
( reference : Machine Learning Data Lifecycle in Production )
Feature Transformation at Scale
[1] Preprocessing Data at Scale
Preprocessing data AT SCALE
- Real-world data : LARGE SCALE
- thus, will deal with LARGE SCALE data processing frameworks
- consistent transform
- not only on train & eval dataset,
- but also on serving dataset
ML Pipeline
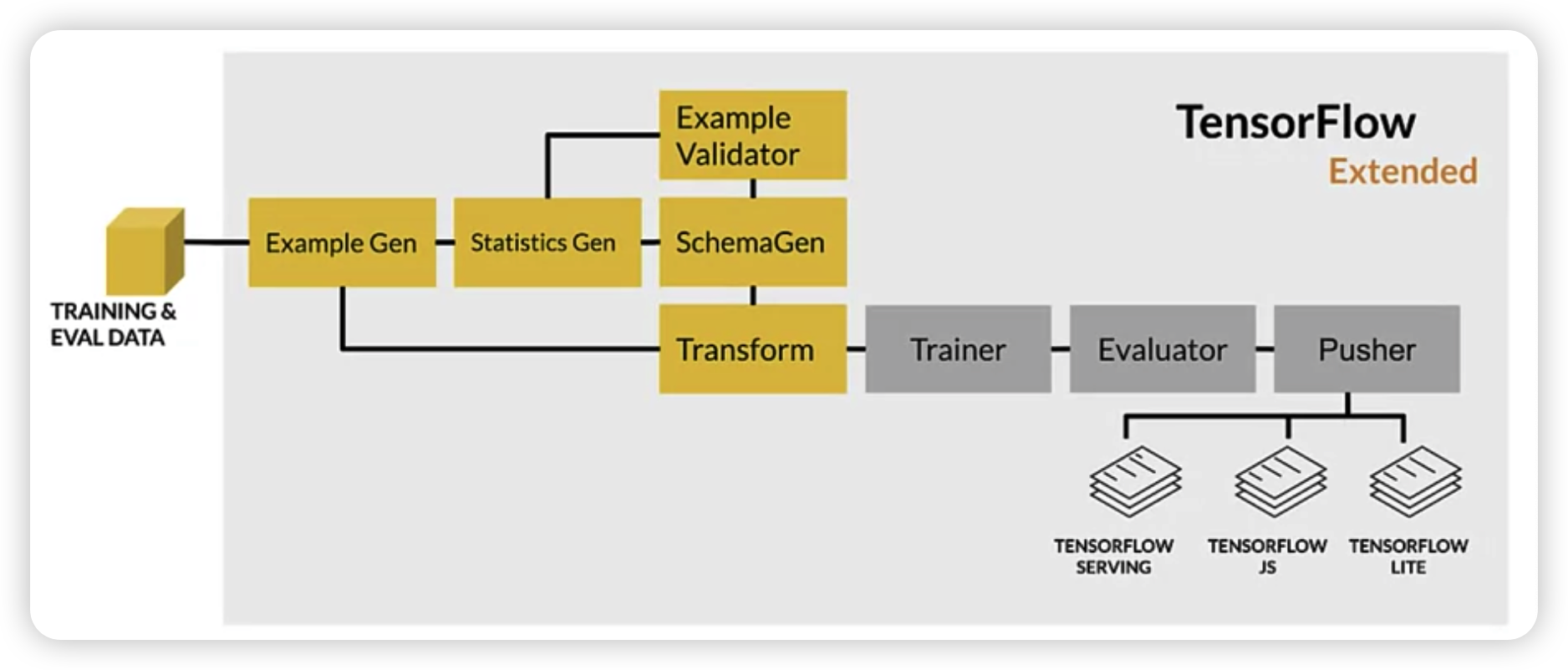
Outline
- (1) inconsistencies in FE
- (2) preprocessing granularity
- (3) preprocessing training data
- (4) optimize instance-level transformation
(1) inconsistencies in FE
- Training & Serving code paths : DIFFERENT
- Diverse deployment scenarios
- mobile / web / server …
- Training & Serving skews
(2) preprocessing granularity
Full-pass vs Instance-level
- Full-pass : WHOLE dataset
- Instance-level : INDIVIDUAL data
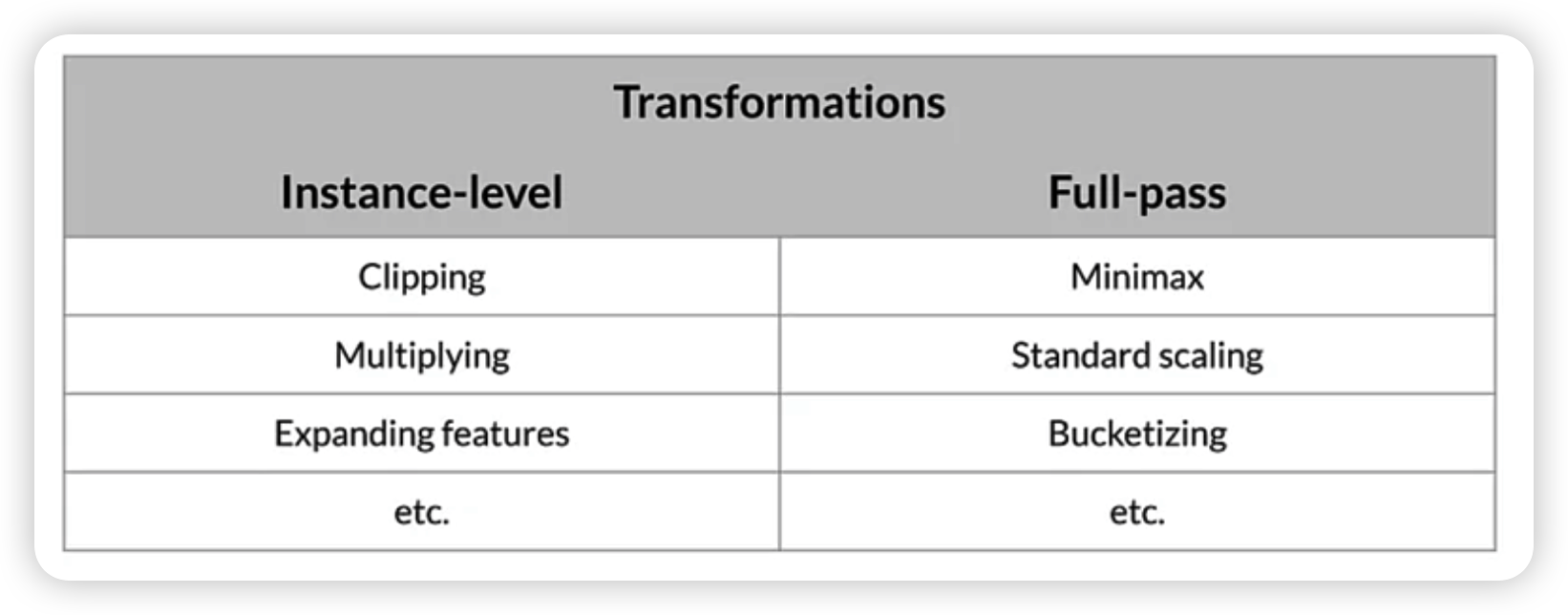
(3) preprocessing training data
Pre-process your training dataset!
- pros) only ONCE ( not one per training )
- cons ) have to do those transformation also on Serving data
Transforming within the model
- pros) easy iteration
- cons) expensive transform
- transformation per batch : skew
Why transform per batch?
- ex) batch normalization
- only access to single batch of data ( not full ) is available
(4) optimize instance-level transformation
-
affecst both the training & serving efficiency
-
use accelerators…!
[2] TFT ( TensorFlow Transform )
Outline
- benefits of using TFT
- Feature Transformation
tf.TransformAnalyzers
How it works
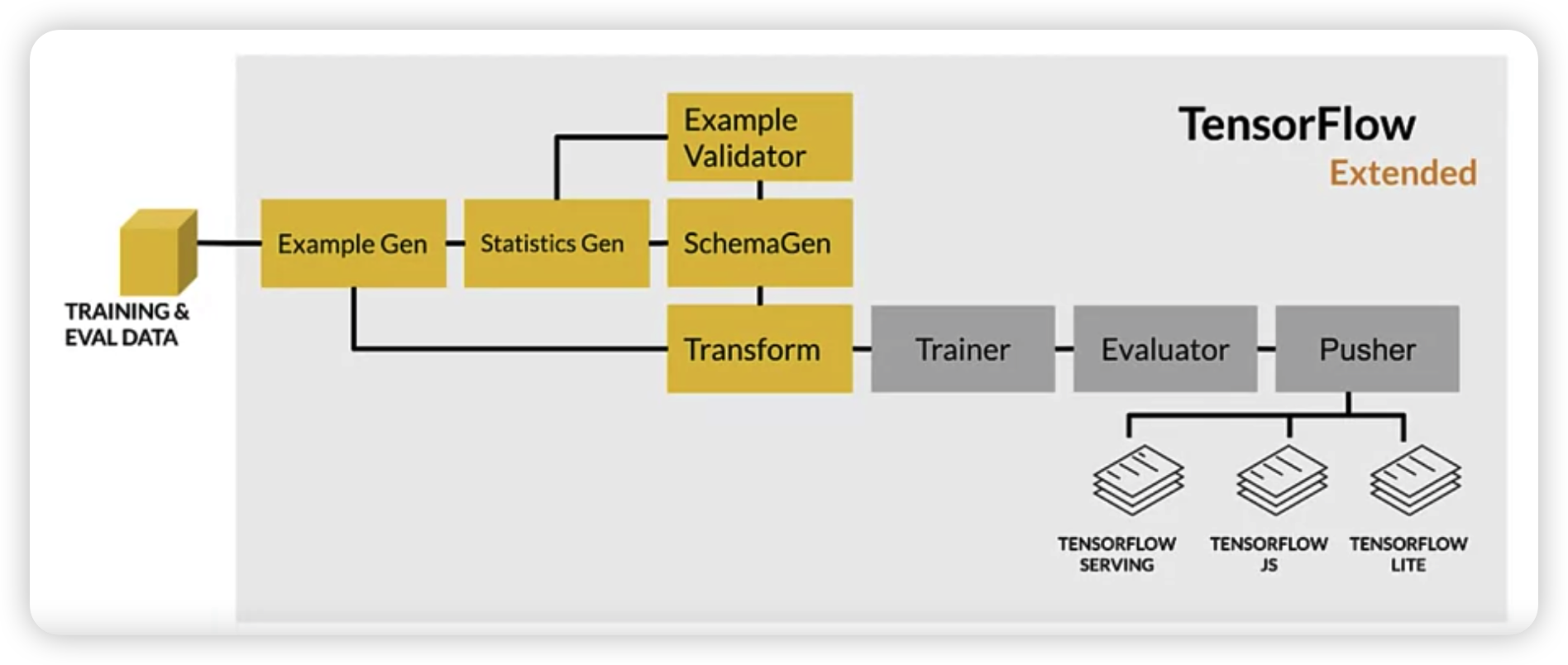
Tensorflow Extended
- will deal with in detail in coding post
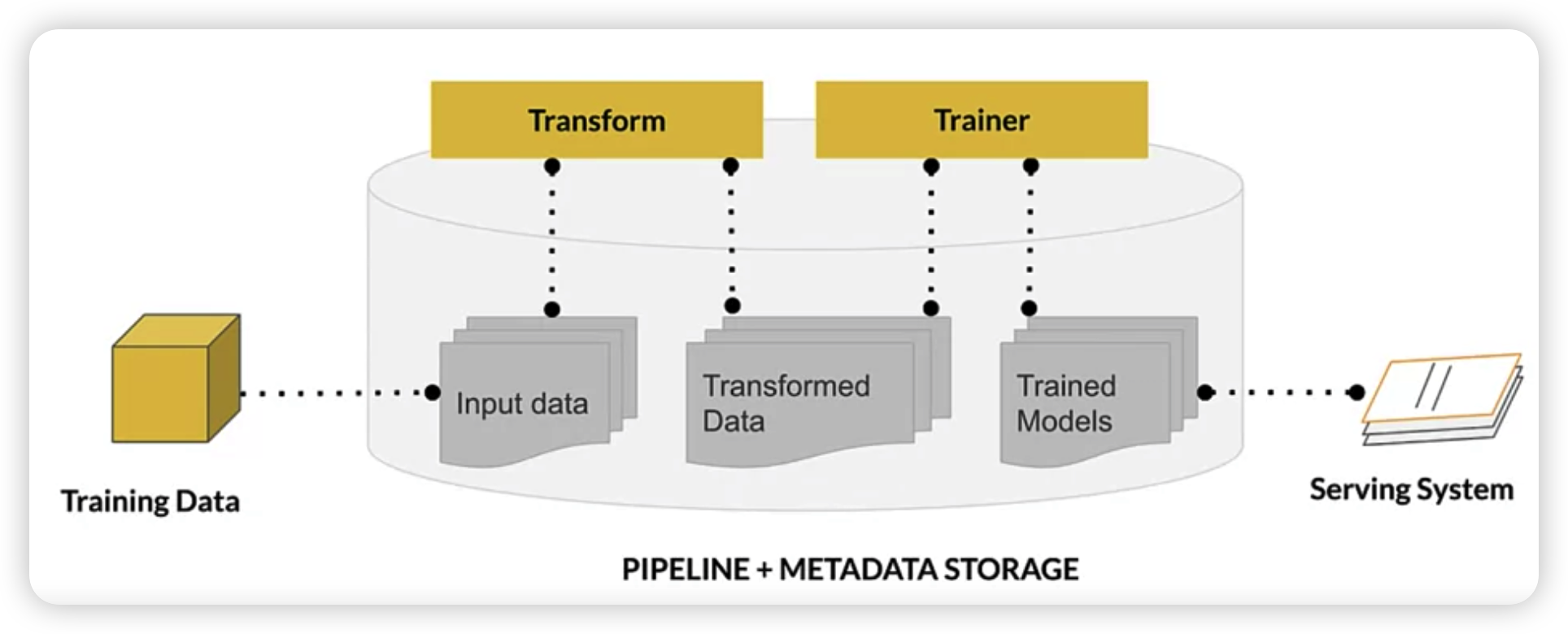
tf.Transform : layout
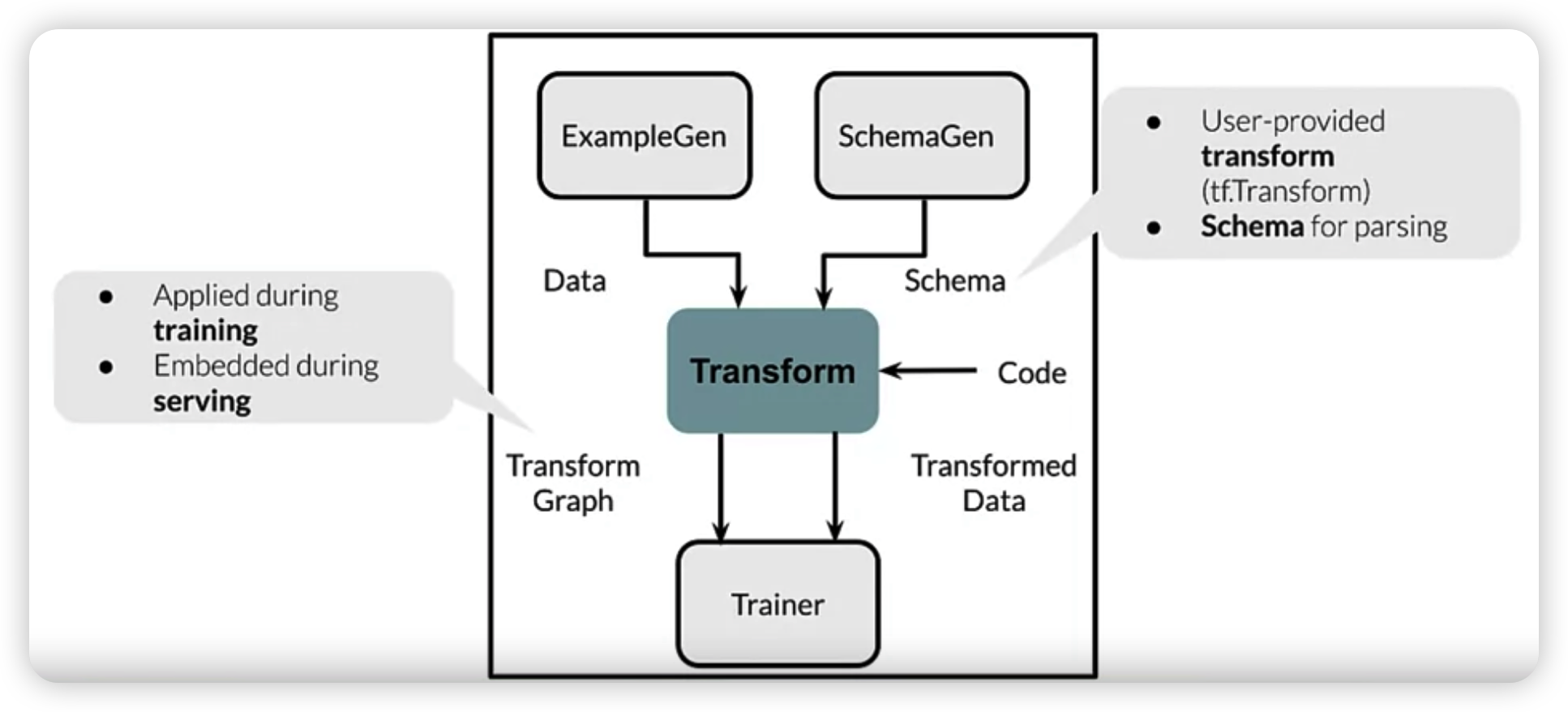
[ Transformation ]
( not only on TRAINING time, but also on SERVING time )
- input : from
ExampleGen&SchemaGen- data splitted by
ExampleGen - schema generated by
SchemaGen
- data splitted by
-
+ user’s code ( of FE that we want )
- result : TF graph
- transform graph & transform data
$\rightarrow$ given to trainer
tf.Transform : deeper
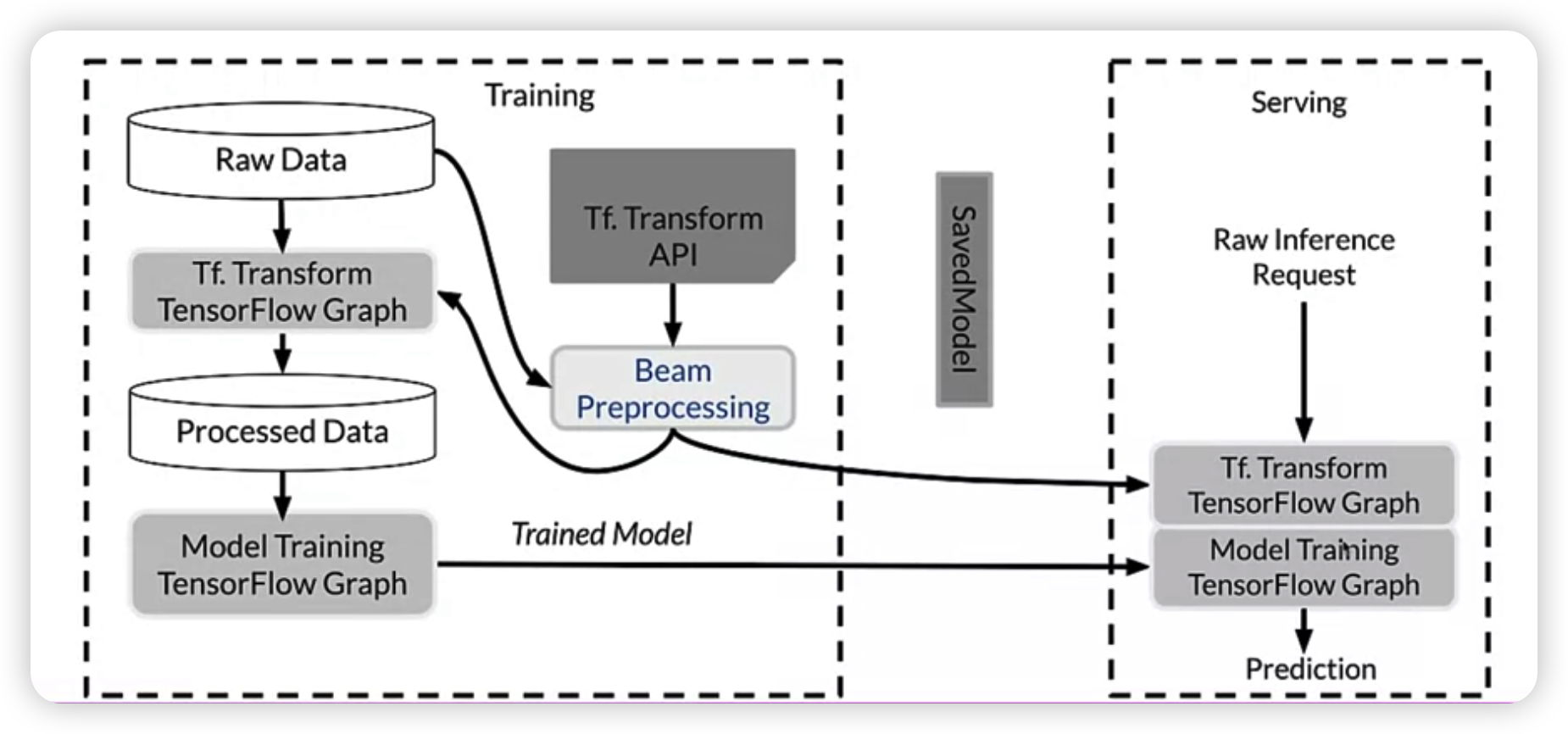
Training model also creates a TF graph!
2 graphs
- (1) from transform
- (2) from training
( 2 graphs are given to serving infrastructure )
with Tf Transform API…
-
express FE that we want ( give the code )
( or, give that code to Apache Beam distributed processing cluster )
-
result : saved model
Analyzer
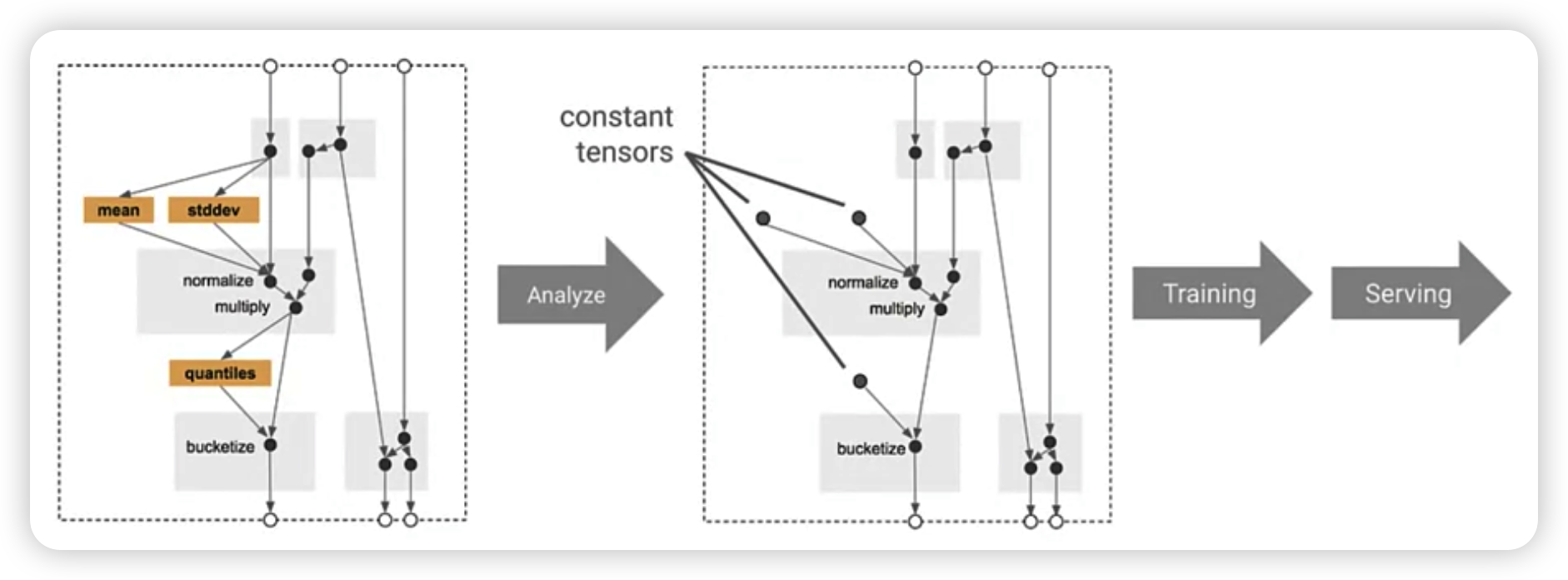
makes a full pass over our dataset in order to collect constants,
which are needed during feature engineering
- ex)
tft.min( minimum of all training dataset )
[3] Hello World with tf.Transform
[ Steps ]
- Data Collection
- Define Meta data
DatasetMetadata
- Transform
- wth
tf.Transformanalyzers
- wth
- Result : Constant Graph
1) Data Collection
example) 3 features & 3 data
[
{'x':1, 'y':1, 's':'hello'},
{'x':2, 'y':2, 's':'world'},
{'x':3, 'y':3, 's':'hello'},
]
2) Define Meta data
meta data = express the types of those 3 features
x&y: floats: string
from tensorflow_transform.tf_metadata import (dataset_metadata, dataset_schema)
raw_data_metadata = dataset_metadata.DatasetMetadata(
dataset_schema.from_feature_spec({
'y':tf.io.FixedLenFeature([], tf.float32),
'x':tf.io.FixedLenFeature([], tf.float32),
's':tf.io.FixedLenFeature([], tf.string)
})
)
3) Transform
Preprocess Data
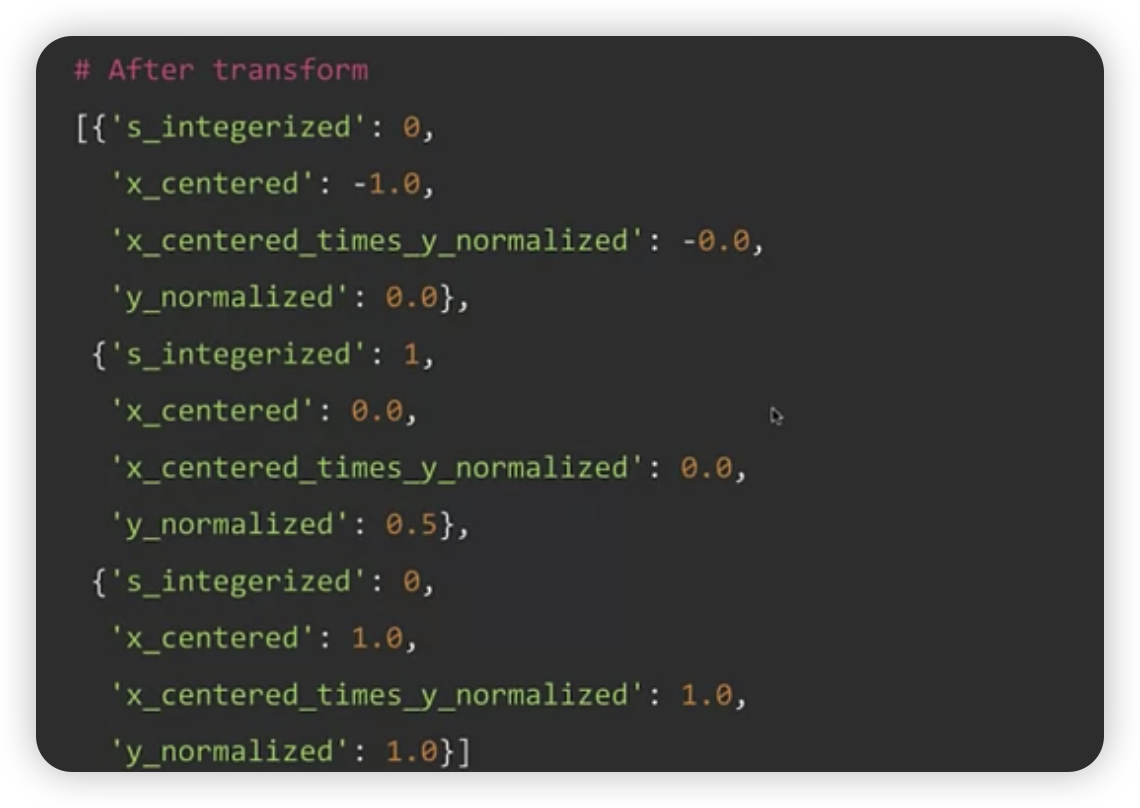
def preprocessing_fn(inputs):
x, y, s = inputs['x'], inputs['y'], inputs['s']
x_centered = x - tft.mean(x)
y_normalized = tft.scale_to_0_1(y)
s_integerized = tft.compute_and_apply_vocabulary(s)
z = (x_centered * y_normalized)
outputs = {
'x_centered' : x_centered,
'y_normalized' : y_normalized,
's_integerized' : s_integerized,
'z' : z
}
return outputs

4) Result : Constant Graph
Running the pipeline ( with main() function )
- use Apache Beam
def main():
with tft_beam.Context(temp_dir = tempfile.mkdtemp()):
transformed_dataset, transform_fn = (
(raw_data, raw_data_metadata) | tft_beam.AnalyzeAndTranformDataset(preprocessing_fn)
)
transformed_data, transformed_metadata = transformed_dataset
if __name__ == '__main__':
main()
Result :
Summary
-
in TFX pipeline,
tf.Transformis used for feature engineering ( transformation ) -
tf.Transform:-
preprocessing of input data & feature engineering
-
preprocessing pipelines
& execute using large-scale data processing frameworks
-