Towards Automatic Concept-based Explanations
Contents
- Abstract
- Introduction
- Concept-based Explanation Desiderata
- Methods
- ACE ( Automated Concept-based Explanation )
- Automated concept-based explanations “step-by-step”
- Algorithm 도식화
0. Abstract
Interpretability (해석 가능성)은 매우 중요하다!
자주 사용되는 방법은 “feature importance”를 계산하는 것이다
( = 객별 input에 대해, 중요한 feature 찾아내기 )
이 논문에선, Concept-based explanation을 제안한다!
( = human-understandable concept )
propose ACE to automatically extract visual concepts!
1. Introduction
“feature-based explanation”의 단점
- 단점 1) vulnerability to simple shifts in the input
- 단점 2) susceptibility to human confirmation biases
- 단점 3) do not increase human understanding
위의 문제점들로 인해, focus on providing information in HIGH-LEVEL HUMAN “CONCEPTS”
- feature, pixel (X)
- concept (O) … 인간에게 이해 가능한 컨셉이어야!
Contribution
-
identify higher-level concepts ( which are meaningful to humans )
- 그러기 위한 ACE ( Automated Concept-based Explanation ) 알고리즘을 제안한다
- 작동 원리 : aggregate related local image segments across diverse data
2. Concept-based Explanation Desiderata
ML 모델이 갖춰야할 바람직한 속성들 ( desired properties )
- 1) Meaningfulness : 의미가 있어야 한다
- ex) (45,23,234) 번째 pixel이 중요하다 (X)
- ex) “강아지의 두 귀”가 중요하다 (O)
- 2) Coherency : 같은 컨셉 = 일관성 있어야!
- ex) “마음 편안한 색상” (X)
- ex) “검은색/흰색 줄무늬” (O)
- 3) Importance : 해당 컨셉의 유무가 “true prediction”에 있어서 중요해야
- ex) “왼쪽 팔 소매가 찌그러졌다”의 여부 (X)
- ex) “네 발이 “달린 물체인지 (O)
3. Methods
Explanation algorithm은 3가지의 구성 요소 (components)를 가진다.
- trained classification MODEL
- set of TEST DATA points
- IMPORTANCE COMPUTATION procedure
3-1) ACE ( Automated Concept-based Explanation )
ACE 알고리즘의 핵심 특징
- global explanation method
- explains an entire class in a trained classifier
- without the need for human supervision
3-2) Automated concept-based explanations “step-by-step”
ACE 알고리즘의 작동 원리
- (input) trained classifier & set of image of a class
- (중간 과정) extract concepts in the class
- (output) each concept’s importance
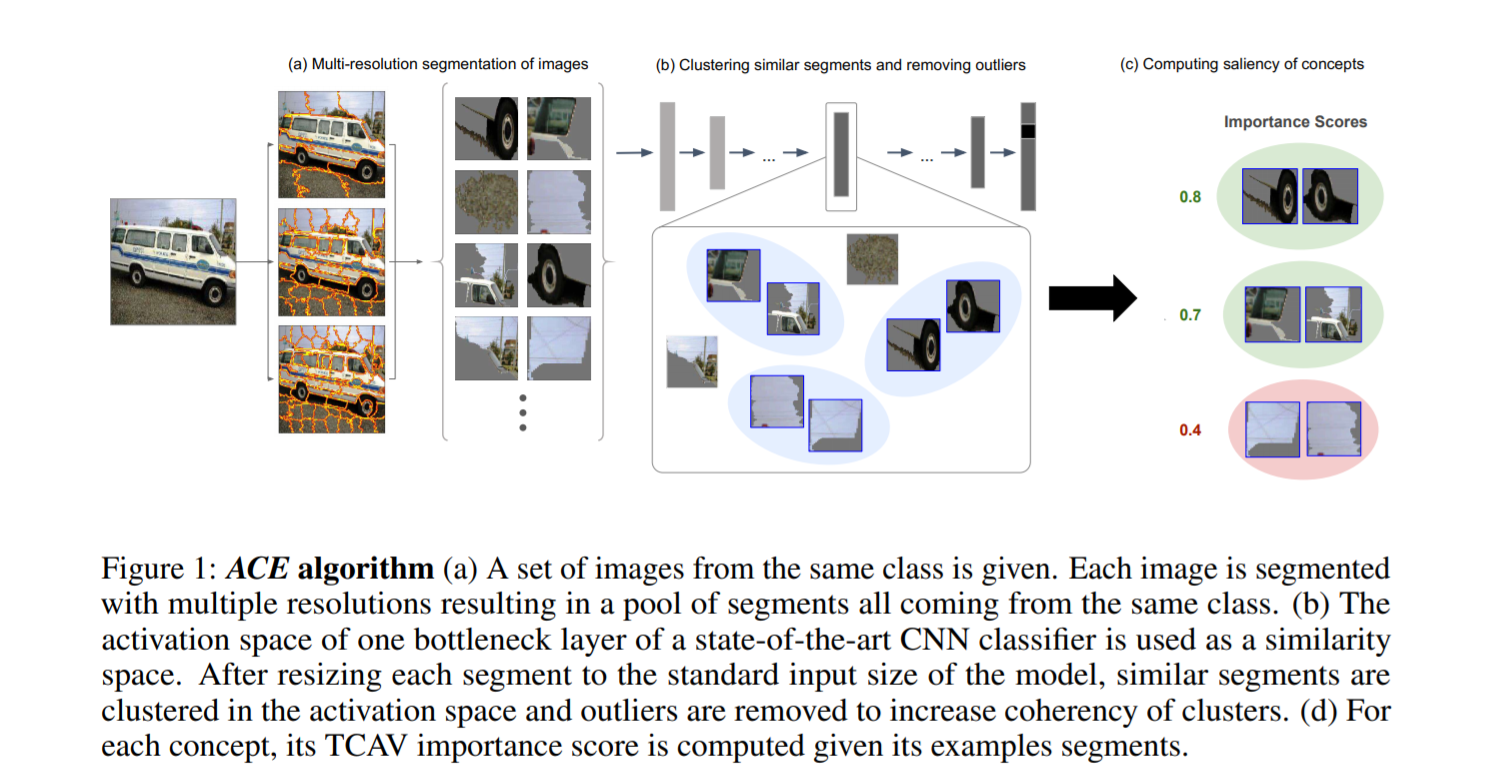
[Step 1] Extract Concepts of all Classes
-
segmentation of image
-
each image is segmented with multiple resolutions
-
논문에서는 3 different levels of resolutions
( 각각 texture / object parts / objects를 포착하기 위해 )
[Step 2] Group similar segments
- similar하다 = concept이 같다
- segment들 간의 similarity를 계산하기 위해 CNN + euclidean distance 사용
- aspect ratio 무관하게 크기 동일하게 resize해줌
[Step 3] Return important concepts
- TCAV 사용 ( https://seunghan96.github.io/inte/study/study-(interpretable)(paper-3)Interpretability-Beyond-Feature-Atribution-;-Quantitative-Testing-with-Concept-Activation-Vectors-(TCAV)/ 참고하기 )
3-3) Algorithm 도식화