
( reference : Introduction to Machine Learning in Production )
Data Iteration
[1] Data-centric AI development
2 types of view
- 1) model-centric view
- 2) data-centric view
MODEL-centric view
- develop a model that does well on a “GIVEN data”
- keep improving the code/model
DATA-centric view
-
key point : “QUALITY of data”
\(\rightarrow\) use tools to improve data quality
-
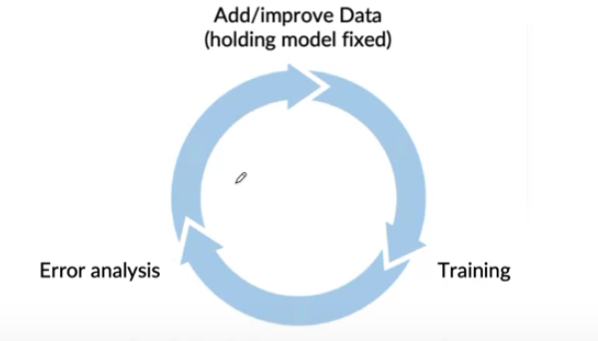
keep code FIXED, and iteratively improve “data”
[2] Useful picture of data augmentation
Data augmentation to help the performance of a model
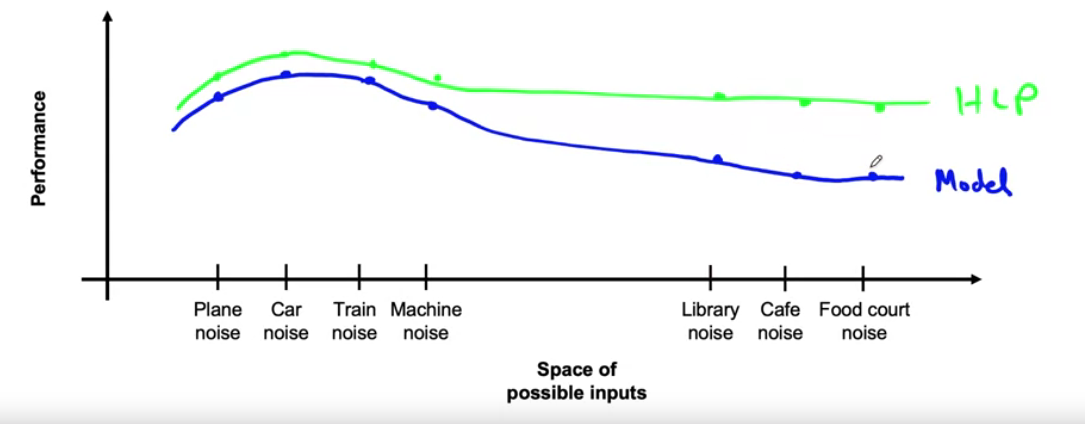
Example ) different types of “speech input data”
- type A) Car / Plane / Train / Machine noise
- type B) Cafe / Library / Food court noise
different peformance & HLP with each category
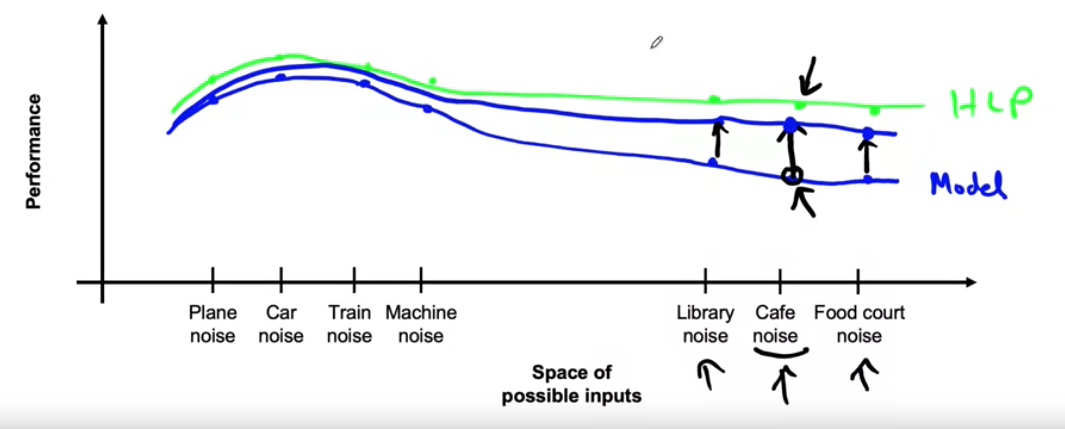
Improvement in certain category ( by data augmentation )
will also improve other categories! ( with different degrees, depending on the similarity )
[3] Data Augmentation
Example) speech recognition
- make synthetic training example, by adding “noise”

Goal of “data augmentation”
create “realistic” examples, that
- 1) the algorithm does “poorly” on,
- 2) but “humans (or other baselines)” do well on
Checklist
-
1) does it sound “realistic”?
-
2) is “mapping \(X \rightarrow Y\) “ clear?
( = can humans recognize it? )
-
3) is the algorithm doing poorly on it now?
Data Iteration Loop
[4] Can adding data hurt?
answer : “depends on the capacity of model”
Unstructured data problems : if
- 1) model is LARGE ( ex. NN )
- 2) mapping \(X \rightarrow Y\) is clear
then “adding data RARELY hurts” the performance!
Counter example : Photo OCR

[5] Adding feature
Structured data problems :
-
data augmentation…?
\(\rightarrow\) creating brand new training examples is difficult!
-
then, do what…?
\(\rightarrow\) figure out if there are additional useful features to add
Example) restaurant recommendations
-
after error analysis, have found that the model was
“recommending to vegetarians restaurants that only had meat options”
-
why not add feature indicating vegetarian? ( hard version )
or, proportion of vegetables of their previous orders? ( soft version )
Data iteration for “structured data problems”
-
step 1) start out with some model & train the model
-
step 2) error analysis
-
( might be harder on structured data problems,
if there is no good baseline ( ex. HLP ) to compare )
-
go back to select some features to add
-

Hand design features are QUITE GOOD!
( only for the case of “structured” dataset )
[6] From big data to good data
Properties of “GOOD” data
- 1) good coverage of input \(x\)
- 2) definition of \(y\) is unambiguous
- 3) distribution covers data/concept drift
- 4) is sized appropriately