Abstract
conditional version of GAN
- condition : by simply feeding data \(y\)
- give condition to both G & D
experiment
- (1) generate MNIST digits, conditioned on class labels (0~9)
- (2) learn a multi-modal model
- (3) application to image tagging
1. Introduction
unconditioned GAN : no control on modes of data being generated
conditioned GAN : additional information is possible!
- ex) class labels, some part of data for impaiting like, data from different modality
2 set of experiemtn
- (1) MNIST digit data …. conditioned on class labels
- (2) miR Flickr 25,000 dataset …. for multi-modal learning
2. Related work
2-1. Multi-modal Learning for Image labeling
challenges in DL
1) accomodating an extremely large number of predicted output categories 2) focus on learning one-to-one mapping
- same image … ㅡmany different tags can exists
solution
- leverage additional information ( from other modalities )
- use conditional probabilistic generative model
3. Conditional Adversarial Nets
3-1. GAN
Two-player min-max game
- \(\min _{G} \max _{D} V(D, G)=\mathbb{E}_{\boldsymbol{x} \sim p_{\text {data }}(\boldsymbol{x})}[\log D(\boldsymbol{x})]+\mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})}[\log (1-D(G(\boldsymbol{z})))]\).
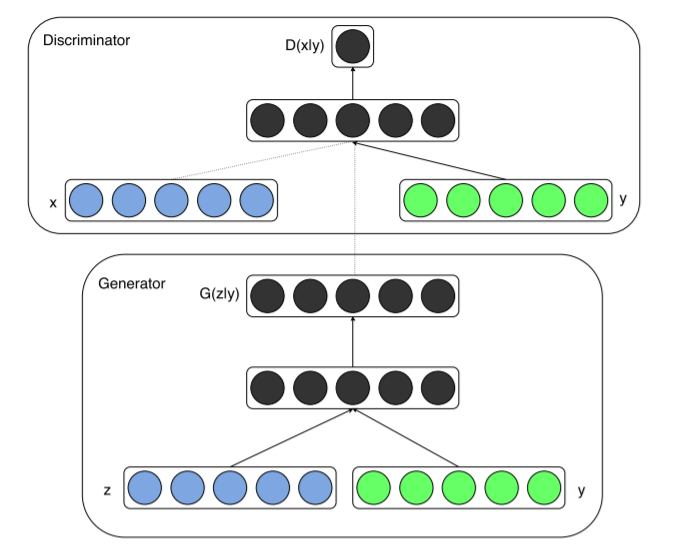
3-2. CGAN
conditioned on extra info \(y\)
( \(y\) can be any kind of auxiliary information )
- ex) class labels, data from other modalities
feedn information both to G & D
Generator
- input : noise \(p_{\boldsymbol{z}}(\boldsymbol{z})\) & \(y\) are combined
Discriminator
- input ; \(x\) & \(y\)
Objective Function
- \(\min _{G} \max _{D} V(D, G)=\mathbb{E}_{\boldsymbol{x} \sim p_{\text {data }}(\boldsymbol{x})}[\log D(\boldsymbol{x} \mid \boldsymbol{y})]+\mathbb{E}_{\boldsymbol{z} \sim p_{z}(\boldsymbol{z})}[\log (1-D(G(\boldsymbol{z} \mid \boldsymbol{y})))]\).
4. Experimental Results
4-1. Unimodal ( data : MNIST )
condition on class labels (0~9)

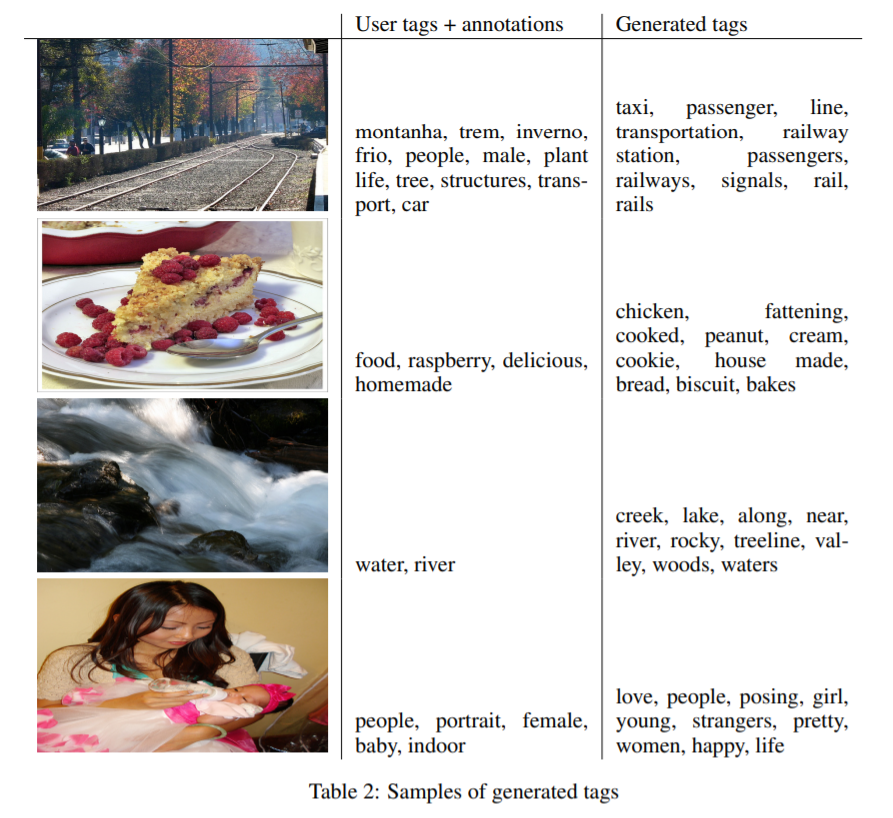
4-2. Multimodal ( data : Flickr )
[ Flickr ]
-
rich source of labeled data, in form if “images” & ‘UGM(user-generated metadata0’
- UGM ex) user–tags
-
UGM : different from image labelling, in that..
- more descriptive
- semantically much closer to how humans decribe images with natural language
- different users may use different vocabs
\(\rightarrow\) Conceptual word embeddings can be very useful
Automated tagging of Images with multi-label predictions
-
via CGAN, generate (multi-modal) distn of tag-vectors, conditional on image features
- [1. Image Features …. Conv Net ]
- pretrain using ImageNet dataset
- output of last FC layer ; 4096 units = image representations
- [2. Word Representation …. Language model ]
- gatehr corpus ( user tag + titles + descriptions ) from YFCC100m dataset
- train skip-gram model
-
keep both (1) Conv Net & (2) LM fixed, while training GAN
- for evaluation
- generate 100 samples per image
- find top 20 closest word ( via cosine similarity )
- select top 10 most common words, among 100 samples