
Mlflow 7. Model Registry
- Model Registry란?
-
이름에서도 알 수 있듯, “모델 저장소”이다.
( = ML 프로젝트의 개별 실행(run)을 통해 나온 아티팩트 중 하나인 “모델”을 저장하는 곳이다 )
-
Model Registry에 등록된 모델은 어디서든 쉽게 불러와서 사용할 수 있다.
- 모델 등록하기 1 - 웹 UI
앞선 포스트 ML Flow 6 에서 사용했던 트래킹 서버로 들어가서, 수행했던 실행(run)에 들어가보면, 아래와 같은 화면이 뜨는 것을 확인했었다.
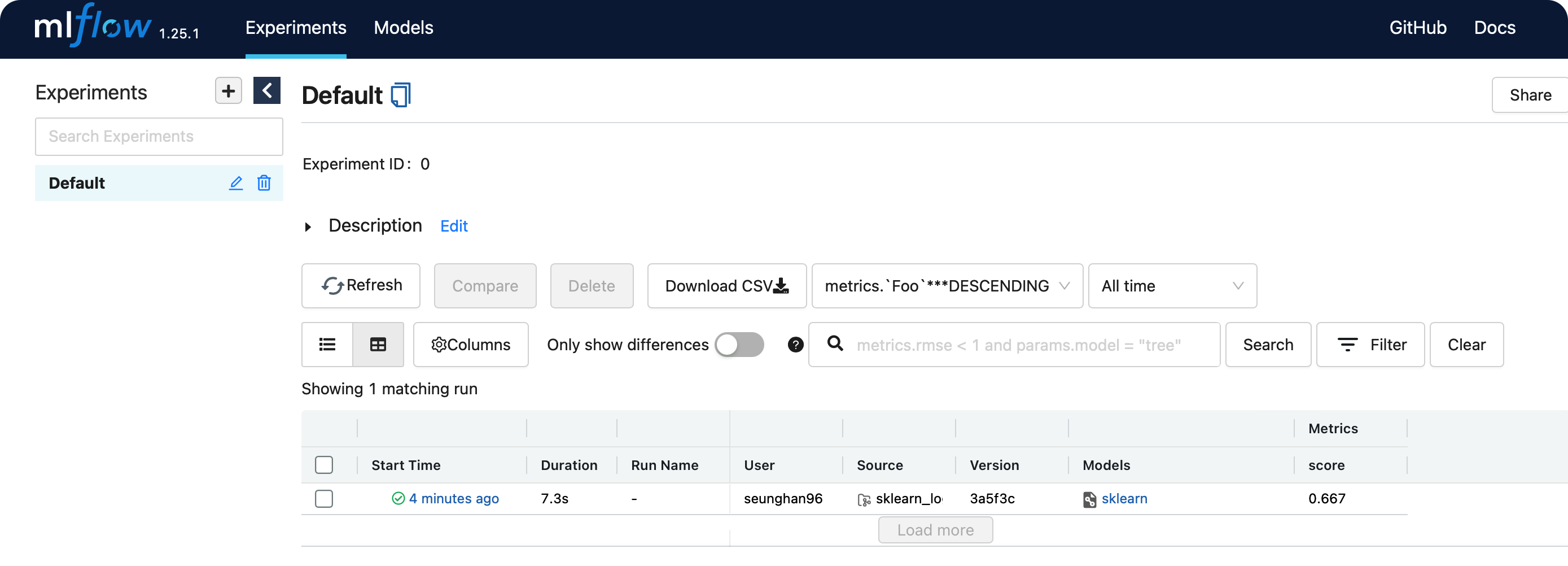
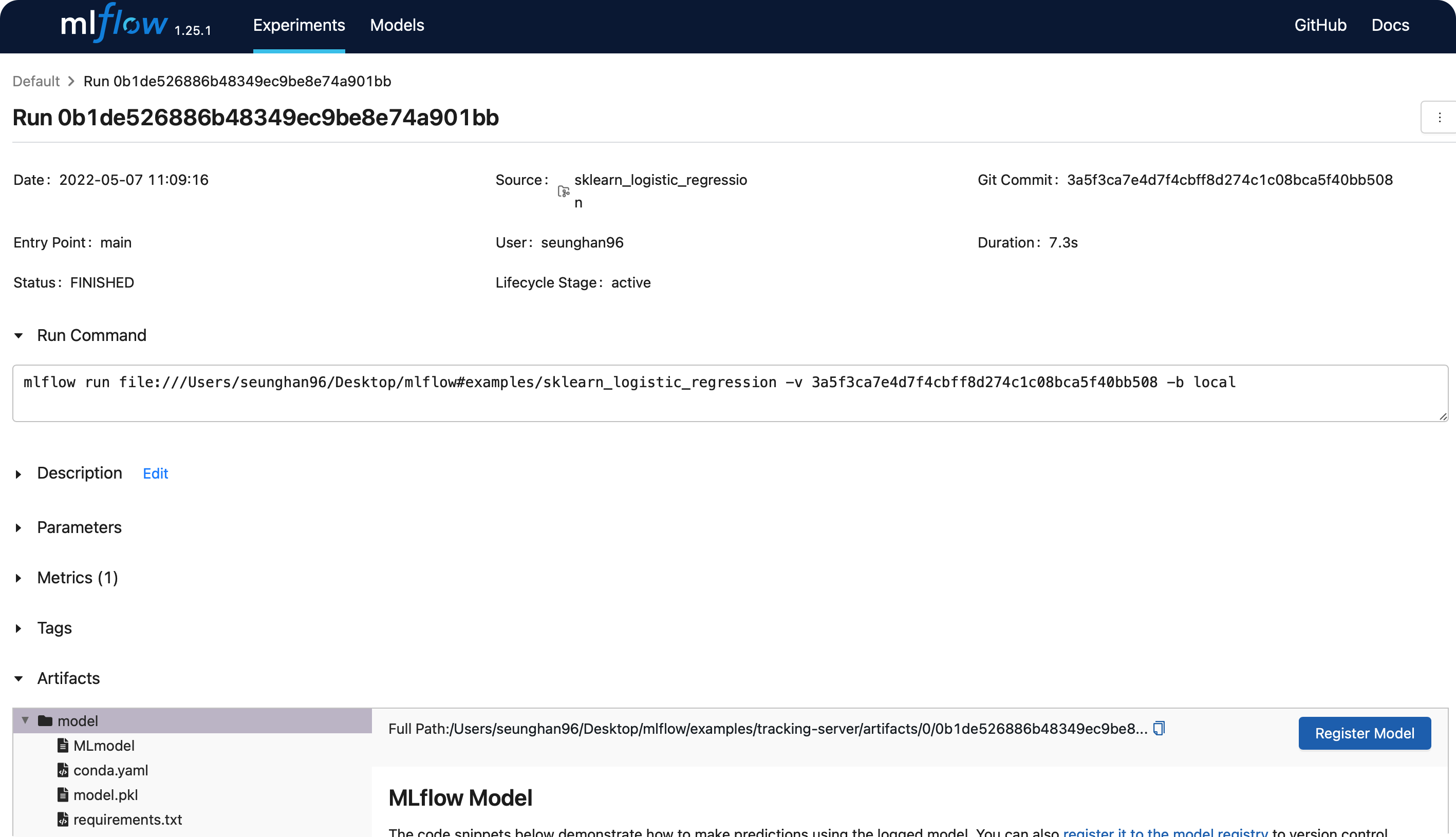
여기서, Register Model 이라는 버튼을 클릭하면,
방금 학습한 모델을 Model Registry에 등록할 수 있다.
- 이름 :
LogisticRegression
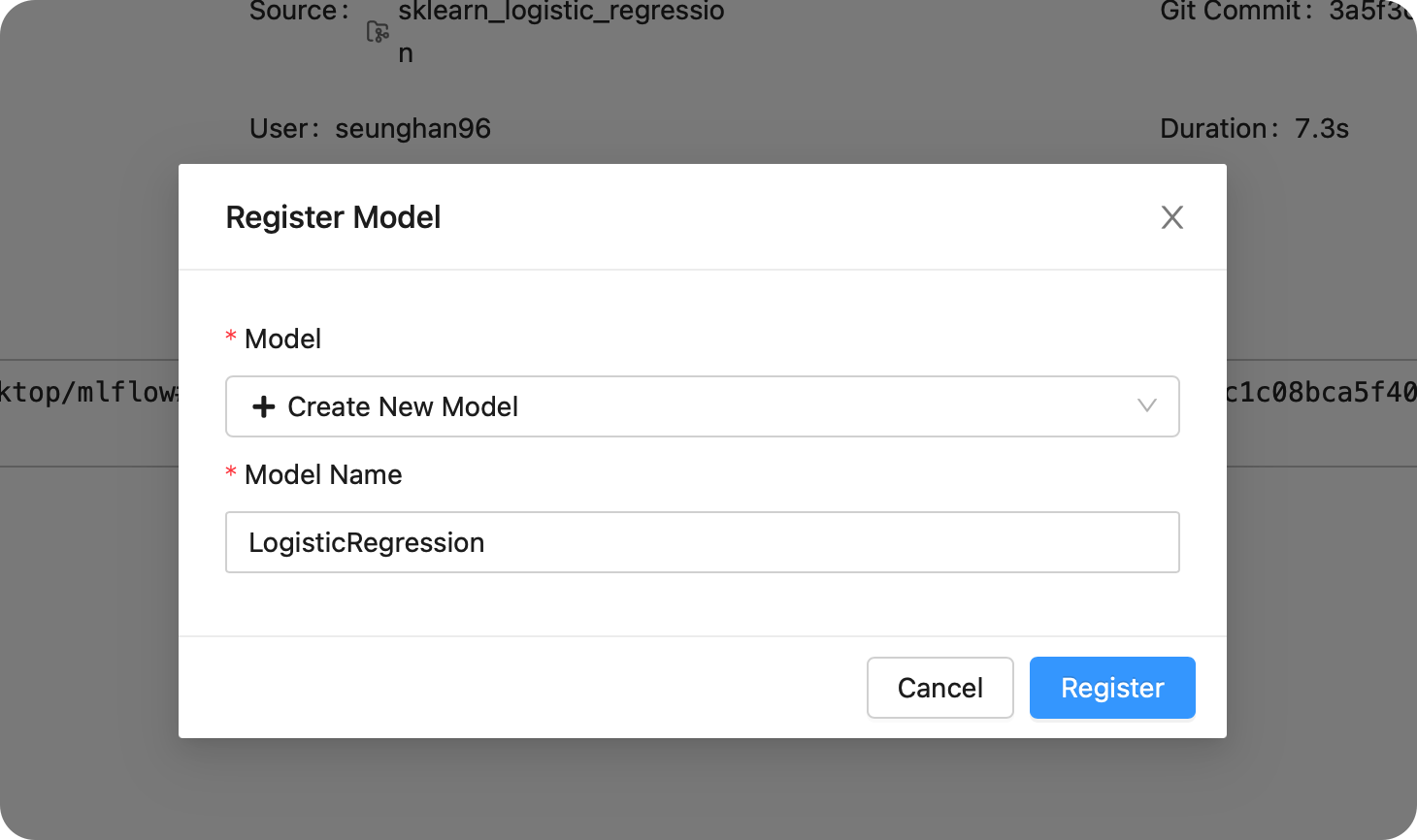
방금 등록한 모델을 확인하기 위해, Model Registry에 들어가서 확인해보자.
( 좌측 상단에 Models 를 클릭하면 확인할 수 있다 )
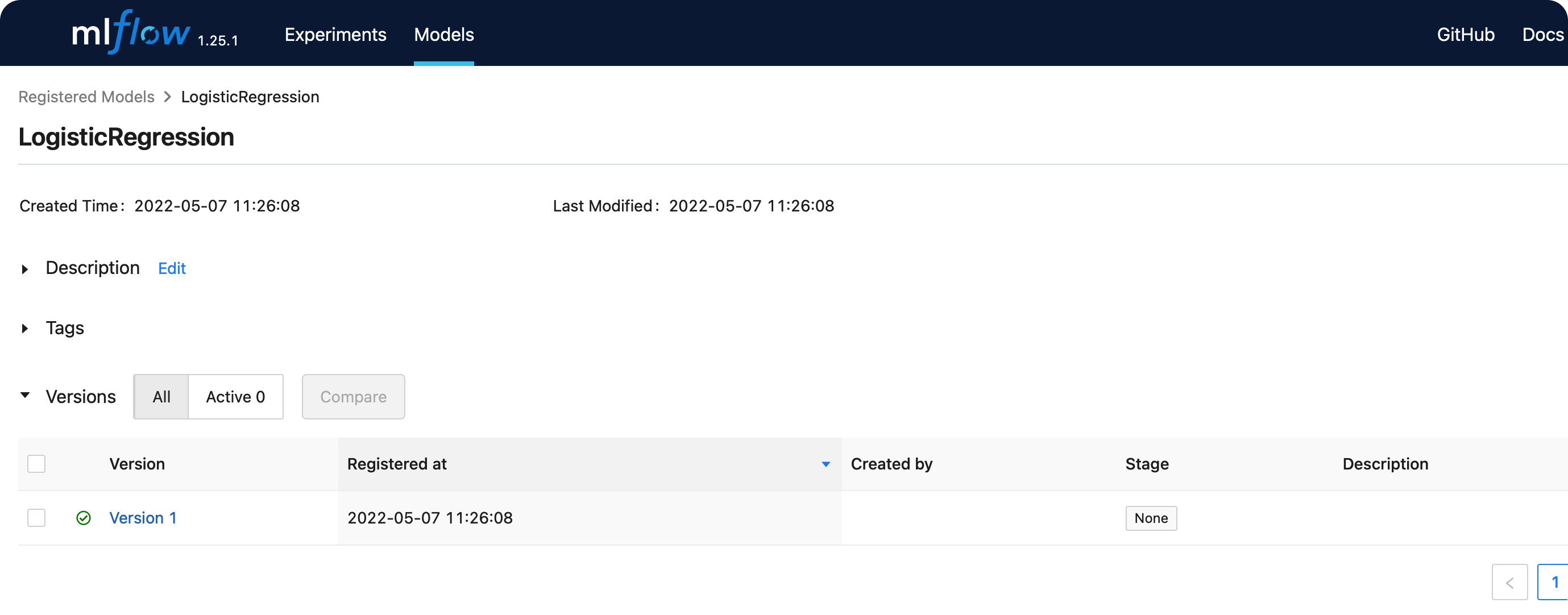
방금 등록한 LogisticRegression 모델이 있는 것을 확인할 수 있다.
- 최초로 등록한 버전이므로,
Version 1이라는 버전명이 기록된 것을 알 수 있다.
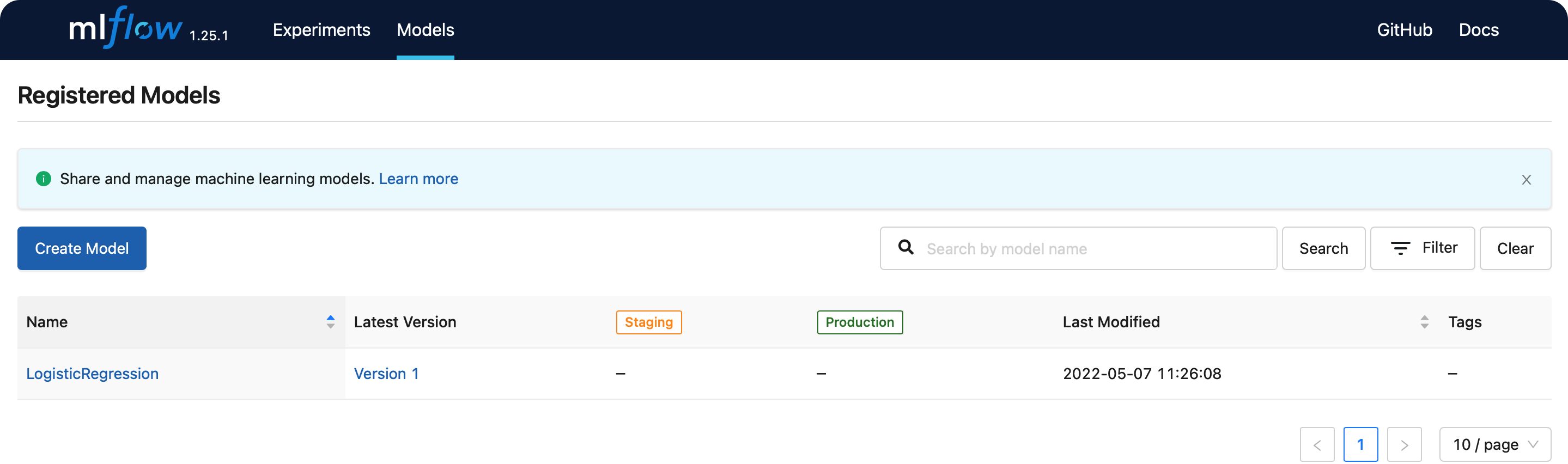
LogisticRegression을 클릭하면, 생성한 여러 버전들을 확인할 수 있다
( 지금은 한개 밖에 없으므로, Version 1 밖에 없다 )
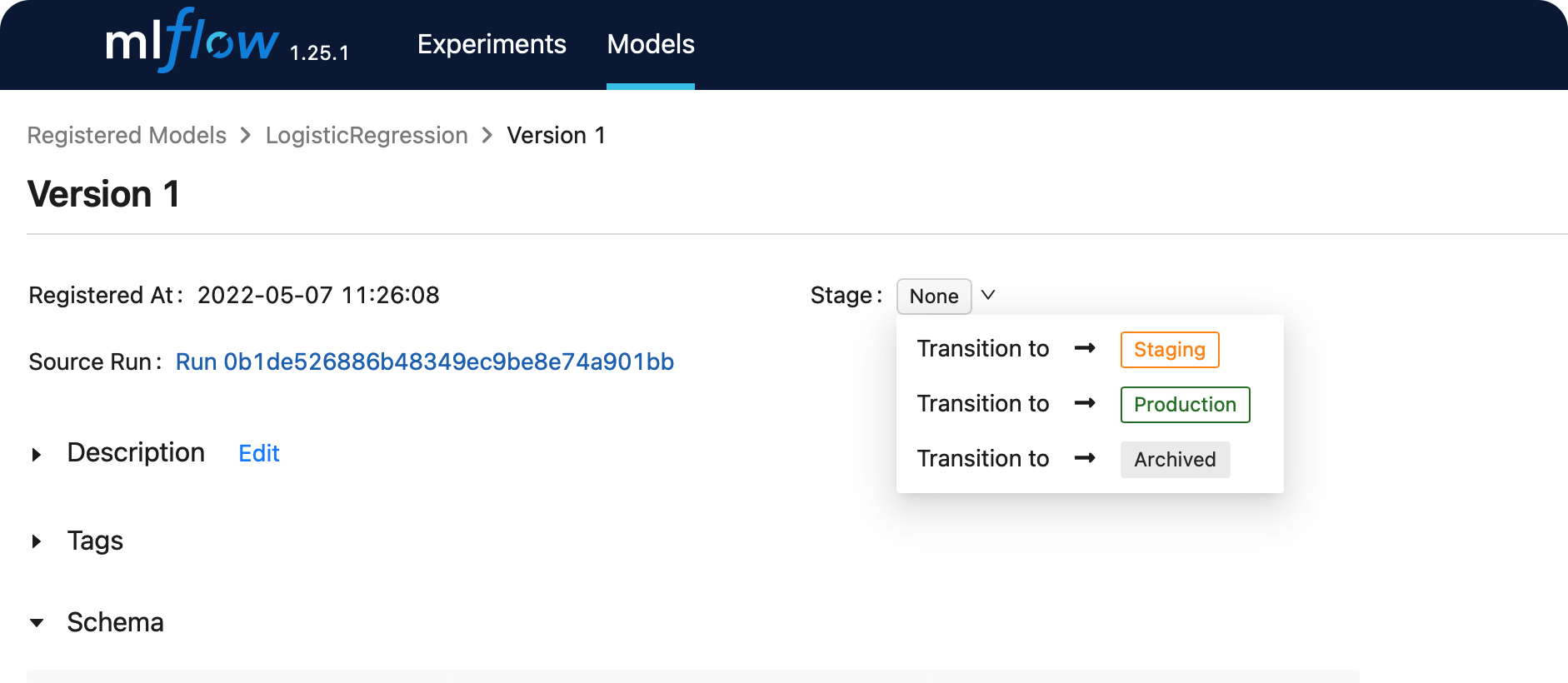
이를 보다 자세히 확인하기 위해, 해당 버전을 클릭해서 들어가서 확인할 수 있다.
해당 버전의 모델의 스테이지 상태를
- (1)
Staging - (2)
Production - (3)
Archived중 하나로 바꿀 수 있다.
- 모델 등록하기 2 - 코드 (1)
위의 방법처럼, 웹 UI를 통해서도 모델을 등록할 수 있지만, 코드 상에서도 등록할 수 있다.
총 3가지 방법
- (1)
mlflow.sklearn.log_model()에registered_model_name - (2)
mlflow.register_model() - (3)
MlflowClient.create_registered_model()&MlflowClient.create_model_version()
3-1. 코드 (1)
mlflow.sklearn.log_model() 에 registered_model_name
앞선 예제인 sklearn_logistic_regression 예제의 train.py 파일을 아래와 같이 수정해보자.
import numpy as np
from sklearn.linear_model import LogisticRegression
import mlflow
import mlflow.sklearn
if __name__ == "__main__":
X = np.array([-2, -1, 0, 1, 2, 1]).reshape(-1, 1)
y = np.array([0, 0, 1, 1, 1, 0])
lr = LogisticRegression()
lr.fit(X, y)
score = lr.score(X, y)
print("Score: %s" % score)
mlflow.log_metric("score", score)
mlflow.sklearn.log_model(lr, "model", registered_model_name="LogisticRegression")
print("Model saved in run %s" % mlflow.active_run().info.run_uuid)
바뀐 부분
- before :
mlflow.sklearn.log_model(lr, "model") - after :
mlflow.sklearn.log_model(lr, "model", registered_model_name="LogisticRegression")
$\rightarrow$ 등록할 Model의 이름을 지정하는 부분이 추가되었다.
위와 같이 코드를 수정한 뒤, 해당 프로젝트를 실행해보자.
$ mlflow run sklearn_logistic_regression --no-conda
/Users/seunghan96/opt/anaconda3/lib/python3.9/site-packages/click/core.py:2309: FutureWarning: `--no-conda` is deprecated and will be removed in a future MLflow release. Use `--env-manager=local` instead.
value = self.callback(ctx, self, value)
2022/05/07 11:38:04 INFO mlflow.projects.utils: === Created directory /var/folders/ln/bxrzt06d0r3fbxsdkgxb_dc80000gn/T/tmpq3jn4k8t for downloading remote URIs passed to arguments of type 'path' ===
2022/05/07 11:38:04 INFO mlflow.projects.backend.local: === Running command 'python train.py' in run with ID '758eabd324de45de8d63086eb16a89aa' ===
Score: 0.6666666666666666
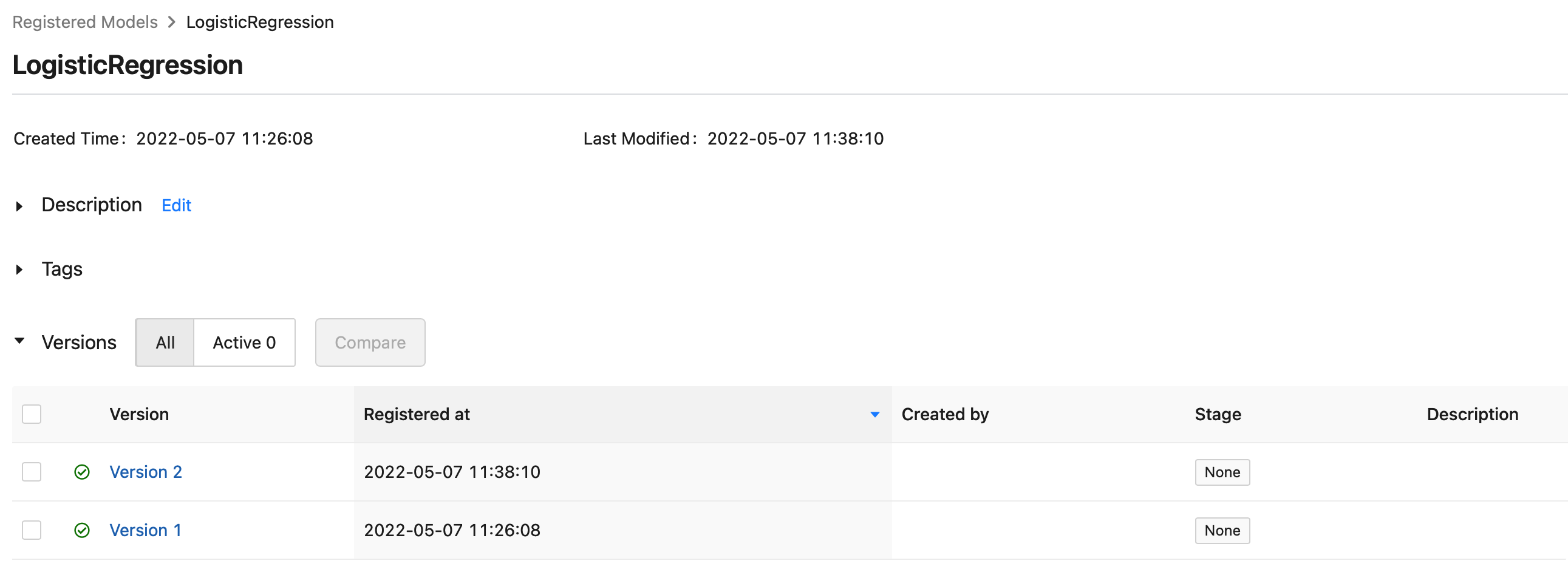
Registered model 'LogisticRegression' already exists. Creating a new version of this model...
2022/05/07 11:38:10 INFO mlflow.tracking._model_registry.client: Waiting up to 300 seconds for model version to finish creation. Model name: LogisticRegression, version 2
Created version '2' of model 'LogisticRegression'.
Model saved in run 758eabd324de45de8d63086eb16a89aa
2022/05/07 11:38:10 INFO mlflow.projects: === Run (ID '758eabd324de45de8d63086eb16a89aa') succeeded ===
출력된 결과에서, 아래의 두 가지를 해석해보자.
-
Registered model ‘LogisticRegression’ already exists. Creating a new version of this model…
$\rightarrow$ 우리는 앞서서 웹 UI를 통해 LogisticRegression이라는 이름의 모델을 만들었었다. 따라서 해당 모델이 이미 존재하고, 이 모델에 대한 새로운 버전을 생성한다는 문구가 뜬다.
-
Created version ‘2’ of model ‘LogisticRegression’
$\rightarrow$ 새로 생성한 버전은 “version 2” 이다.
한번 그 결과를 웹 UI에서 확인해보자.
3-2. 코드 (2)
mlflow.register_model()
RUN_ID = ..
result = mlflow.register_model(
model_uri="runs:/{}/model".format(RUN_ID),
name="LogisticRegresion"
)
2 개의 인자
-
model_uri: RUN_ID & (artifacts 내에)model이 저장된 경로 -
name: 등록할 모델의 이름
3-3. 코드 (3)
MlflowClient.create_registered_model() &MlflowClient.create_model_version()
from mlflow.tracking import MlflowClient
model_name = 'LogisticRegression'
EXPERIMENT_ID = 0
RUN_ID = ..
client = MlflowClient()
client.create_registered_model(model_name)
result = client.create_model_version(
name = model_name,
source = "artifacts/{}/{}/artifacts/model".format(EXPERIMENT_ID, RUN_ID),
run_id = RUN_ID
)
- 등록된 모델 불러오기
앞서 등록한 1개의 모델 ( 2개의 버전 )은, 어느곳에서든 쉽게 불러올 수 있다.
그러기 위해, tracking server 하에 아래의 load_registered_model.py 코드를 작성하자.
# load_registered_model.py
import mlflow.pyfunc
import numpy as np
model_name = "LogisticRegression"
model_version = 2
model = mlflow.pyfunc.load_model(
model_uri=f"models:/{model_name}/{model_version}"
)
# 단계(stage)를 기준으로 가져오고 싶을 때
# stage = 'Staging'
# model = mlflow.pyfunc.load_model(
# model_uri=f"models:/{model_name}/{stage}"
# )
X = np.array([[1], [2], [3]])
Y = model.predict(X)
print(Y)
그런 뒤, 아래의 코드를 실행하면, 모델이 잘 불러와져서 예측을 잘 수행한 것을 확인할 수 있다.
$ export MLFLOW_TRACKING_URI="http://127.0.0.1:5000"
$ python load_registered_model.py
[1 1 1]
- 등록된 모델 서빙하기
앞서 만든 2개의 버전 중, 첫 번째 버전 ( Version 1 )을 서빙해볼 것이다.
mlflow models serve -m "models:/LogisticRegression/1" --port 5001 --no-conda
서빙이 잘 되는지, curl 명령을 통해 확인해보자.
- [1,0]으로 예측값이 잘 나온 것을 확인할 수 있다.
$ curl \
-d '{"columns":["x"], "data":[[1], [-1]]}' \
-H 'Content-Type: application/json; format=pandas-split' \
-X POST localhost:5001/invocations
[1, 0]
참고 : https://dailyheumsi.tistory.com