
참고 : Do it! BERT와 GPT로 배우는 자연어처리
1. 처음 만나는 자연어 처리
NLP Task
- 1) Document Classification ( 문서 분류 )
- 2) Sentence Pair Classification ( 문서 쌍 분류 )
- 3) Named Entity Recognition ( 개체명 인식 )
- 4) Question Answering ( 질의 응답 )
- 5) Sentence Generation ( 문장 생성 )
Transfer Learning ( 전이 학습 )
- “knowledge transfer” ( 지식 전이 )
- task A를 학습한 모델을, task B를 수행하는데에 재사용
- task A : UP-stream task ( ex. 다음 단어 맞히기, 빈칸 채우기 )
- task B : DOWN-stream task ( ex. 앞서 말한 5개의 task )
- “PRE-train” = task A를 학습하는 과정
- 장점 : 학습속도 fast
- ex) BERT, GPT
Upstream Task
- 핵심 : 텍스트의 “문맥 (context)”를 모델에 내재화
- Task example
- 1) “다음 단어 맞히기”
- Language Model (LM)
- ex) GPT 계열
- 2) “빈칸 채우기”
- Masked Language Model (MLM)
- ex) BERT 계열
- 1) “다음 단어 맞히기”
- 특징 : “SELF-supervised learning” ( 자기지도 학습 )
Downstream Task
- 우리가 풀어야 할 구체적인 NLP 과제들
- 본질 : “CLASSIFICATION”
- 학습 방식 : “fine-tuning”
- step 1) pre-train을 완료한다
- step 2) downstream task에 맞게 모델을 업데이트
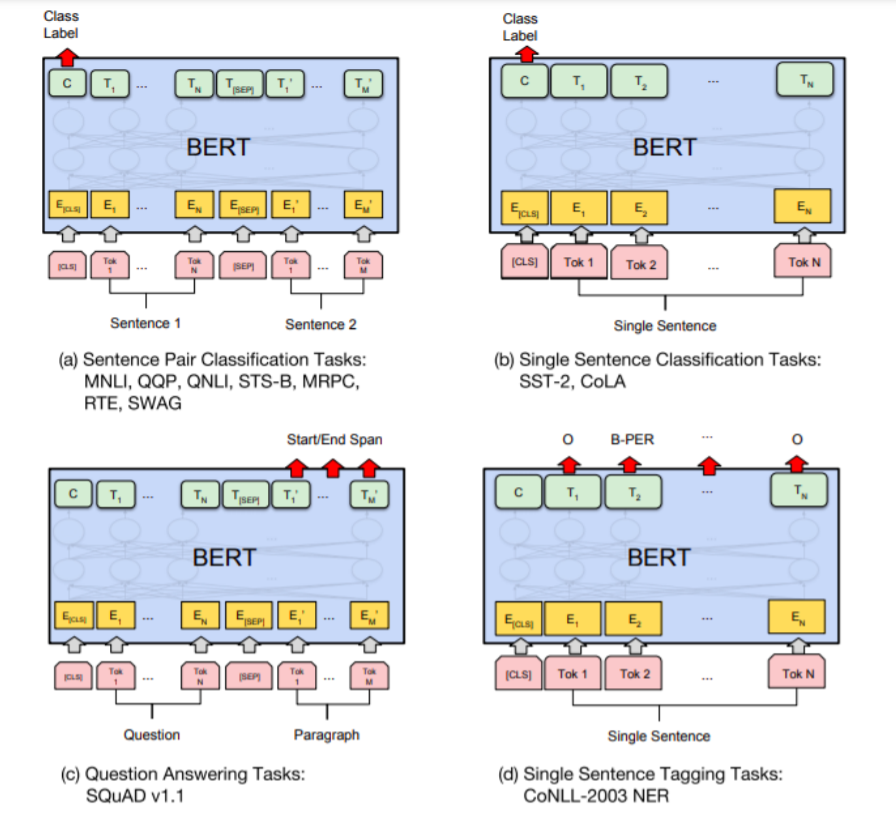
- example)
- Document Classification ( 문서 분류 )
- ex) 감성 분석 : “문서/문장”을 입력으로 받아 “긍정/중립/부정”을 예측
- Sentence Pair Classification ( 문서 쌍 분류 )
- ex) 자연어 추론 ( Natural Language Inference ) : “문장 2개”의 관계가 “참/거짓/중립”을 예측
- Named Entity Recognition ( 개체명 인식 )
- “문서/문장”을 입력으로 받아, 모든 토큰이 “어떠한 개체명 범주”에 속하는지 예측
- 개체명 범주 ex) 기관명 / 인명 / 지명
- Question Answering ( 질의 응답 )
- “지문+질문”을 입력으로 받아, “각 단어가 ‘정답의 시작/끝’일 확률”을 예측
- Sentence Generation ( 문장 생성 )
- “단어/문장”을 입력으로 받아, “다음 올 단어” 예측
- (참고) GPT 계열 언어모델이 이에 능함
- Document Classification ( 문서 분류 )
Language Model 학습 파이프라인
-
상황 : pre-train된 모델 존재하고 & 풀고자하는 downstream task의 데이터가 있다
- step 1) 각종 설정값 지정
- step 2) 데이터 내려받기
- step 3-1) pre-train된 모델 준비
- step 3-2) pre-train할때 썼던 tokenizer 준비
- step 4) data loader 생성
- step 5) task 정의
- step 6) 모델 학습
사용할 패키지 : ratsnlp ( github.com/ratsgo/ratsnlp )
step 1) 각종 설정값 지정
pretrained_model_name: 어떤 pre-train 모델 사용할지downstream_corpus_name: 어떤 data 사용할지downstream_corpus_root_dir: 결과는 어디에 저장할지 등learning_rate,batch_size: learning rate, batch size 등
from ratsnlp.nlpbook.classification import ClassificationTrainArguments
args = ClassificationTrainArguments(
pretrained_model_name = 'beomi/kcbert-base',
downstream_corpus_name = 'nsmc',
downstream_corpus_root_dir = 'root/Korpora',
downstream_model_dir = '/gdrive/My Drive/nlpbook/checkpoint-doccls',
learning_rate = 5e-5,
batch_size = 32
)
step 2) 데이터 내려받기
- down-stream task를 수행할 데이터를 준비한다
- ex) NSMC (Naver Sentiment Movie Corpus)
from Korpora import Korpora
Korpora.fetch(
corpus_name = args.downstream_corpus_name, # 'nsmc' 데이터를
root_dir = args.downstream_corpus_root_dir, # 'root/Korpora'에 저장함
force_download = True
)
step 3-1) pre-train된 모델 준비
-
transformers패키지 : 트랜스포머 계열의 모델 -
사용할 모델 :
kcbert-base( ‘beomi/kcbert-base’ : huggingface에 등록되어 있어야 )
from transformers import BertConfig
from transformers import BertForSequenceClassification # task : 문서 분류
pretrained_model_config = BertConfig.from_pretrained(
args.pretrained_model_name, # 'beomi/kcbert-base'
num_labels = 2
)
model = BertForSequenceClassification.from_pretrained(
args.pretrained_model_name, # 'beomi/kcbert-base'
config = pretrained_model_config
)
step 3-2) pre-train할때 썼던 tokenizer 준비
- tokenizer의 대표적 알고리즘 : BPE, wordpiece
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained(
args.pretrained_model_name, # 'beomi/kcbert-base'
do_lower_case = False
)
step 4) data loader 생성
-
data loader 안에 dataset을 넣어준다
-
batch 단위로 모델에 넣어주기 위해!
- batch의 크기 : “고정적” ( 패딩해서 맞춰줘야 )
-
collate : 모델의 최종 입력 형태로 만들어줌
- ex) list를 tensor로 변환하는 과정
-
(참고) 모델의 입력은 “벡터”가 아니라 “정수 index”
( tokenizing 과정에서 함께 수행된다 )
from torch.utils.data import DataLoader, RandomSampler
from ratsnlp.nlpbook.classification import NsmcCorpus, ClassificationDataset
corpus = NsmcCorpus()
train_dataset = ClassificationDataset(
args = args,
corpus = corpus,
tokenizer = tokenizer,
model = 'train'
)
train_dataloader = DataLoader(
train_dataset,
batch_size = args.batch_size,
sampler = RandomSampler(train_dataset, replacement = False),
collate_fn = nlpbook.data_collator,
drop_last = False,
num_workers = args.cpu_workers
)
step 5) 태스크 정의
pytorch lightning라이브러리 사용- 반복적인 내용을 대신 수행해줌
- only 모델 구축에만 신경쓰기!
lightning모듈을 상속 받아서 task- task 안에는..
- 1) 모델
- 2) 최적화 방법
- 3) 학습과정 등
from ratsnlp.nlpbook.classification import ClassificationTask
task = ClassificationTask(model, args)
step 6) 모델 학습하기
- trainer 함수 정의
- trainer fitting
trainer = nlpboook.get_trainer(args)
trainer.fit(
task,
train_dataloader = train_dataloader
)