
Target-Aspect Sentiment Joint Detection for Aspect-Based Sentiment Analysis (2020)
Contents
- Abstract
- Introduction
- Related Work
- TASD (Target-Aspect-Sentiment Detection)
- Problem Definition
- Problem Reduction
- TAS-BERT Model
0. Abstract
ABSA의 목표 : 아래의 것들을 detect하기
- 1) targets ( ex. 짜장면 )
- 2) aspects ( ex. 음식-맛 / 음식-영양소 )
- 3) sentiment polarities ( 긍/중/부 )
대부분의 현재 존재하는 방법들은 방법 1) or 방법 2)
- 방법 1) target에서 sentiment 찾기
- 방법 2) aspect에서 sentiment 찾기
\(\rightarrow\) 둘 다 에서 sentiment 찾기는 거의 X
( 특히, target이 implicit한 경우 (=text 상에서 등장 X 경우), 방법 1)은 불가능 )
이 논문은 위의 문제들을 풀기 위해..
Target-Aspect sentiment joint detection 을 제안한다
- 특징 1) pre-trained LM 사용
- 특징 2) dependence on both targets & aspects for sentiment 예측
1. Introduction
sentiment 분류의 가장 큰 문제는,
sentiment는 target 과 aspect 둘 다에 모두 depend한다는 점!
( 대부분의 방법론들은 이 dual dependence를 고려하지 못한다 )
위에 대한 solution으로 나온 “TASD” (Target-Aspect Sentiment Detection)
-
핵심 : (target-aspect-sentiment) triple을 찾는 것!
-
이 논문은, 세 요소를 동시에 찾을 것을 제안함! ( using neural-based models )
\(\rightarrow\) Target-Aspect sentiment joint detection
TASD (Target-Aspect sentiment joint detection)
joint detection문제를 2개의 sub-problem으로 나눠서 본다.
-
[sub-problem 1] Target이 존재하는가
\(\rightarrow\) binary classification문제로써 풀 수 있다.
-
[sub-problem 2] 모든 Target을 뽑아내기
\(\rightarrow\) sequence-labeling 문제로써 풀 수 있다.
-
둘 다 BERT 사용하여 풀고, 이 둘의 loss function을 combine하여 optimize한다.
Contributions
- 1) capture dual dependence & handle implicit target
- 2) BERT 기반으로 모델링한 알고리즘으로 target-aspect sentiment를 jointly predict
2. Related Work
TASD (Target-Aspect sentiment joint detection)의 5가지 sub-tasks
- ASD, TSD, TAD,AD,TD
- ASD (Aspect Sentiment Detection)
- aspect & sentiment를 simultaneously detect
- ex) end-to-end CNN model
- ex) binary classification 문제로 바꿔 품
- TSD (Target Sentiment Detection)
- jointly detect target & sentiment
- ex) sequence labeling 문제로 바꿔 품
- ex) with CRF decoder / two stacked LSTM / dual cross-shared RNN
- TAD (Target Aspect Detection)
- detect target & aspect together
- 많이 다뤄지지 X
-
AD (Aspect Detection)
- TD (Target Detection)
위의 5가지 task들 모두 dual dependence (of sentiment&target, sentiment&aspect)를 잡아내진 못해
TASD만이 그럴 수 있다!
-
jointly detect (target-aspect-sentiment) triples
-
기존에도 이를 사용한 방법이 있었으나, rely on available parsers & domain-specific semantic lexicons
3. TASD (Target-Aspect-Sentiment Detection)
3-1) Problem Definition
Notation
- 문장 : \(S\)
- 문장 내의 \(n\)개 단어 : \(s_{1}, \ldots, s_{n}\)
- \(A\) : pre-defined set of aspect
- \(P\) : pre-defined set of sentiment polarities
- \(t\) : target ( = subsequence of \(S\) )
- Implicit target : \(t\) 가 empty ( = NULL )
\(\rightarrow\) TASD의 목표 : \((t,a,p)\) 찾기……… 이 triple을 OPINION이라고 부른다
Example
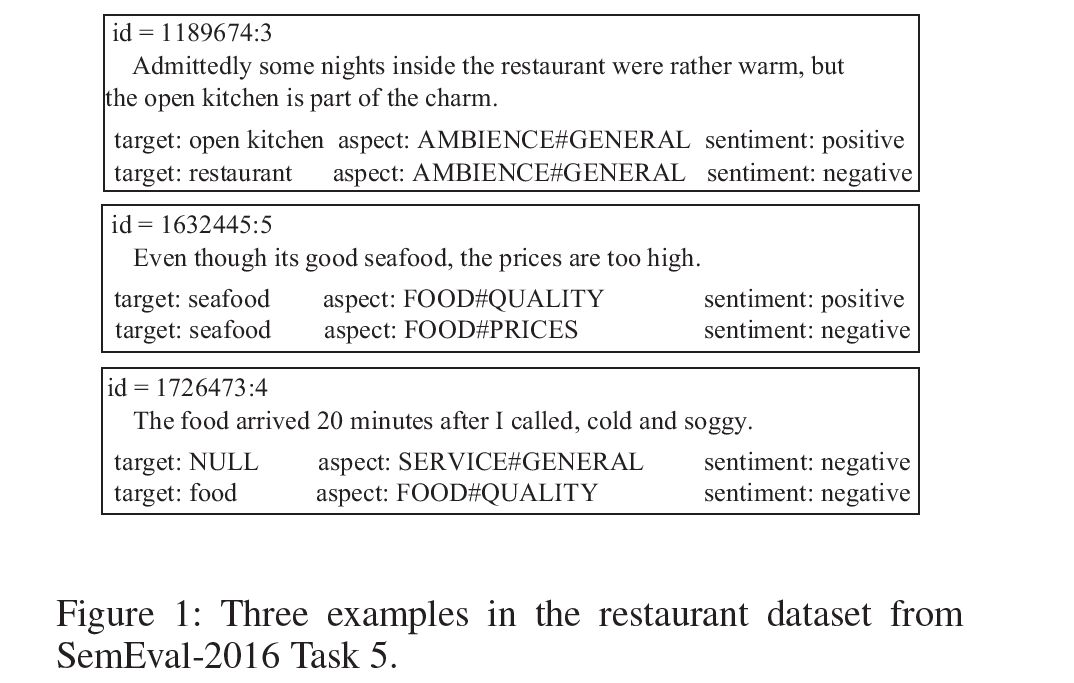
Q. 여기서 id = 1726473:4d의 Opinion은?
- opinion 1) (NULL, SERVICE#GENERAL, negative)
- opinion 2) (food, FOOD#QUALITY, negative)
3-2) Problem Reduction
이 논문은 TASD 문제를 두 문제로 reduce해서 푼다.
- **1) text classification **
- target이 존재하는가? ( binary classfication )
- 2) sequence labeling
- extract target ( BIO tagging, TO tagging )
위 두 sub-problems들의 결과를 합침으로서 opinion을 얻어낼 수 있다.
(간단한 소개)
-
input : Sentence \(S\) & (aspect-sentiment pair) \((a,p)\)
-
sub-problem 1)
-
\(t\)가 없을 경우 (output=0) : \((t,a,p)\) 꼴로 나올 수 없다
-
\(t\)가 있을 경우 (output=1) :
-
\(n=0\) : implicit …. \((NULL,a,p)\) ( 총 1개의 opinion )
-
\(n>1\) : explicit ….. \((t,a,p)\) ( 총 \(n\)개의 opinions )
( 여기서 sub-problem 2 풀기 )
-
-
3-3) TAS-BERT Model
제안된 (BERT 기반) 모델의 5가지 component
-
1) 2개의 FC layers
-
2) Softmax decoder ( for binary classification )
-
3-1) CRF decoder ( for sequence labeling )
3-2) Softmax decoder ( for sequence labeling )
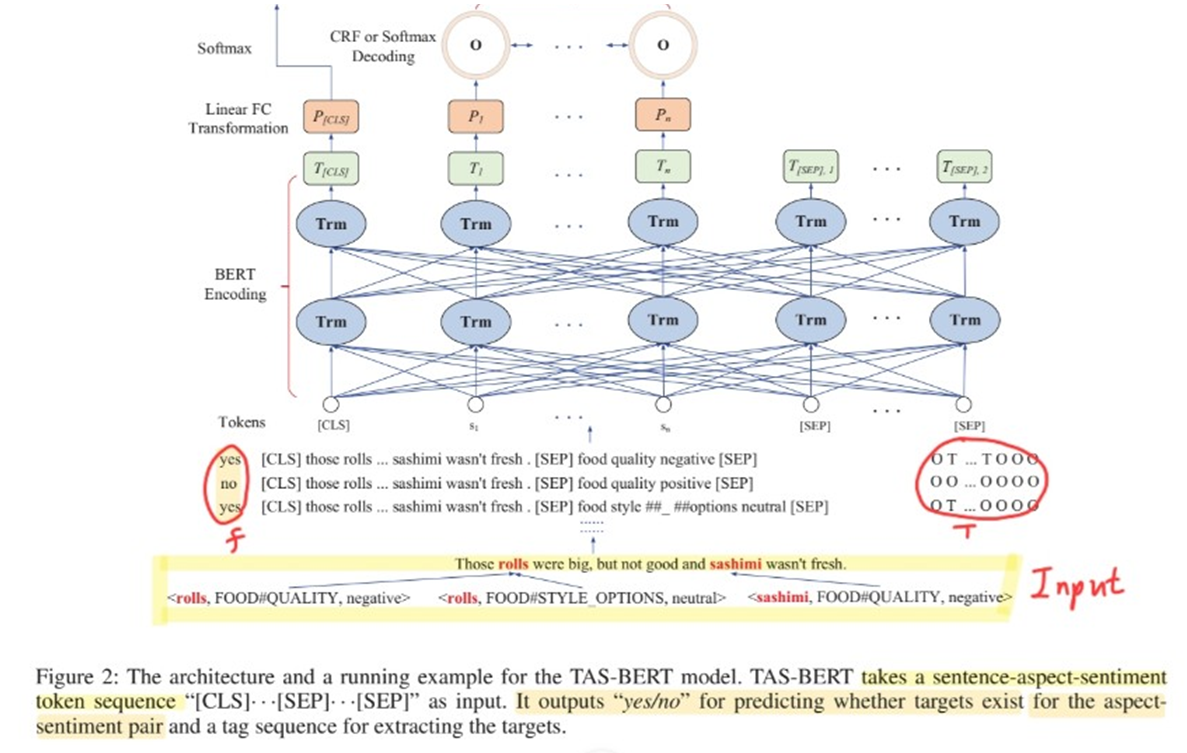
TASD task의 training set : sentence-opinion pairs
- 이를 전처리하여, \((S, a, p, f, \mathbf{T})\) 형태로 만들어줘야!
- \(f\) : yes/no label
- \(\mathbf{T}\) : sequence of labels ( BIO / TO 태깅 )
어떻게 \(f, \mathbf{T}\)를 만들지?
- Suppose \(\left(t_{1}, a, p\right), \ldots,\left(t_{k}, a, p\right)\) are all opinions corresponding to \(S\) in the training set
- If \(k=0\)…
- \(f\)를 “no”로! ( target이 없으니까 )
- \(\mathbf{T}\)는 전부 \(O\)-label로 ( length = n )
- If \(k\neq0\) …
- \(f\) 를 “yes”로 ( target이 1개 이상 있으니까 )
- \(k\)개의 target들 (\(t_1,..t_k\))를 label sequence \(\mathbf{T}\)로 encoding
- implicit target이 있다면, 그건 항상 맨 마지막으로! (\(t_k\)로 설정하기)
- \(t_k=t_1\)일 경우 ( 즉, 1개의 target만이 존재하고 그게 implicit일 경우 ) \(\mathbf{T}\)는 전부 \(O\)-label로
Training phase
-
given \((S, a, p, f, \mathbf{T})\)…
-
(step 1) \(n+m+4\)개의 token sequence 만들기
- “[CLS], \(s_{1}, \cdots, s_{n},[\mathrm{SEP}], a_{1}, \cdots, a_{m}, p,[\mathrm{SEP}] "\) .
-
(step 2) fed into BERT
-
\(T_{s_{1}}, \ldots, T_{s_{n}}, T_{[S E P], 1}, T_{a_{1}}, \ldots, T_{a_{m}}, T_{p}, T_{[S E P], 2}\).
- 여기서 first vector \(T_{[CLS]}\) 는 yes/no를 predict하는데에 사용
- \(\begin{aligned} P_{[C L S]} &=\tanh \left(W_{1} T_{[C L S]}+b_{1}\right) \\ g &=\operatorname{softmax}\left(P_{[C L S]}\right) \end{aligned}\).
- 나머지 그 이후 vector들은 label sequence를 predict하는데에 사용
- \(P_{s_{i}}=\tanh \left(W_{2} T_{s_{i}}+b_{2}\right)\).
- 여기서 first vector \(T_{[CLS]}\) 는 yes/no를 predict하는데에 사용
-
Loss Function
(1) Binary Classifcation loss
- \(\operatorname{loss}_{\mathrm{g}}=-\sum_{i=1}^{2} I(\mathrm{yn}(i)=f) \log \left(g_{i}\right)\).
(2) Sequence Labeling Loss
-
CRF decoder 사용 시
\(\operatorname{loss}_{\mathrm{h}}=-\log (p(\mathbf{T} \mid \mathbf{P}))\).
-
Softmax decoder 사용 시
\(\text { loss }_{\mathrm{h}}=-\sum_{i=1}^{n} \sum_{j=1}^{o} I\left(\operatorname{map}(j)=t_{i}\right) \log \left(h_{i j}\right)\).
(3) Total loss
- \(\text { loss }=\sum_{i=1}^{N} \operatorname{loss}_{\mathrm{g}}^{i}+\operatorname{loss}_{\mathrm{h}}{ }^{i}\).