
Sequences, Time Series and Prediction
( 참고 : coursera의 Sequences, Time Series and Prediction 강의 )
[ Week 4 ] Real-world Time Series Data
- Import Packages
- Load Dataset
- Preprocess Dataset
- Modeling
- Prediction
1. Import Packages
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
2. Load Dataset
Download dataset
Sunspots.csv
!gdown --id 1bLnqPgwoSh6rHz_DKDdDeQyAyl8_nqT5
Load dataset
import csv
time_step = []
sunspots = []
with open('./Sunspots.csv') as csvfile:
reader = csv.reader(csvfile, delimiter=',')
next(reader)
for row in reader:
sunspots.append(float(row[2]))
time_step.append(int(row[0]))
print(len(time_step),len(sunspots))
print(time_step)
print(sunspots[0:10])
series = np.array(sunspots)
time = np.array(time_step)
3235 3235
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[96.7, 104.3, 116.7, 92.8, 141.7, 139.2, 158.0, 110.5, 126.5, 125.8]
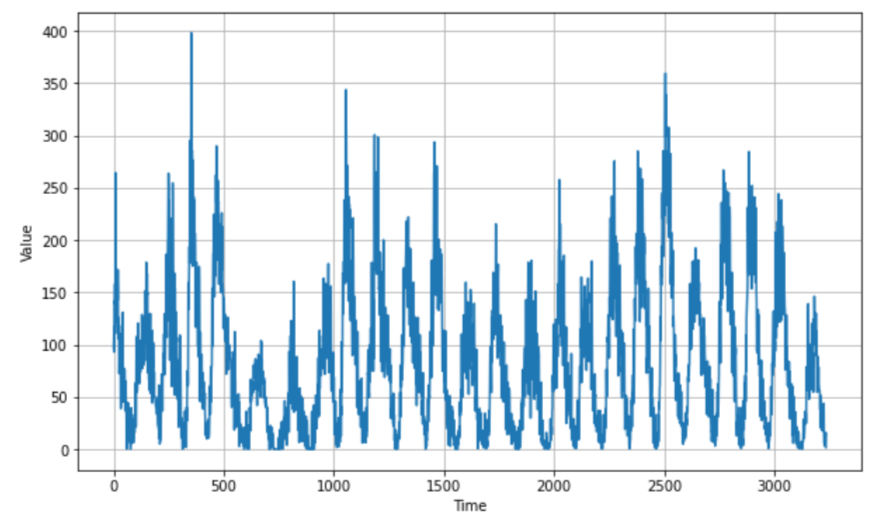
Visualization
plt.figure(figsize=(10, 6))
plot_series(time, series)
3. Preprocess Dataset
Train & Validation Split
split_time = 3000
time_train = time[:split_time]
x_train = series[:split_time]
time_valid = time[split_time:]
x_valid = series[split_time:]
print(time_train.shape)
print(x_train.shape)
print(time_valid.shape)
print(x_valid.shape)
(3000,)
(3000,)
(235,)
(235,)
Make Windowed dataset
( windowed_dataset 함수 복습 )
def windowed_dataset(series, window_size, batch_size, shuffle_buffer):
series = tf.expand_dims(series, axis=-1)
ds = tf.data.Dataset.from_tensor_slices(series)
ds = ds.window(window_size + 1, shift=1, drop_remainder=True)
ds = ds.flat_map(lambda w: w.batch(window_size + 1))
ds = ds.shuffle(shuffle_buffer)
ds = ds.map(lambda w: (w[:-1], w[1:]))
return ds.batch(batch_size).prefetch(1)
tf.keras.backend.clear_session()
tf.random.set_seed(51)
np.random.seed(51)
window_size = 64
batch_size = 256
train_set = windowed_dataset(x_train, window_size, batch_size, shuffle_buffer_size)
4. Modeling
다음 3 종류의 layer를 통과한다
- 1D convolution
- LSTM
- Dense
model = tf.keras.models.Sequential([
tf.keras.layers.Conv1D(filters=32, kernel_size=5,
strides=1, padding="causal",
activation="relu",
input_shape=[None, 1]),
tf.keras.layers.LSTM(64, return_sequences=True),
tf.keras.layers.LSTM(64, return_sequences=True),
tf.keras.layers.Dense(30, activation="relu"),
tf.keras.layers.Dense(10, activation="relu"),
tf.keras.layers.Dense(1),
tf.keras.layers.Lambda(lambda x: x * 400)
])
lr_schedule = tf.keras.callbacks.LearningRateScheduler(
lambda epoch: 1e-8 * 10**(epoch / 20))
optimizer = tf.keras.optimizers.SGD(learning_rate=1e-8, momentum=0.9)
model.compile(loss=tf.keras.losses.Huber(),
optimizer=optimizer,
metrics=["mae"])
history = model.fit(train_set, epochs=5, callbacks=[lr_schedule])
5. Prediction
모델 & 데이터 & window size가 주어졌을 때, prediction result를 반환하는 함수
tf.data.Dataset.from_tensor_slices: list/array로부터 dataset 만들 때!
def model_forecast(model, series, window_size):
ds = tf.data.Dataset.from_tensor_slices(series)
ds = ds.window(window_size, shift=1, drop_remainder=True)
ds = ds.flat_map(lambda w: w.batch(window_size))
ds = ds.batch(32).prefetch(1)
forecast = model.predict(ds)
return forecast
rnn_forecast = model_forecast(model, series[..., np.newaxis], window_size)
print(len(rnn_forecast))
rnn_forecast = rnn_forecast[split_time - window_size:-1, -1, 0]
print(len(rnn_forecast))
(3172, 235)