Grad-CAM : Visual Explanations from Deep Networks via Gradient-based Localization
Contents
- Abstract
- Introduction
- Related Work
- Approach
0. Abstract
Grad-CAM ( Gradient-weighted Class Activation Mapping )을 제안
-
Visual Explanation for decisions
-
gradient of “target concept” ( ex. “강아지” )을 사용
-
마지막 conv layer를 통과함으로써, coarse localization map을 생성함
( 중요한 지역 highlight )
-
applicable to variety of CNN model-families
Guided Grad-CAM : Grad-CAM을 fine-grained visualization과 combine
1. Introduction
deep learning의 한계 :
-
lack of decomposability into “intuitive” & “understandable” components
\(\rightarrow\) hard to interpret!
따라서, 우리는 TRANSPARENT한 model을 만들 수 있어야 한다
( transparent 모델 = 왜 그러한 prediction을 냈는지에 대해 알고 있는 모델 )
주로 accuracy & simplicity/interpretability 사이의 trade-off가 있다.
CAM (Class Activation Mapping)
-
identify discriminative regions used by a restricted class
-
trades off model complexity&performance for transparency
Grad-CAM
- 위의 CAM에서 발생하는 trade-off 문제를 피한다
- generalization of CAM
- 더 broader range of CNN model families에 적용 가능
- 1) CNN with FC layers ( ex. VGG )
- 2) CNN used for structured outputs ( ex. captioning )
- 3) CNN used in tasks with multi-modal inputs ( ex. VQA )
Good Visual Explanation이란?
- (a) class-discriminative : 이미지 내에서 물체를 잘 구분할 수 있어야
- (b) high-resolution : 고해상도 ( fine grained detail )
Example
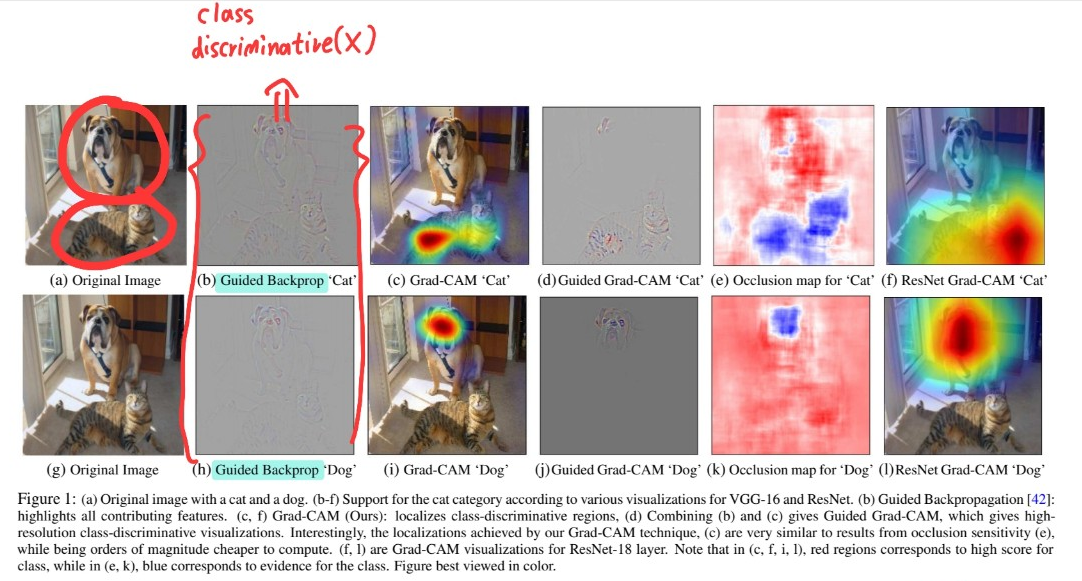
요약
-
Guided Back-propagation & Deconvolution (pixel-space gradient visualization) :
- (a) class-discriminative : BAD
- (b) high-resolution : GOOD
-
CAM, Grad-CAM
- (a) class-discriminative : GOOD
- (b) high-resolution : SOSO
-
위 둘의 장점을 합치자!
pixel-space gradient visualization + Grad-CAM
Contribution
-
Grad-CAM을 제안함
( class-discriminative localization technique )
-
apply Grad-CAM to existing top-performing classification / captioning / VQA
-
visualize ResNets
2. Related Work
Visualizing CNN
-
important pixel 찾아내기
( = have most impact on prediction’s score )
-
ex) partial derivatives of predicted class scores w.r.t pixel intensities
-
하지만 이러한 방법들은 NOT class-discriminative
Weakly supervised localization
-
풀어야 하는 task = localize objects in images, using only WHOLE image class labels
-
ex) CAM
-
특징) replace FC layer with CNN layers + Global pooling
-
단점) require feature maps to directly precede softmax layers
( \(\therefore\) 특정한 형태의 CNN architecture에만 적용 가능 )
-
Proposal : Grad-CAM
- new way of combining feature maps
- using the gradient signal
-
that does not require any modification in network architecture
- (Fully Convolutional Architecture의) Grad-CAM = 그냥 CAM
3. Approach
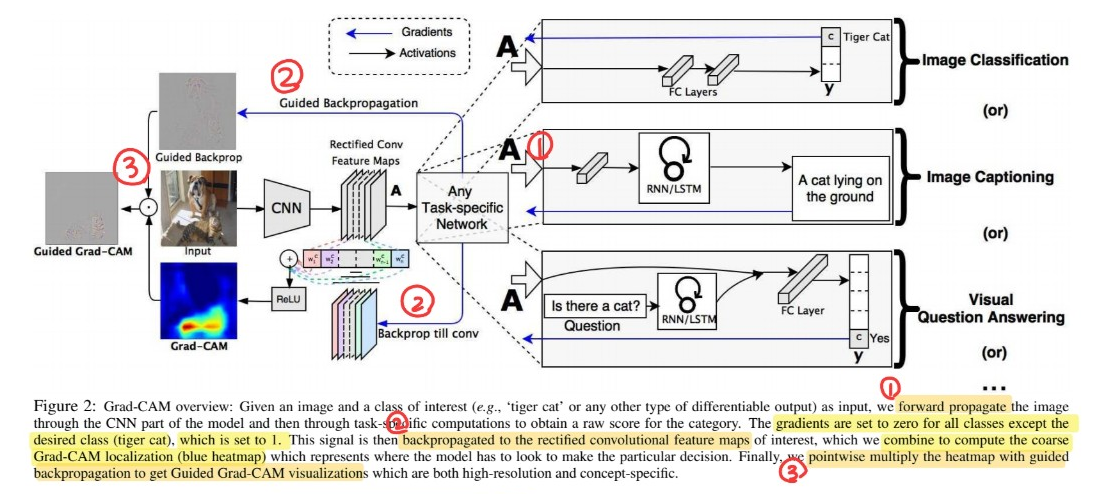
Grad-CAM은 gradient 정보를 이용한다! ( CNN의 마지막 conv layer를 타고 흐르는 gradient )
\(\rightarrow\) to understand the importance of each neuron for decision
작동 원리
Grad-CAM uses the GRADIENT information flowing into the LAST conv layer of the CNN,
to understand the IMPORTANCE of each neuron for a decision of interest
Class-discriminative localization map : \(L_{\text {Grad-CAM }}^{c} \in \mathbb{R}^{u \times v}\)
-
step 1) gradient of the score for class \(c\) ( = \(y^c\) ), w.r.t feature maps \(A^{k}\)를 계산한다
( 즉, \(\frac{\partial y^{c}}{\partial A^{k}}\) 를 계산한다 )
-
step 2) step 1에서 구한 gradient는 global-average pooled되어서 neuron importance weight를 계산한다
( \(\alpha_{k}^{c}=\overbrace{\frac{1}{Z} \sum_{i} \sum_{j}}^{\text {global average pooling }} \underbrace{\frac{\partial y^{c}}{\partial A_{i j}^{k}}}_{\text {gradients via backprop }}\) )
- \(\alpha_{k}^{c}\) : partial linearization of DNN from \(A\)
-
step 3) \(L_{\text {Grad-CAM }}^{c}\) 구하기
( \(L_{\mathrm{Grad}-\mathrm{CAM}}^{c}=\operatorname{Re} L U \underbrace{\left(\sum_{k} \alpha_{k}^{c} A^{k}\right)}_{\text {linear combination }}\) )
Grad-CAM as a generalization to CAM
CAM 복습
-
image classification을 위한 localization map을 생성
-
global average pooling 후, directly softmax로 직행!
-
feature map : \(\operatorname{map} A^{k}\)
-
score 계산 ( by Global average pooling & Linear transformation )
\(S^{c}=\sum_{k} \underbrace{w_{k}^{c}}_{\text {class feature weights }} \overbrace{\frac{1}{Z} \sum_{i} \sum_{j}}^{\text {global average pooling }} \underbrace{A_{i j}^{k}}_{\text {feature map }}\).
-
이를 다르게 표현하면,
\(S^{c}=\frac{1}{Z} \sum_{i} \sum_{j} \underbrace{\sum_{k} w_{k}^{c} A_{i j}^{k}}_{L_{\mathrm{CAM}}^{c}}\).
when \(\alpha_k^c=w_k^c\) \(\rightarrow\) Grad-CAM is a strict generalization of CAM
Guided Grad-CAM
Grad-CAM이 class discriminative하고, relevant image를 잘 localize하지만…
lack ability to show fine-grained importance
그러기 위해, fuse Guided Back propoagation & Grad-CAM visualization via point-wise multiplication
Algorithm