
( reference : Introduction to Machine Learning in Production )
Deployment
[1] Key Challenges
2 main challenges
- 1) ML & statistical issues ( Concept & Data drift )
- 2) software engine issues
a) Concept & Data drift
ex) Speech Recognition
Training data
- purchased data ( clean )
Test
- data from a few month
\(\rightarrow\) the data have might changed!
2 kinds of drift
-
Concept drift = relation of \(X\) & \(Y\) have changed
-
Data drift = \(X\) have changed
b) software engine issues
checklist of questions
- 1) real-time vs batch
- 2) cloud vs edge/browser
- 3) computing resources
- 4) latency, throughput (QPS, query per second)
- 5) logging
- 6) security & privacy
Summary
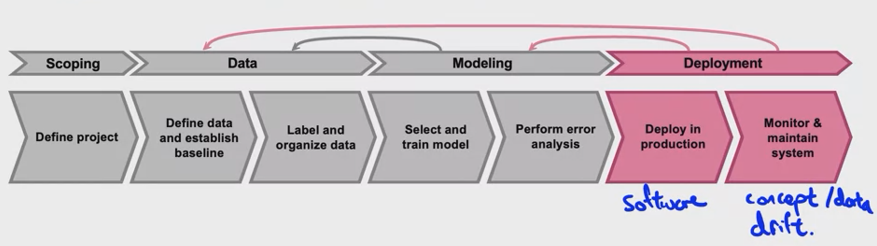
Challenge 1) software engine issues
\(\rightarrow\) in “deploying in production”
Challenge 2) concept & data drift
\(\rightarrow\) in “monitoring & maintaining system”
[2] Deployment patterns
Common Deployment Cases
- 1) new product/capability
- 2) automation with AI ( or assistance )
- 3) replace previous ML systems
Key ideas
- 1) gradual ramp up
- 2) roll back
Example : visual inspection )
a) Shadow Mode deployment
- shadows humans’ judgement & run parallel
- ML’s output is NOT used
\(\rightarrow\) purpose : gather data of how the model is performing, by comparing with the human judgement

b) Canary deployment
- roll out to only small fraction initially
- if OK … ramp up to traffic “gradually”
c) Blue green deployment
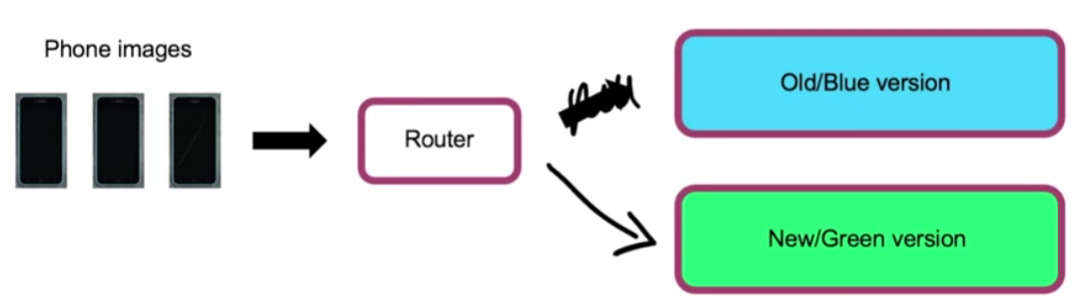
Version
- BLUE = old version
- GREEN = new version
Router switches from BLUE \(\rightarrow\) GREEN
- easy way to “roll back”
- do not have to be “at once”! ( gradually OK )
“Degrees of automation”
( Left : manual ) ———- ( Right : automatic )
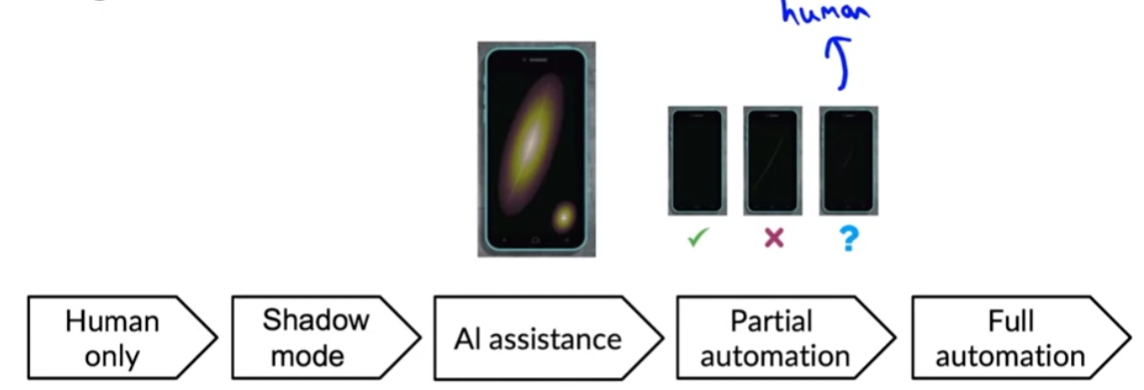
[3] Monitoring
a) Monitoring dashboard
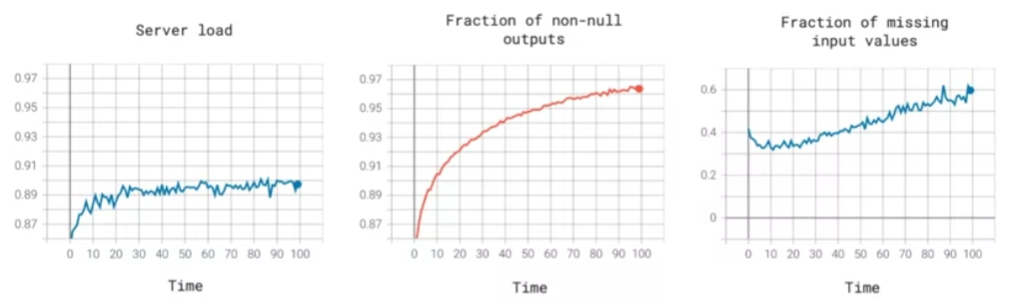
- set thresholds for alarms!
b) metrics to check (ex)
-
Software metrics
- memory, compute, latency, throughput, server load..
-
Input (\(X\)) metrics
( ex. speech recognition, defect image classification )
- ex) avg input length, avg input volume
- ex) # of missing values, avg image brightness
-
Output (\(Y\)) metrics
- ex) # of null values, CTR …
c) Iterative Procedure
“ML modeling” & “deployment” is both an iterative procedure!
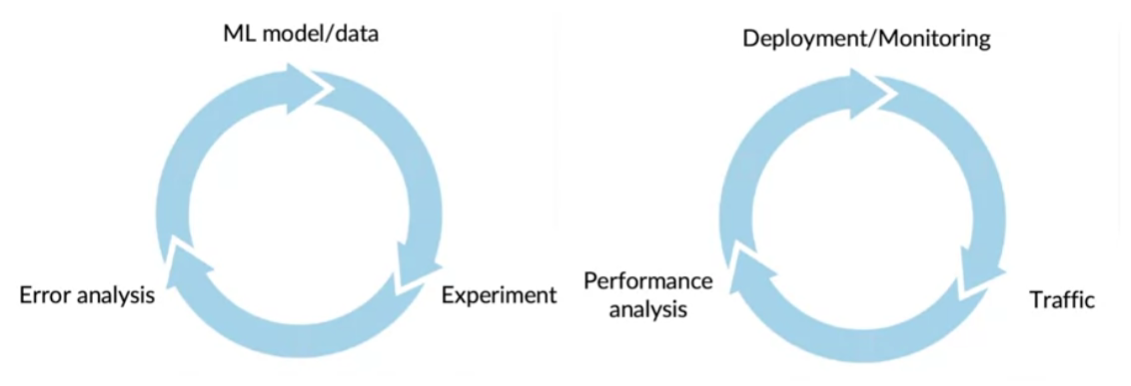
d) Model maintenance
may need to retrain models!
- manual retraining ( more common )
- automatic retraining
[4] Pipeline monitoring
Many AI systems involves a pipeline of multiple steps.
ex) speech recognition
- Input : audio & Output : transcript.
- implemented on mobile apps ( picture below )

Pipeline
Step 1) fed into VAD ( Voice Activity Detection )
- 1-1) check if anyone is speaking
- 1-2) looks at the long stream of audio & shortens the audio to just the part “where someone is talking”
- 1-3) send that to the (cloud) server
Step 2) perform speech recognition on the server
Thus, change in step 1) may affect the final result!
- ex ) change in way a new cell phone’s microphone works
- ex ) change in user’s profile & fed into rec sys
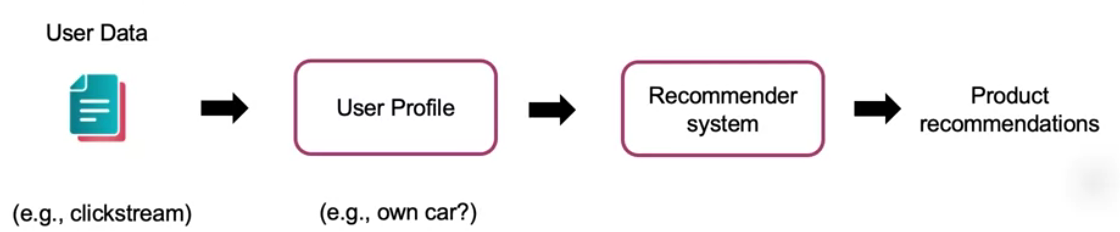
\(\rightarrow\) when working on ML pipelines, these effects can be complex to keep track on!
\(\therefore\) brainstorm metrics to monitor that can detect changes ( concept / data drift )
- software metric / input metric / output metrics
How quickly does the data change?
in general…
-
User data = slower drift
-
Enterprise data = faster drift