
( reference : Introduction to Machine Learning in Production )
Selecting and Training a Model
[1] Modeling Overview
Will learn how to improve ML models
( will focus on the modeling part of the full cycle of a ML project )
Contents
- 1) how to select and train the model
- 2) how to perform error analysis,
Two types of AI development
- 1) model-centric AI development
- 2) data-centric AI development.
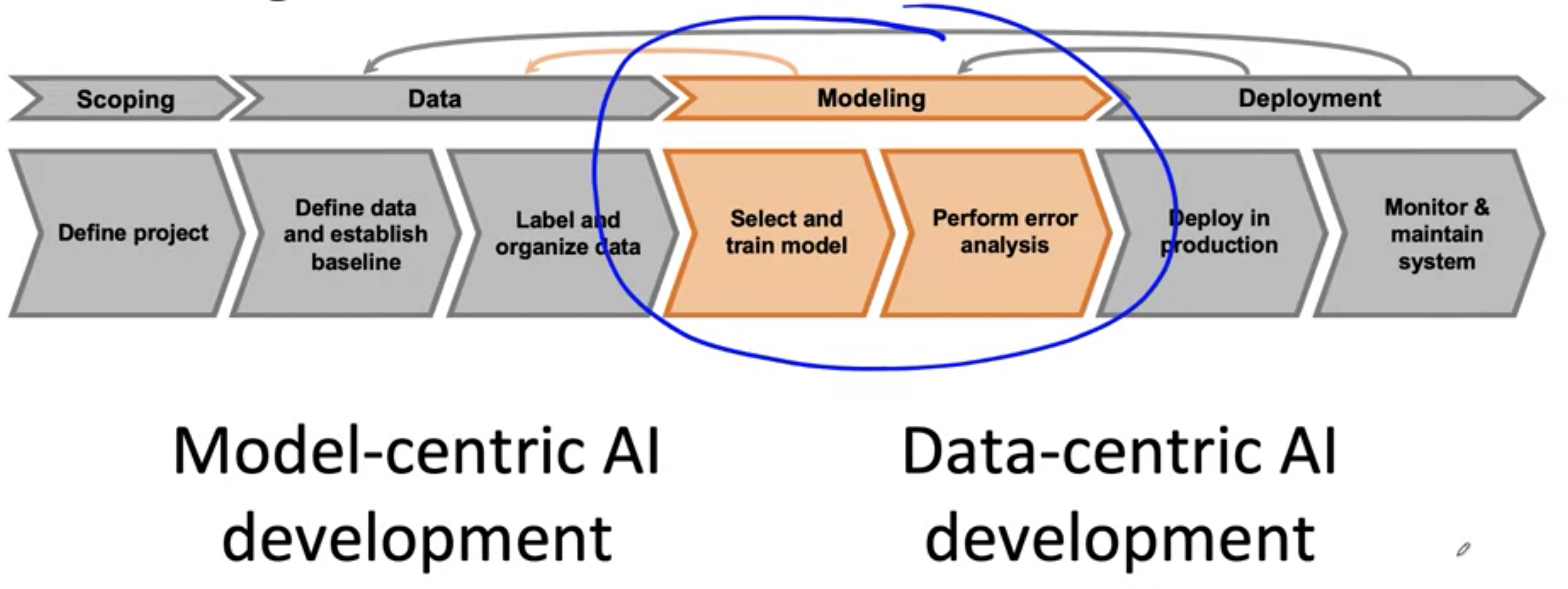
has been a lot of emphasis on how to choose the “right model” ( = 1) )
but sometimes, more useful to take a more **data-centric approach ( = 2) ) **
\(\rightarrow\) feed the model “HIGH-quality data”
( not just more and more data, but improve data efficiently )
[2] Key Challenges
Key Challenges while building ML models
Key Framework :
“AI systems = code + data” + ( hyperparameters )
-
code = algorithm/model
( until now… has been lots of emphasis on “code/model”, but not on “data” )

For many applications, have the flexibility to change the data better way!
( sometimes, will be more efficient to spend a lot of time improving the data )
Iterative Process
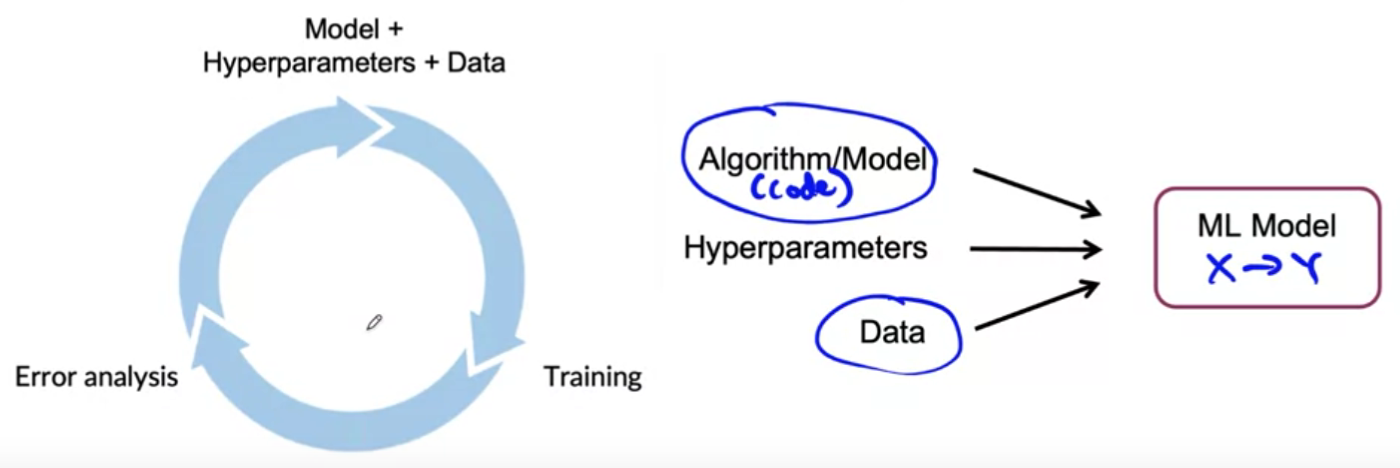
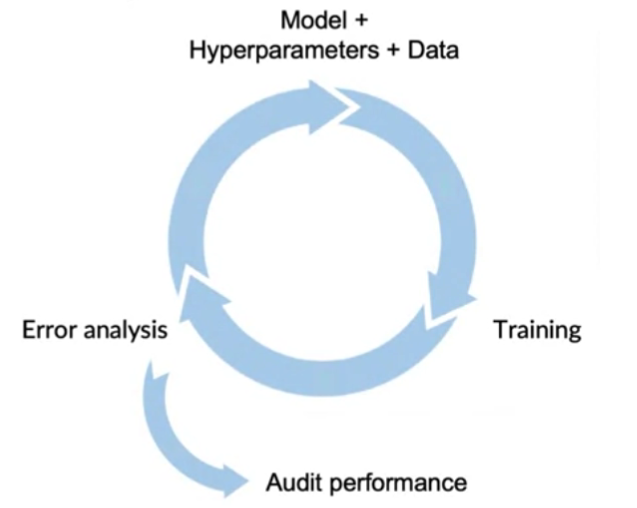
- model development is an iterative process
- step 1) start with model + hyperparameter + data
- step 2) train model
- step 3) error analysis
- help decide how to improve model/hyperparameters/data
- back to step 1)
Challenges of model development?
-
have to do well on “TRAINING dataset”
-
have to do well on “DEV/TEST dataset”
-
have to do well on “business metric & project goals”
\(\rightarrow\) often overlooked ( good 2 \(\neq\) good 3)
\(\rightarrow\) disagreements between ML team & business team
[3] Why low average error isn’t good enough
Not enough to do just well on dev/test dataset!
\(\rightarrow\) then… what to do more to make project successful??
Challenges ( additional to concept/data drift )
-
may have low test set error, but when performance on a set of disproportionately important examples isn’t good enough …
\(\rightarrow\) will still not be acceptable for production deployment.
-
performance on key slices of the data set
-
rare cases
Ex for challenge 1 ) Web Search

2 types of queries
- 1) informational and transactional queries
- should return the most relevant results
- users = forgive wrong ranking
- 2) navigational queries
- user has a very clear intent
- users = unforgive wrong results(urls)
Navigational queries are a disproportionately important set of examples
-
BUT, average test set accuracy weight all examples equally
-
\(\rightarrow\) solution : higher weight on the latter …. but just changing the weights of different examples doesn’t always solve the entire problem
Ex for challenge 2 ) ML for loan approval
ML algorithm for loan approval
\(\rightarrow\) should not unfairly discriminate with gender,ethnicity,language.. ( = protected attributes )
Even if well on test set…
will be unacceptable if it shows a bias/discrimination with those protected attributes!
Ex for challenge 2 ) Product Recommendations from retailers
only recommend HOT-products?? what about minor products…?
\(\rightarrow\) treat fairly all major users/retailers/product categories
Ex3 for challenge 3) skewed data distributions
Medical diagnosis
- most of patients do not have a certain disease ( ex. 99.9% )
- good performance, by just choosing “NO DISEASE”…? no!
Summary
not just to do well on the test set,
but to produce a ML system that meets business goals!
[4] Establish a baseline
first thing to do : “establish a baseline”
then : use tools to efficiently improve on that baseline level!
Example ) speech recognition

\(\rightarrow\) does this mean that we have to focus on “low bandwidth audio”? NO!
should “establish a baseline level” first!
- ex) HLP (Human Level Performance)
- by asking some human transcriptionists to label data & measure accuracy

\(\rightarrow\) Helps us decide where to focus on!
HLP (Human Level Performance)
- less useful baseline for structured data applications
Ways to establish a baseline
- HLP (Human Level Performance)
- Literature search for SOTA/open source
- Quick-and-dirty implementation
- Performance of older system
[5] Tips for getting started
ML is an “iterative process”
[Tip 1] start with a quick literature search!
-
start with a quick literature search to see what’s possible
-
if your goal is “building a practical production system” ( not research )
\(\rightarrow\) don’t obsess about finding the latest, greatest algorithm!!
\(\rightarrow\) rather, find something reasonable that lets you get started quickly!!
( ex. open source implementation )
-
GOOD data + SOSO algorithm > SOSO data + GOOD algorithm
[Tip 2] should we consider deployment constraints?
- YES…
- if the baseline is already established &
- confident that this project will work &
- thus the goal is to build and deploy a system.
- NO…
- if you have not yet even established a baseline
- or unsure it will work
[Tip 3] quick sanity checks
-
before running it on ALL HUGE data, check with FEW data first!
-
advantage :
-
lets you find bugs much more quickly!
-
if not good on “small” dataset,
then probably also not good on “big” dataset also!
-