
Word2vec Parameter Learning Explained
word2vec는 이산형인 word를 연속형인 vector로 표현하는 대표적인 방법이다.
CBOW(continuous bag-of-word)와 skip-gram이 word2vec의 대표적인 모델이다.
1. CBOW (Continous Bag-of-Word)
1.1 One-word context
하나의 context word로 하나의 target word를 예측하는 모델이다.
모델의 구조를 들여다보면 다음과 같다.

INPUT
- one-hot encoding된 하나의 context word
- dimension : 1xV ( V : 총 단어의 개수 )
HIDDEN LAYER ( W ) 1) W(vxn)
- weight between input & hidden
- dimension : VxN
(수식1)
2) W’(nxv)
- weight between hidden & output
- dimension : NxV
- predict되는 단어의 score을 반환한다
(수식2)
OUTPUT
- hidden layer에서 출력되는 score를 softmax 함수를 통해 각 단어로 예측할 확률을 반환한다
(수식3)
- 위 식에, 수식1 & 수식2를 대입하면 다음과 같이 정리할 수 있다
(수식4)
OBJECTIVE FUNCTION
(수식4)를 최대화하는 것이다
- 수식 5,6,7
1.2 Multi-word context
위의 1.1 One-word context에서, input이 하나의 context가 아니라 여러 개의 context word라는 점 외에 동일하다.
input context words의 평균 벡터를 인풋으로 받는다.
- 수식 17, 18
모델의 구조는 다음과 같이 표현될 수 있다.

OBJECTIVE FUNCTION
- 다음의 loss function을 최소화하는 것이다
- 수식 19,20,21
2. Skip-Gram Model
CBOW의 반대라고 보면 된다. 모델의 구조를 들여다보면 다음과 같다
이번에는 반대로, input으로 target word가 들어가고, output으로 context word가 들어가게 된다. 그 외의 사항은 동일하다
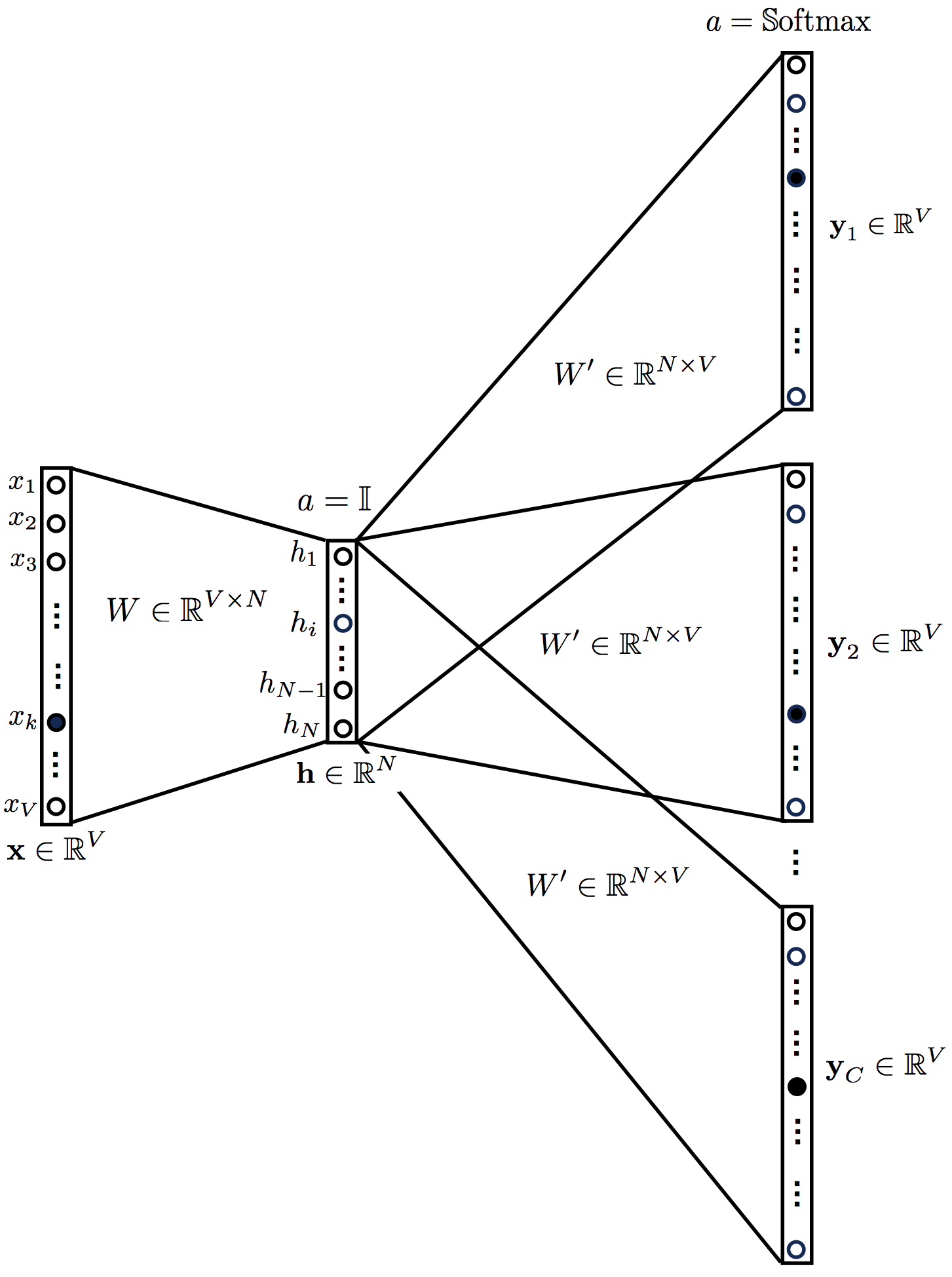
OUTPUT LAYER
- CBOW는 예측하는 대상이 하나의 단어이기 때문에 한개의 multinomial distribution이 output으로 출력되지만, Skip-Gram같은 경우에는 여러 개의 단어이기 때문에 C개의 multinomial distribution을 출력한다.
- 수식 25
OBJECTIVE FUNCTION
- 다음의 loss function을 최소화하는 것이다
- 수식 27,28,29