
Mlflow 3. 모델 서빙
Contents
- 경로 이동
train.pytrain.py실행- 웹 대시보드
- 서빙 서버 띄우기
이번엔, 모델을 서빙해볼 것이다.
즉, ML 모델을 학습시키고, 이 weight값을 잘 저장한 다음에, 쉽게 inference에 사용할 수 있도록 만들 것이다.
1. 경로 이동
$ cd mlflow/examples
이번에 실습할 예제는 sklearn_logistic_regression이다.
이 또한, 아래의 3개의 큰 파일로 구성된다.
- (1)
MLproject - (2)
conda.yaml - (3)
train.py
2. train.py
# train.py
import numpy as np
from sklearn.linear_model import LogisticRegression
import mlflow
import mlflow.sklearn
if __name__ == "__main__":
X = np.array([-2, -1, 0, 1, 2, 1]).reshape(-1, 1)
y = np.array([0, 0, 1, 1, 1, 0])
lr = LogisticRegression()
lr.fit(X, y)
score = lr.score(X, y)
print("Score: %s" % score)
mlflow.log_metric("score", score)
mlflow.sklearn.log_model(lr, "model")
print("Model saved in run %s" % mlflow.active_run().info.run_uuid)
3. train.py 실행
이번엔, MLproject를 실행하지 않고, direct하게 py 파일을 실행해본다.
Score: 0.6666666666666666
Model saved in run 5159a4b9f74a497f87ee358beceb45ac
방금 돌린 이 모델이 5159a4b9f74a497f87ee358beceb45ac의 run id를 가진 run(실행)에 저장된 것을 알 수 있다.
이렇게 저장된 모델(weight/parameter)값들도 일종의 artifact로써, mlruns 에 저장이 된다.
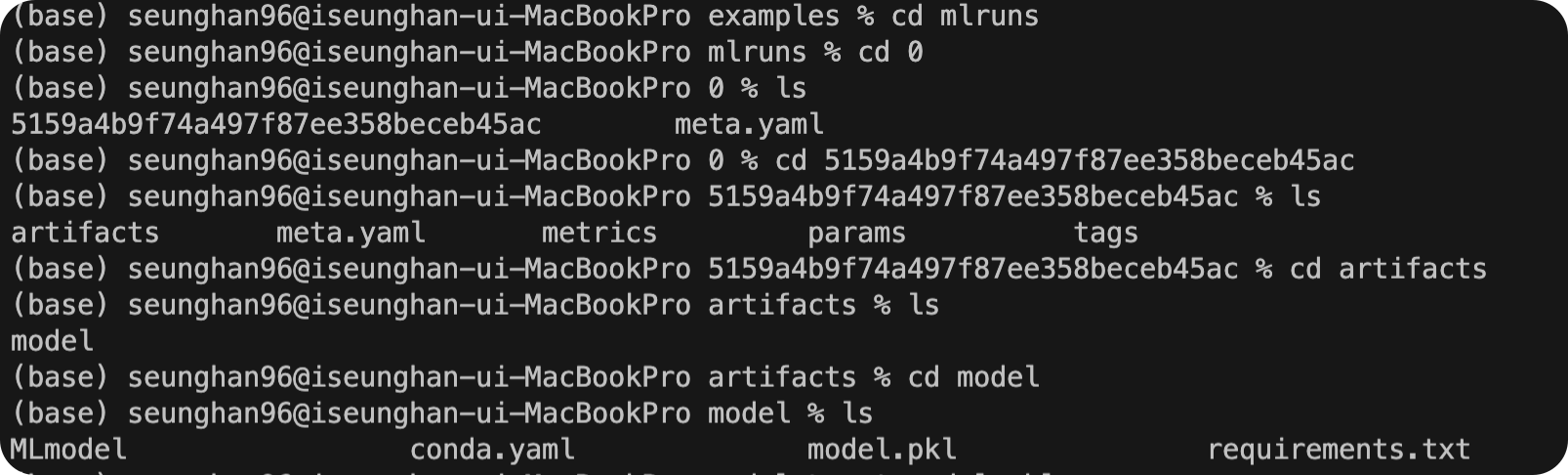
4. 웹 대시보드
$ mlflow ui
[2022-05-06 20:59:19 +0900] [25985] [INFO] Starting gunicorn 20.1.0
[2022-05-06 20:59:19 +0900] [25985] [INFO] Listening at: http://127.0.0.1:5000 (25985)
[2022-05-06 20:59:19 +0900] [25985] [INFO] Using worker: sync
[2022-05-06 20:59:19 +0900] [25986] [INFO] Booting worker with pid: 25986
위의 http://127.0.0.1:5000 로 접속해보자.
방금 전에 실행한 run에 대한 결과가 웹 ui상으로 보기 쉽게 관리되는 것을 알 수 있다.
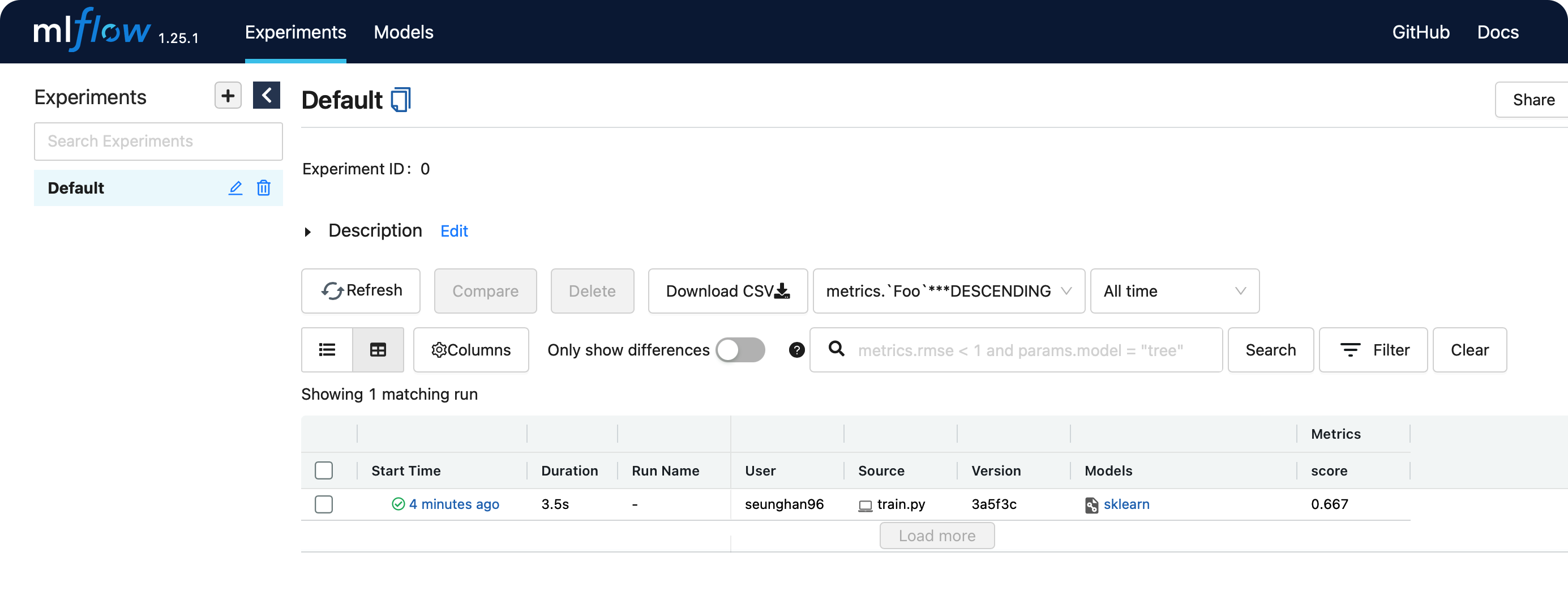
5. 서빙 서버 띄우기
방금 실행한 위 프로젝트를 서빙하는 서버를 띄워볼 것이다.
그러기 위한 명령어는 mlflow models serve -m runs:/<RUN_ID>/model 이다.
( 우리의 RUN ID는 5159a4b9f74a497f87ee358beceb45ac 였었다 )
$ mlflow models serve -m runs:/5159a4b9f74a497f87ee358beceb45ac/model
/Users/seunghan96/opt/anaconda3/lib/python3.9/site-packages/click/core.py:2309: FutureWarning: `--no-conda` is deprecated and will be removed in a future MLflow release. Use `--env-manager=local` instead.
value = self.callback(ctx, self, value)
2022/05/06 21:01:18 INFO mlflow.models.cli: Selected backend for flavor 'python_function'
2022/05/06 21:01:18 INFO mlflow.pyfunc.backend: === Running command 'gunicorn --timeout=60 -b 127.0.0.1:5001 -w 1 ${GUNICORN_CMD_ARGS} -- mlflow.pyfunc.scoring_server.wsgi:app'
[2022-05-06 21:01:18 +0900] [26019] [INFO] Starting gunicorn 20.1.0
[2022-05-06 21:01:18 +0900] [26019] [INFO] Listening at: http://127.0.0.1:5001 (26019)
[2022-05-06 21:01:18 +0900] [26019] [INFO] Using worker: sync
[2022-05-06 21:01:18 +0900] [26020] [INFO] Booting worker with pid: 26020
해당 서빙 서버가 잘 작동하는지 확인하기 위해, curl 명령을 날려보자.
( 엔드포인트 : /invocations )
$ curl -d '{"columns":["x"], "data":[[1], [-1]]}' -H 'Content-Type: application/json; format=pandas-split' -X POST localhost:5001/invocations
[1, 0]
학습한 Logistic Regression 모델을 바탕으로, 예측이 잘 수행됨을 알 수 있다!
참고 : https://dailyheumsi.tistory.com