
( reference : Machine Learning Data Lifecycle in Production )
Feature Engineering
[1] Introduction to Processing
Outline
- Getting the most of our data
- Feature Engineering (FE) process
- FE in typical ML pipeline
- Getting the most of our data
- make data useful for training a model
- ex) normaliation, standardization
- increase predictive quality
- ex) useful feature for prediction
- dimension reduction
- lower computational cost
- Feature Engineering (FE) process
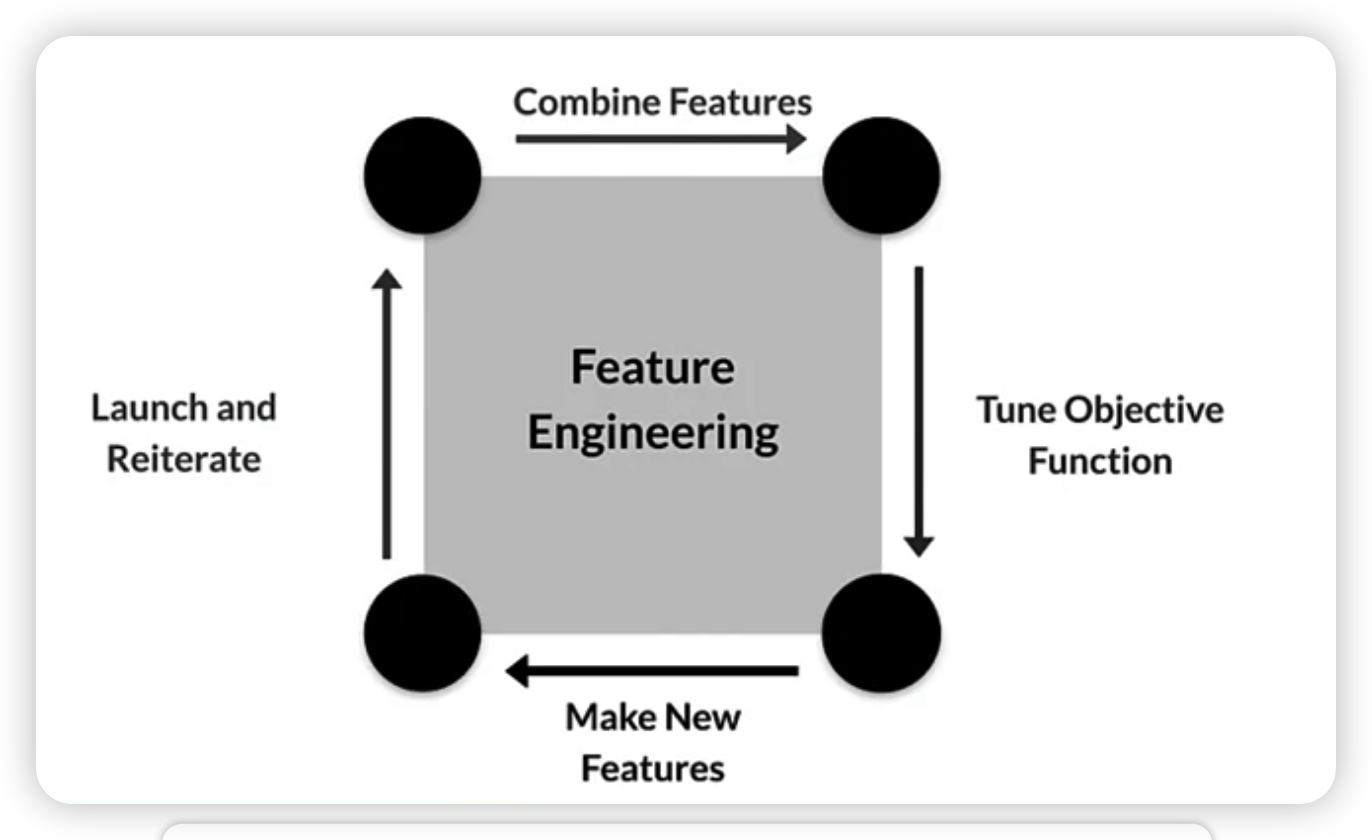
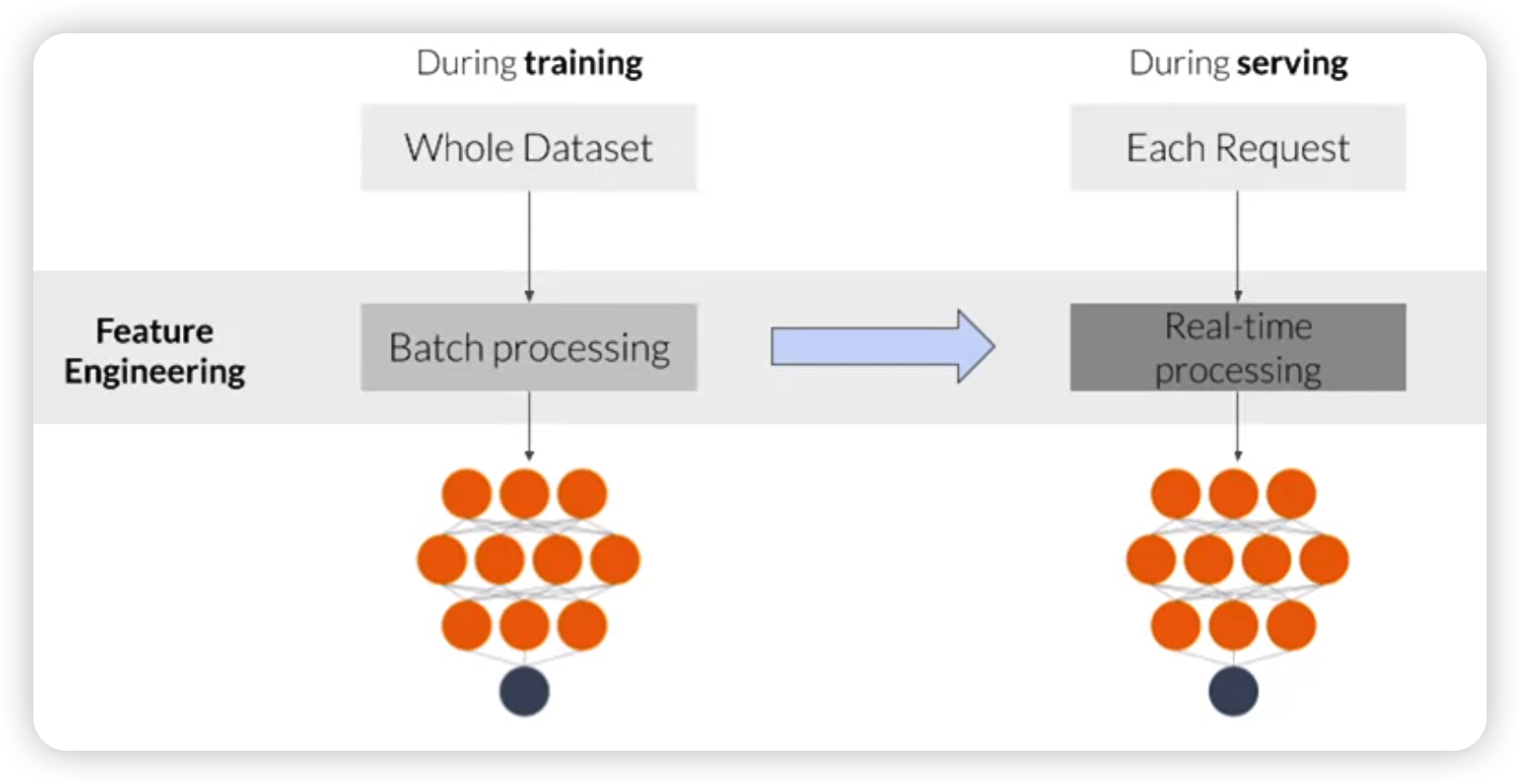
- FE in typical ML pipeline
- training : BATCH
- serving : REAL-TIME
Summary
-
FE is difficult & time consuming, but VERY IMPORTANT
-
Squeeze the most of our data!
$\rightarrow$ higher model performance
-
LOW feature dimension, HIGH predictive information
$\rightarrow$ Lower computational cost
-
FE during training $\rightarrow$ also during serving
[2] Preprocessing Operations
Outline
- Main preprocessing operations
- Mapping raw data $\rightarrow$ feature
- Mapping numeric / categorical values
- Empirical knowledge of data
Data preprocessing
= transforming raw data into clean & training-ready dataset
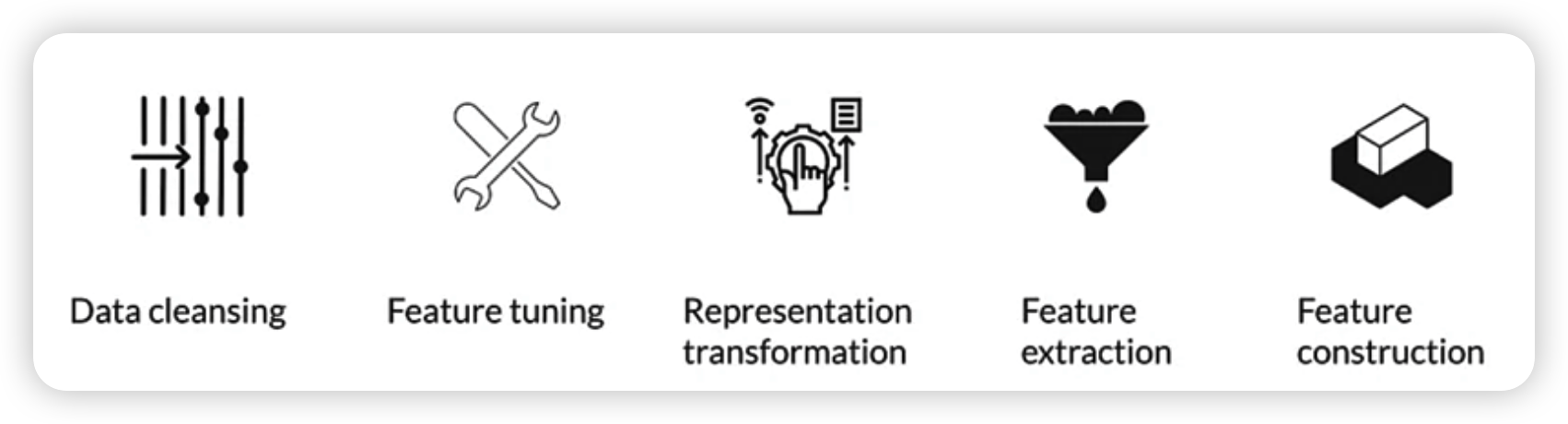
1. Main preprocessing operations
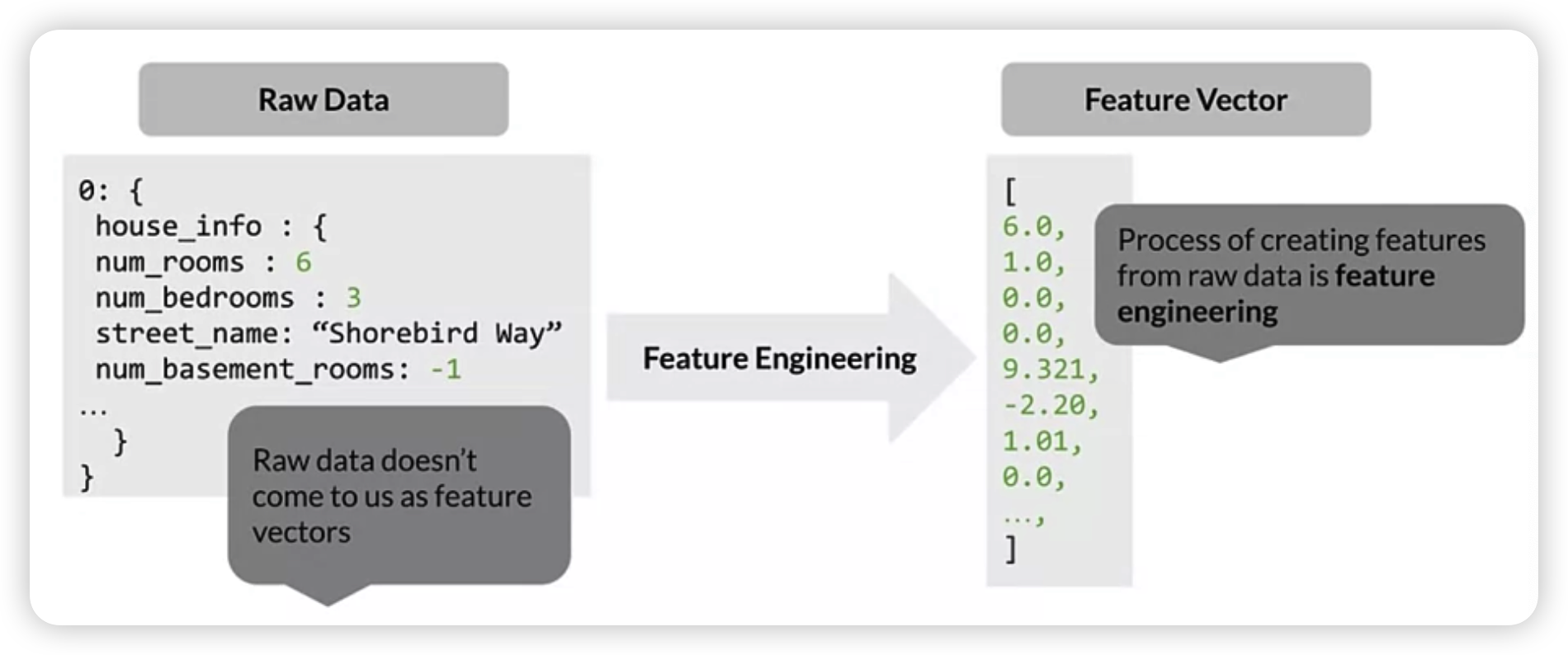
2. Mapping raw data $\rightarrow$ feature
-
raw data는 직접적으로 모델의 인풋으로 사용될 수 없다.
따라서, feature vector로 변경을 해줘야 한다
3. Mapping categorical values
-
categorical value는 수치형이 아니므로, 모델의 인풋으로 사용될 수 없다.
따라서, 원핫인코딩 등과 같은 방법으로 변형해줘야한다.
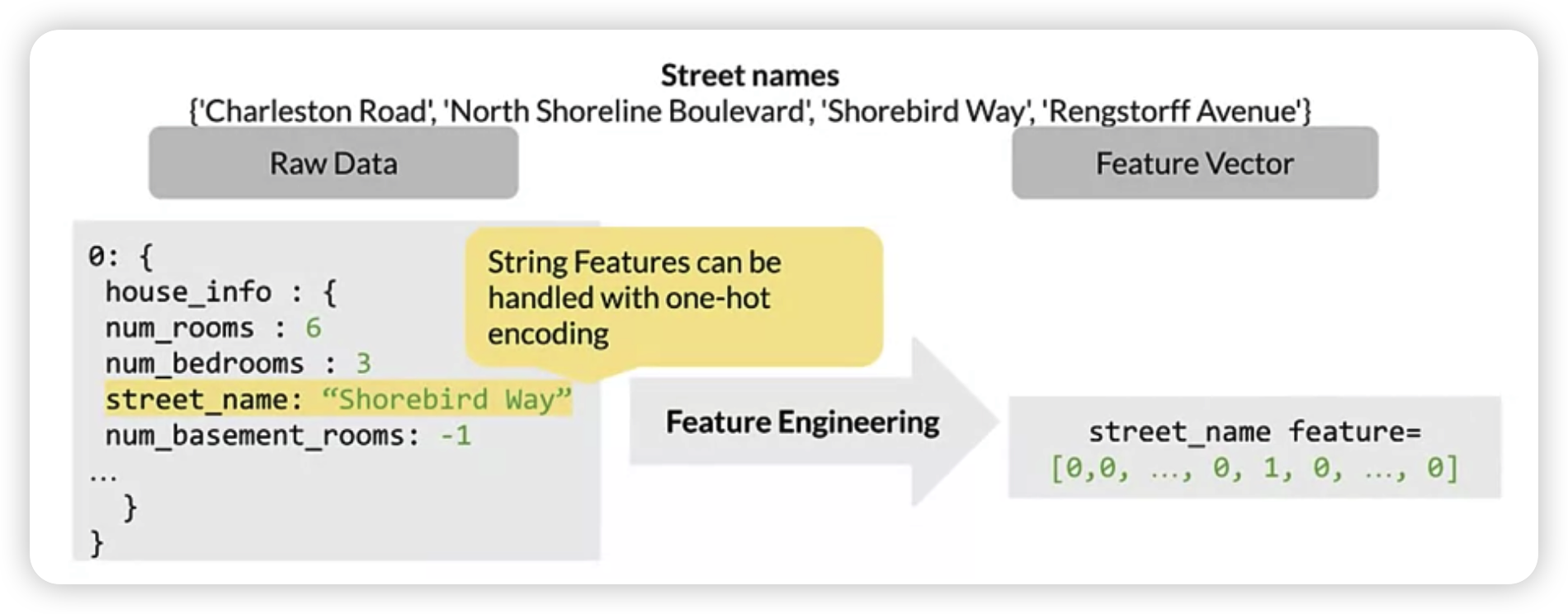
ex) categorical vocabulary
- 참고 : https://www.tensorflow.org/api_docs/python/tf/feature_column
vocab_list = ['kitchenware', 'electronics', 'sports']
vocab_file = 'product_class.txt'
vocab_feature_column = tf.feature_column.categorical_column_with_vocabulary_list(
key = 'kitchenware',
vocabulary_list = vocab_list
)
vocab_feature_column = tf.feature_column.categorical_column_with_vocabulary_file(
key = feature_name,
vocabulary_file = vocab_file,
vocabulary_size = 3
)
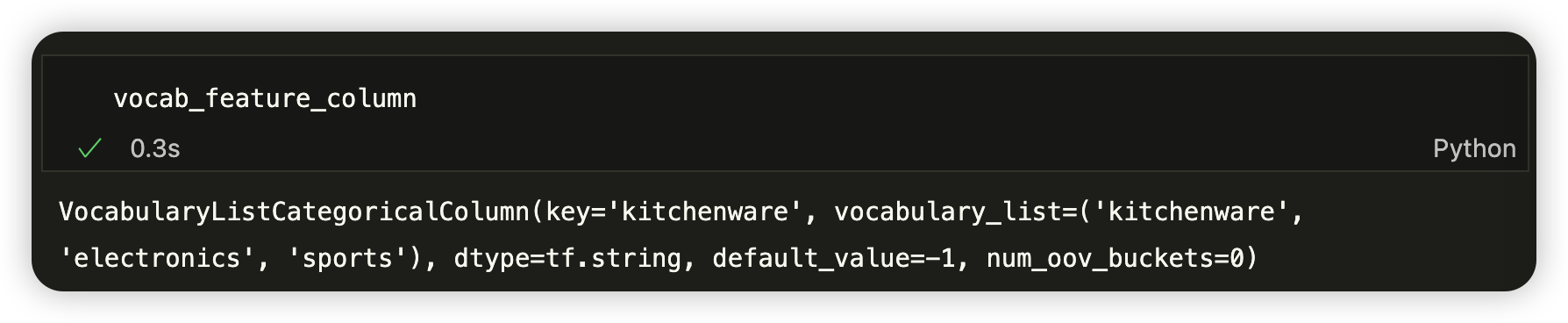
4. Empirical knowledge of data
Text
- stemming, lemmatization, TF-IDF, n-grams, embedding lookup table
Images
- clipping, resizing, cropping, blur, …
[3] Feature Engineering Techniques
Outline
- Feature Scaling
- Normalization & Standardization
- Bucketizing & Binning
- Other techniques
[ types of Feature Engineering techniques ]
- Numerical Range : scaling, normalizing, standardizing
- Grouping : bucketizing, bag of words (bow)
1. Feature Scaling
Scaling = converting values into prescribed range
- ex) img pixel (0,256) $\rightarrow$ (-1, 1)
Advantages
- faster convergence of NN
- do away with NaN erros
- for each feature, the model learns the right weights
2. Normalization & Standardization
Normalization
-
min-max scaling : into range of (0,1)
-
standardization (z-score) : into Standard Normal distribution
3. Bucketizing & Binning
convert into groups & one-hot encoding
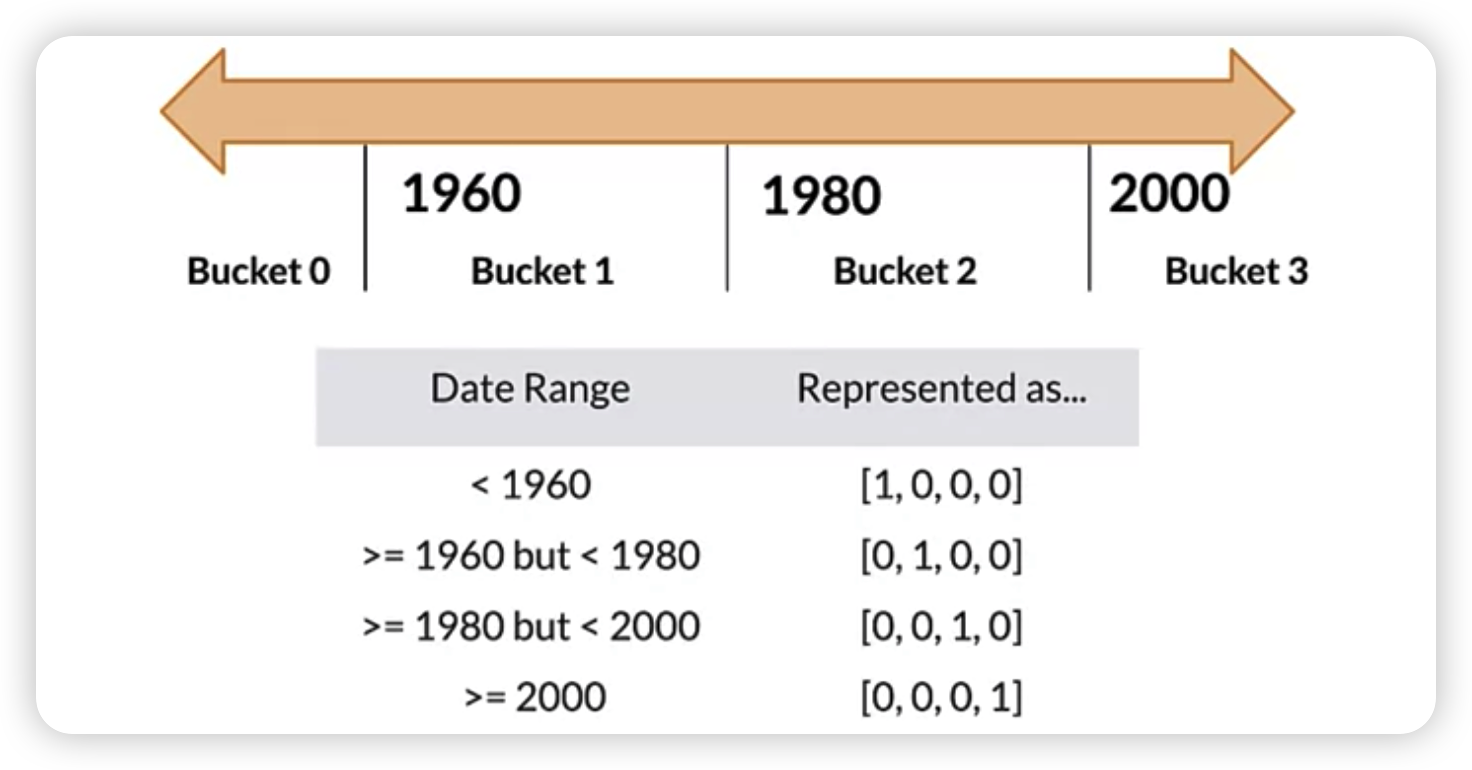
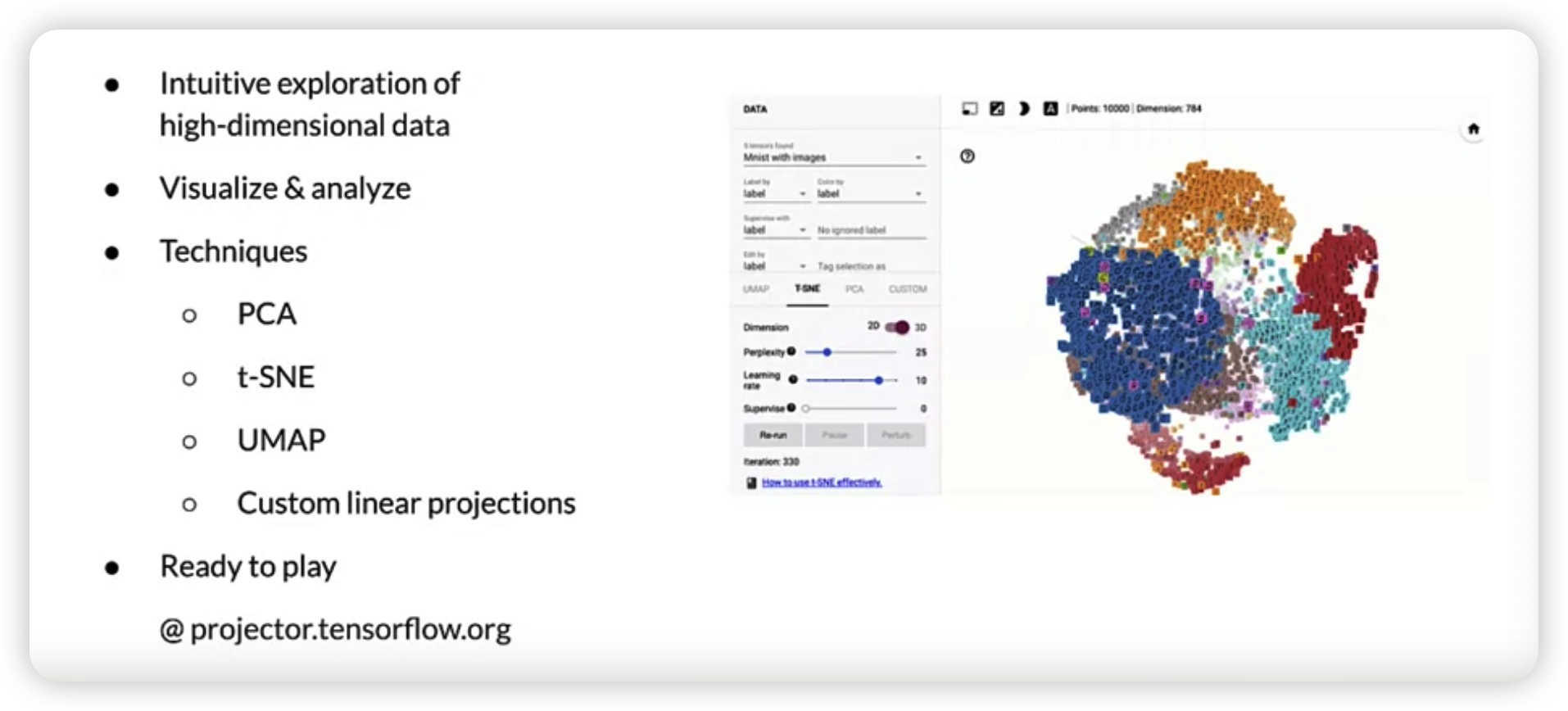
4. Other techniques
Dimension Reduction in embeddings
- ex) PCA, t-SNE, UMAP
Feature Crossing
TF embedding projector
[4] Feature Crosses
Feature Cross = combine multiple features into new feature
( = synthetic feature encoding nonlinearity in feature space )
- non-linearity in feature space
- use fewer feature dimension
Example
- AxBxCxDxE : mulipyling 5 features
- [Day of Week, Hour] -> [Hour of Week]