
Code Review for BERT
참고 : https://github.com/frankaging/Quasi-Attention-ABSA/blob/main/code/model/BERT.py
1. Architecture
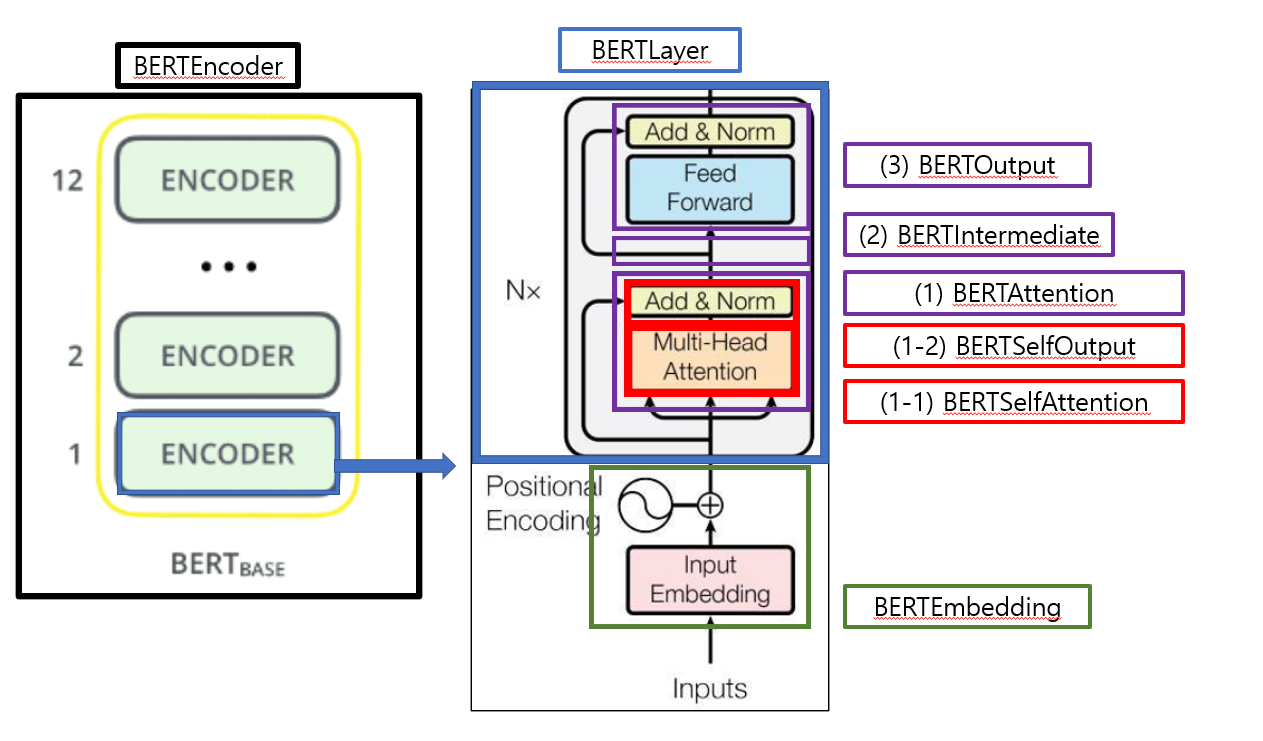
BERTModel
-
(1) BERTEmbedding
-
(2) BERTEncoder x N
- 2-1) BERT Attention
- a) BERT Self-Attention
- b) BERT Self-Output
- 2-2) BERT Intermediate
- 2-3) BERT Output
- 2-1) BERT Attention
2. Class & Function introduction
1) Main Modules
Model : BERTModel
-
BERT Embedding :
BERTEmbedding -
Encoder :
BERTEncoder- Bert layer :
BERTLayer- Attention :
BERTAttention- Self Attention :
BERTSelfAttention - Self Attention output :
BERTSelfOutput
- Self Attention :
- Intermediate layer :
BERTIntermediate - Output layer :
BERTOutput
- Attention :
- Bert layer :
2) Functions / Other Classes
- GeLU :
gelu - Layer Normalization :
BERTLayerNorm - Pooler :
BERTPooler
3. Code Review (with Pytorch)
3-1) Main Modules
BertModel
전체적인 BERT의 알고리즘
-
Step 1) attention_mask : 패딩 마스크 생성
( 문장별로 단어 길이 다른것을 감안해주기 위함 )
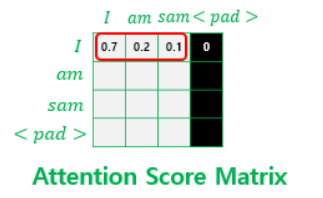
-
Step 2) 세 종류의 embedding을 더함
( 세 종류의 embedding은 아래에 구체적으로 설명 )
-
Step 3) \(L\)개의 Encoder Layer를 통과
- 그 안에 Self Attention / FFNN 등으로 구성
-
Step 4) Pooling
class BertModel(nn.Module):
def __init__(self, config: BertConfig):
super(BertModel, self).__init__()
self.embeddings = BERTEmbeddings(config)
self.encoder = BERTEncoder(config)
self.pooler = BERTPooler(config)
def forward(self, input_ids, token_type_ids=None, attention_mask=None):
if attention_mask is None:
attention_mask = torch.ones_like(input_ids)
if token_type_ids is None:
token_type_ids = torch.zeros_like(input_ids)
# Step 1) attention mask 생성
### 3D attention mask 생성 ( from 2D attention mask )
### mask의 size = [배치 크기, 1, 1, 문장 길이]
extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
extended_attention_mask = extended_attention_mask.float()
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
# Step 2) 세 종류의 embedding을 더함
embedding_output = self.embeddings(input_ids, token_type_ids)
# Step 3) L개의 (Transformer) Encoder layer 를 거침
all_encoder_layers = self.encoder(embedding_output, extended_attention_mask)
# Step 4) (맨 마지막 L번째 layer output 제외하고) Pooling
sequence_output = all_encoder_layers[-1]
pooled_output = self.pooler(sequence_output)
return all_encoder_layers, pooled_output
BERT Embedding
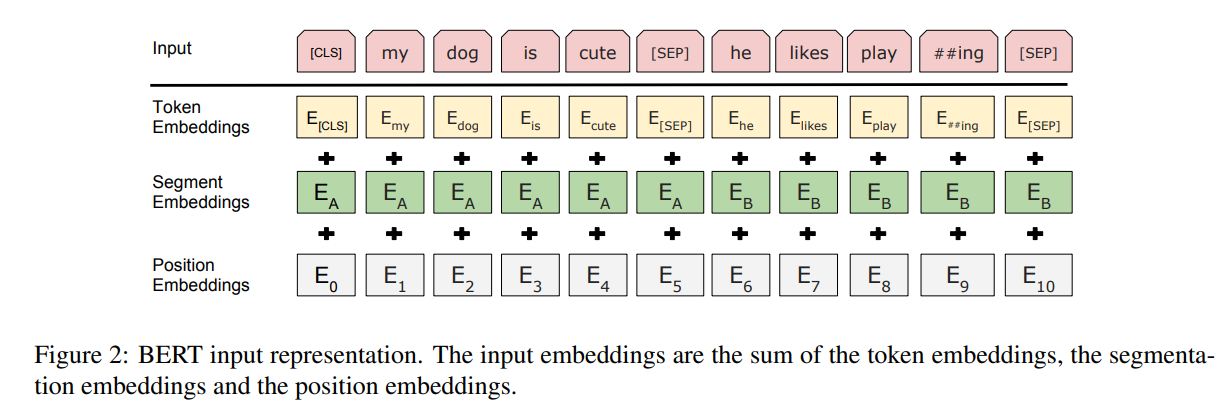
세 종류의 embedding 을 모두 더한다! ( \(h\) 차원 )
-
1)
word_embeddings: Token Embeddings ….. Embedding ( in = Vocab 개수, out = \(h\)) -
2)
position_embeddings: Position Embeddings ….. Embedding ( in = 최대 문장 길이, out = \(h\) ) -
3)
token_type_embeddings: Token Type Embeddings ….. Embedding ( in = Vocab type 개수, out =\(h\) )( default가 16인걸 보면, token의 종류 ex. 명사/동사/접두사/접미사 등… 일듯? )
class BERTEmbeddings(nn.Module):
def __init__(self, config):
super(BERTEmbeddings, self).__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
self.LayerNorm = BERTLayerNorm(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, input_ids, token_type_ids=None):
# (1) Position embedding을 위한 (문장의 token 길이만큼의) index 생성
seq_length = input_ids.size(1)
position_ids = torch.arange(seq_length, dtype=torch.long, device=input_ids.device)
position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
if token_type_ids is None:
token_type_ids = torch.zeros_like(input_ids)
# (2) 세 종류의 Embedding을 더함
words_embeddings = self.word_embeddings(input_ids)
position_embeddings = self.position_embeddings(position_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = words_embeddings + position_embeddings + token_type_embeddings
# (3) Layer Normalization + Dropout
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
BERT Encoder
class BERTEncoder(nn.Module):
def __init__(self, config):
super(BERTEncoder, self).__init__()
layer = BERTLayer(config)
self.layer = nn.ModuleList([copy.deepcopy(layer) for _ in range(config.num_hidden_layers)])
def forward(self, hidden_states, attention_mask):
all_encoder_layers = []
for layer_module in self.layer:
hidden_states = layer_module(hidden_states, attention_mask)
all_encoder_layers.append(hidden_states)
return all_encoder_layers
[A] BERT Layer
다음의 세가지를 차례로 통과함
- 1) Attention layer
- 2) Intermediate layer ( FFNN )
- 3) Output layer
class BERTLayer(nn.Module):
def __init__(self, config):
super(BERTLayer, self).__init__()
self.attention = BERTAttention(config)
self.intermediate = BERTIntermediate(config)
self.output = BERTOutput(config)
def forward(self, hidden_states, attention_mask):
attention_output = self.attention(hidden_states, attention_mask)
intermediate_output = self.intermediate(attention_output)
layer_output = self.output(intermediate_output, attention_output)
return layer_output
[A-1] BERT Attention
- (B-1-a) Self Attention을 수행하고, 여기서 나온 결과값을 (B-1-b) Dense Layer / Layer Normaliaztion 등을 통과시킴
class BERTAttention(nn.Module):
def __init__(self, config):
super(BERTAttention, self).__init__()
self.self = BERTSelfAttention(config)
self.output = BERTSelfOutput(config)
def forward(self, input_tensor, attention_mask):
self_output = self.self(input_tensor, attention_mask)
attention_output = self.output(self_output, input_tensor)
return attention_output
[A-1-a] Self Attention
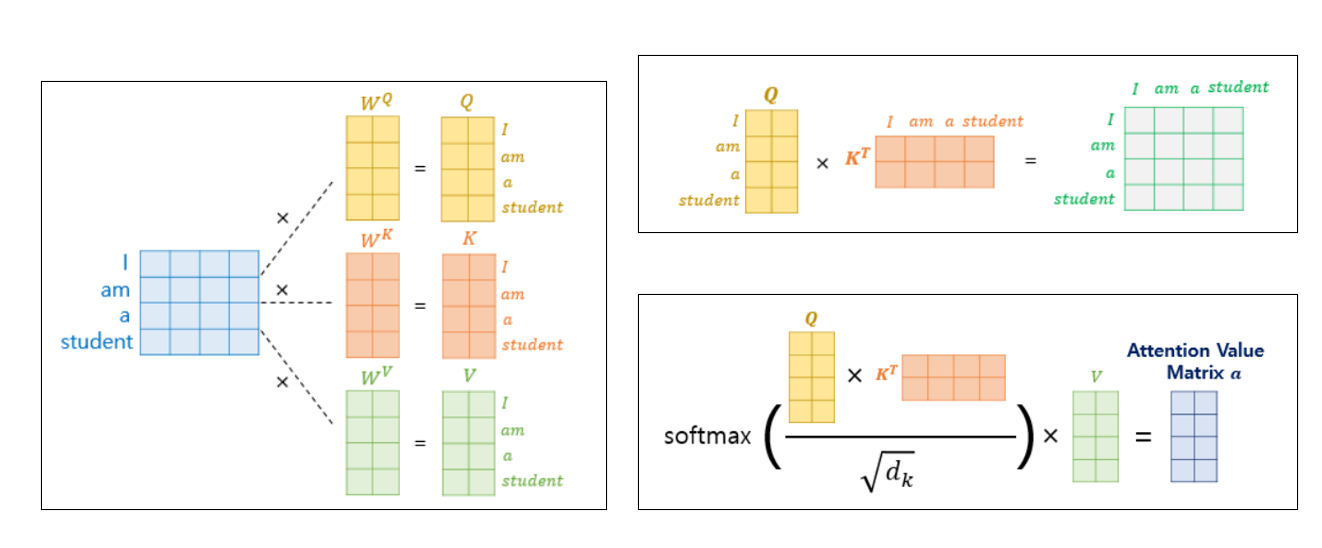
( 출처 : wikidocs 자연어 처리를 위한 딥러닝 )
\(\operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V\).
-
num_attention_heads: attention head의 개수 -
attention_head_size: attention head 1개 당의 dimension -
ex) hidden dimension \(h\) =100 & attention head의 개수 = \(5\)
\(\rightarrow\) attention head size = \(20\)
\(\rightarrow\) all head size = \(5 \times 20 = 100\)
\(Q\), \(K\),\(V\) 얻어내기 위한 weight ( = \(W_Q,W_K,W_V\) ) 의 dimension : \(h \times \text{all head size}\) ( = \(100 \times 100\) )
- \(Q\) , \(K\), \(V\) 모두 결국엔 all_head_size (=100) 차원
class BERTSelfAttention(nn.Module):
def __init__(self, config):
super(BERTSelfAttention, self).__init__()
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.Wq = nn.Linear(config.hidden_size, self.all_head_size)
self.Wk = nn.Linear(config.hidden_size, self.all_head_size)
self.Wv = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(self, hidden_states, attention_mask):
Q = self.Wq(hidden_states)
K = self.Wk(hidden_states)
V = self.Wv(hidden_states)
Q = self.transpose_for_scores(Q)
K = self.transpose_for_scores(K)
V = self.transpose_for_scores(V)
## Attention 계산하기 (A)
## (attention 방식) Dot Product
attention_scores = torch.matmul(Q, K.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
attention_scores = attention_scores + attention_mask
A = nn.Softmax(dim=-1)(attention_scores)
A = self.dropout(A)
## context layer 계산하기 ( A x V )
context_layer = torch.matmul(A, V)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
return context_layer
[A-1-b] Self Attention Output
class BERTSelfOutput(nn.Module):
def __init__(self, config):
super(BERTSelfOutput, self).__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.LayerNorm = BERTLayerNorm(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
[A-2] Intermediate Layer
- Transformer의 Encoder 그림에는 따로 존재하지 않지만 추가한 듯?
class BERTIntermediate(nn.Module):
def __init__(self, config):
super(BERTIntermediate, self).__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
self.intermediate_act_fn = gelu
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
[A-3] Output Layer
class BERTOutput(nn.Module):
def __init__(self, config):
super(BERTOutput, self).__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
self.LayerNorm = BERTLayerNorm(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
3-2) Functions / Other Classes
GeLU
\(\operatorname{GELU}(x)=0.5 x\left(1+\tanh \left(\sqrt{2 / \pi}\left(x+0.044715 x^{3}\right)\right)\right)\).
def gelu(x):
return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
Layer Normalization
\(\begin{aligned} \mu_{i} &=\frac{1}{m} \sum_{j=1}^{m} x_{i j} \\ \sigma_{i}^{2} &=\frac{1}{m} \sum_{j=1}^{m}\left(x_{i j}-\mu_{i}\right)^{2} \\ \hat{x_{i j}} &=\gamma \cdot \frac{x_{i j}-\mu_{i}}{\sqrt{\sigma_{i}^{2}+\epsilon}} + \beta \end{aligned}\).
- \(\gamma\) : scaling parameter
- \(\beta\) : shift parameter
class BERTLayerNorm(nn.Module):
def __init__(self, config, variance_epsilon=1e-12):
super(BERTLayerNorm, self).__init__()
self.gamma = nn.Parameter(torch.ones(config.hidden_size))
self.beta = nn.Parameter(torch.zeros(config.hidden_size))
self.variance_epsilon = variance_epsilon
def forward(self, x):
mu = x.mean(-1, keepdim=True)
std = (x - mu).pow(2).mean(-1, keepdim=True)
x = (x - mu) / torch.sqrt(std + self.variance_epsilon)
return self.gamma * x + self.beta
BERTPooler
- 첫번째 [CLS] 토큰만을 대상으로 수행
- Dense Layer & Activation Function을 거처서 출력됨
class BERTPooler(nn.Module):
def __init__(self, config):
super(BERTPooler, self).__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states):
CLS_token = hidden_states[:, 0]
pooled_output = self.activation(self.dense(CLS_token))
return pooled_output
[ Configuration ]
Configuration class to store the configuration of a BertModel
( 괄호 안의 값은 default 값 )
- vocab_size : Vocabulary의 개수
- hidden_size : encoder layers and the pooler layer의 hidden dimension (768)
- num_hidden_layers : Encoder의 hidden layer의 개수 (12)
- num_attention_heads : attention head의 개수 (12)
- intermediate_size : intermediate layer (FFNN)의 dimension (3072)
- hidden_act : encoder ( & pooler )에서 사용되는 activation function (gelu)
- hidden_dropout_prob : dropout probability (0.1)
- max_position_embeddings : 최대 문장 길이 (512)
- type_vocab_size : token_type_ids의 vocab 개수 (16)
- initializer_range : weight를 initialize할때의 사용하는 Truncated Normal distn의 standard deviation (0.02)
class BertConfig(object):
def __init__(self,
vocab_size,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=16,
initializer_range=0.02):
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.hidden_act = hidden_act
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.initializer_range = initializer_range
#----------------------------------------------------------#
#-- Configuration을 [dictionary] 형태로 받은 뒤 Setting하기 --#
#----------------------------------------------------------#
## [ Dictionary ] 형태
@classmethod
def from_dict(cls, json_object):
config = BertConfig(vocab_size=None)
for (key, value) in six.iteritems(json_object):
config.__dict__[key] = value
return config
## [ Json ] 형태
@classmethod
# Configuration을 dictionary형태로 받은 뒤 Setting하기
def from_json_file(cls, json_file):
with open(json_file, "r") as reader:
text = reader.read()
return cls.from_dict(json.loads(text))
def to_dict(self):
output = copy.deepcopy(self.__dict__)
return output
def to_json_string(self):
return json.dumps(self.to_dict(), indent=2, sort_keys=True) + "\n"