
( reference : Machine Learning Data Lifecycle in Production )
Validating Data
[1] Detecting Data Issues
Outline
- Data Issues : drift & skew
- data & concept drift
- schema & distribution skew
- Detecting Data Issues
Drift & Skew
Drift : change over time
- Data drift
- change in statistical properties of features
- Concept drift
- change in statistical properties of labels
- model/performance may decay due to those drifts!
Skew : difference between 2 static versions
- ex) training & serving dataset
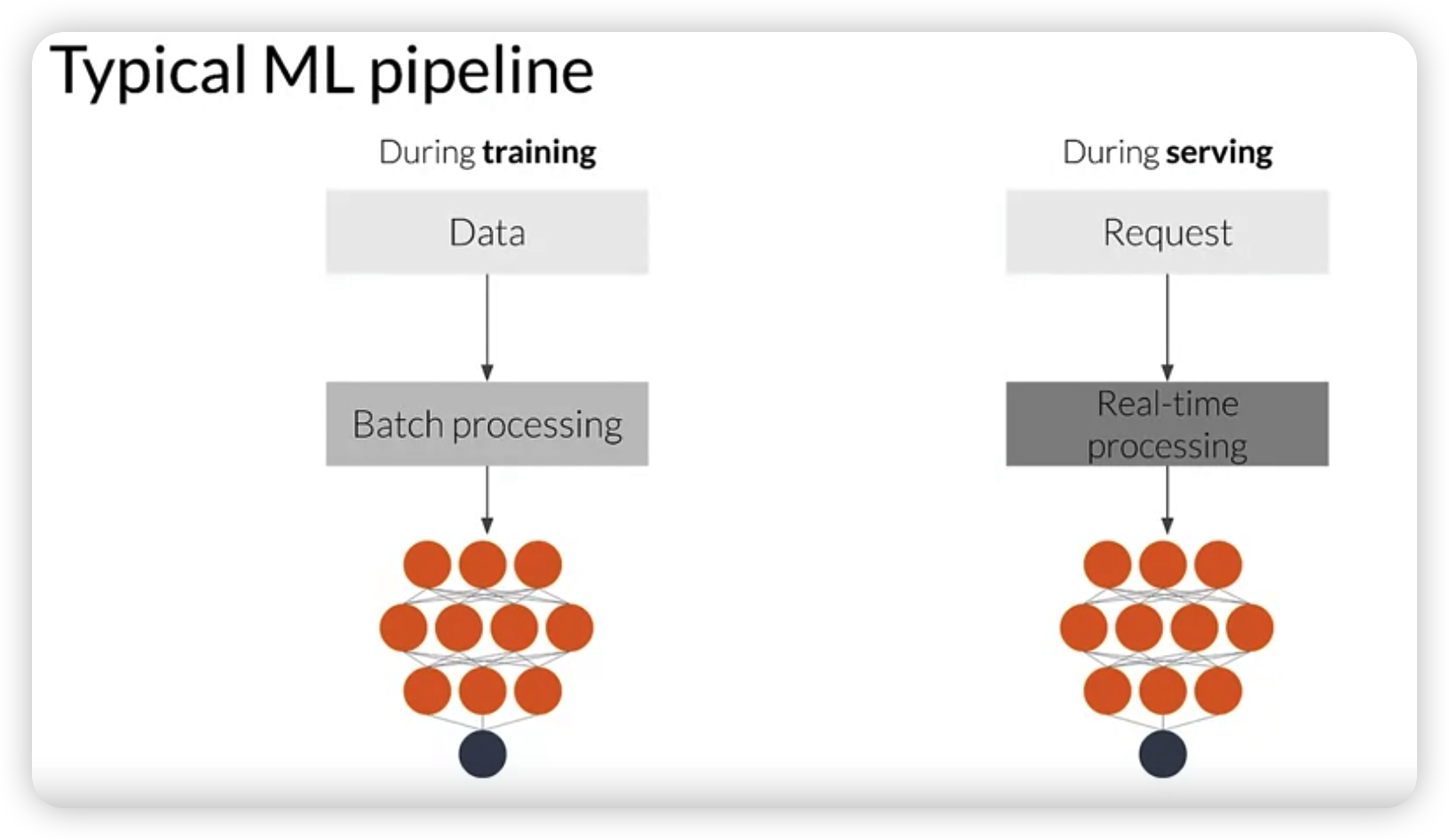
Detecting data issues
Detect …
- (1) Schema skew
- (2) Distribution skew
-> requires continuous evaluation
Schema skew
- Training data’s schema & Serving data’s schema are different
Distribution skew
- dataset / covariate / concepth shift

Skew detection workflow
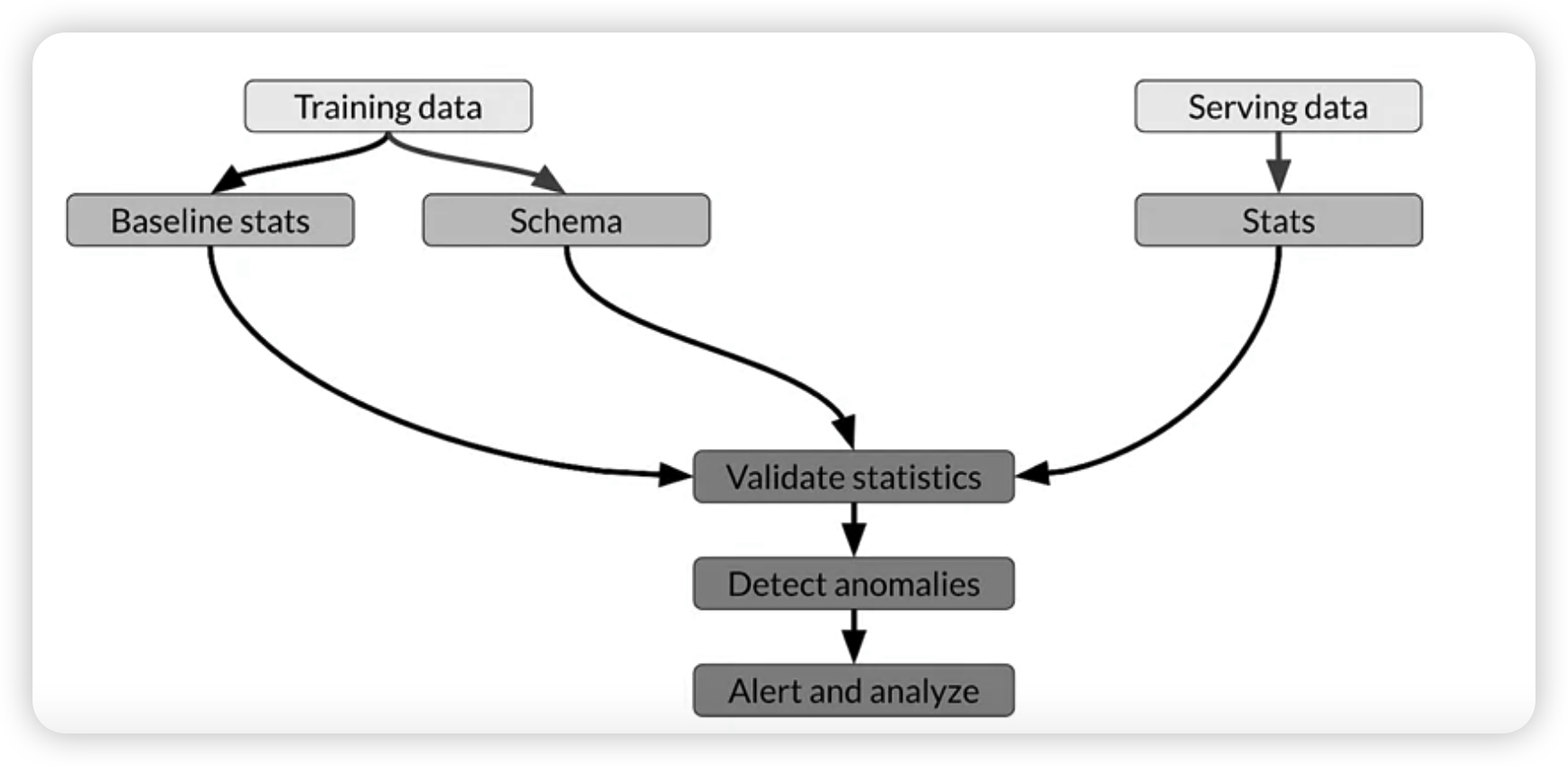
- when significant changes, trigger an alert!
[2] TFDV ( TF Data Validation )
Purpose : understand / validate / monitor ML data at scale
Capabilities of TFDV
- generate data statistics ( + visualization )
- infers data schema & validity check
- detect training-serving skew
Skew detection
(1) Schema skew :
training & serving data have differnent schema
- ex) int != float
(2) Feature skew :
training & serving data have different feature values
- ex) transformation is applied to only one
(3) Distribution skew :
training & serving data have different distribution
- ex) different data sources
- ex) change in trend/seasonality
[3] Summary
- Traditional ML modeling vs Production ML System
- Responsible Data Collection ( for fair production ML )
- Process Feedback & Human Labeling
- Detect Data Issues
https://blog.tensorflow.org/2018/09/introducing-tensorflow-data-validation.html