
Pytorch 성능 개선
Contents
- DataLoader의
num_workers - DataLoader의
pin_memory - CPU & GPU transfer
- Construct tensors directly on GPU
- DP & DDP
- Reproducibility
- ` torch.cuda.empty_cache()`
- ` model.eval()
vstorch.no_grad()` nn.Dropoutvs.F.dropout
1. DataLoader의 num_workers
1-1. 사용 방법
from torch.utils.data import DataLoader
dl = DataLoader(dataset, num_workers=8)
1-2. (pytorch) 공식 문서
https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader
num_workers (int, optional) – how many subprocesses to use for data loading. 0 means that the data will be loaded in the main process. (default: 0)
1-3. 직관적인 해석
[Background] for GPU usage…
- 데이터를 GPU로 load 해야함!
- CPU 일정한 데이터 전처리 과정을 거친 후, GPU로 load해줌
DataLoader의 num_workers
-
역할 : data를 CPU에서 GPU로 load하는 workers
-
worker”s” : 여러 process를 동시에 올릴 수 있음
( = data load “multi”-processing )
요약 :
-
CPU에서 필요한 작업을 빠르게 처리하고, GPU로 넘겨줘야함.
그래야 GPU 사용률을 높일 수 있음
-
“CPU에서 필요한 작업을 빠르게 처리”
\(\rightarrow\) 단일 core가 아닌 멀티 core로 처리하기!
= 그것이 바로
num_workers
Question : 그렇다면, 무조건 많은 CPU 코어를 할당해주는 것이 좋지 않을까?
\(\rightarrow\) NO! 다른 부가적인 처리에 delay
따라서 적당한 개수를 지정해줄 필요가 있고, 일반적으로 GPU 개수 x 4개 사용
2. DataLoader의 pin_memory
2-1. 사용 방법
from torch.utils.data import DataLoader
dl = DataLoader(dataset, pin_memory=True)
2-2. 내용
CPU \(\rightarrow\) GPU 데이터 전송 위해 “통신”이 필요함.
이들 간의 통신 또한 Process이므로, CPU 메모리를 필요로 함.
pin_memory=True : 이 메모리를 일정량 확보해둔다는 뜻
\(\rightarrow\) CPU에서 GPU 데이터 전송속도 faster
( but 데이터양이 작으면, 해당 효과는 미미 )
한 줄 요약 :
- CPU → GPU 복사는 pin memory에서 생성 될 때 훨씬 빠르곡, 이를 위한 것이
pin_memory = True
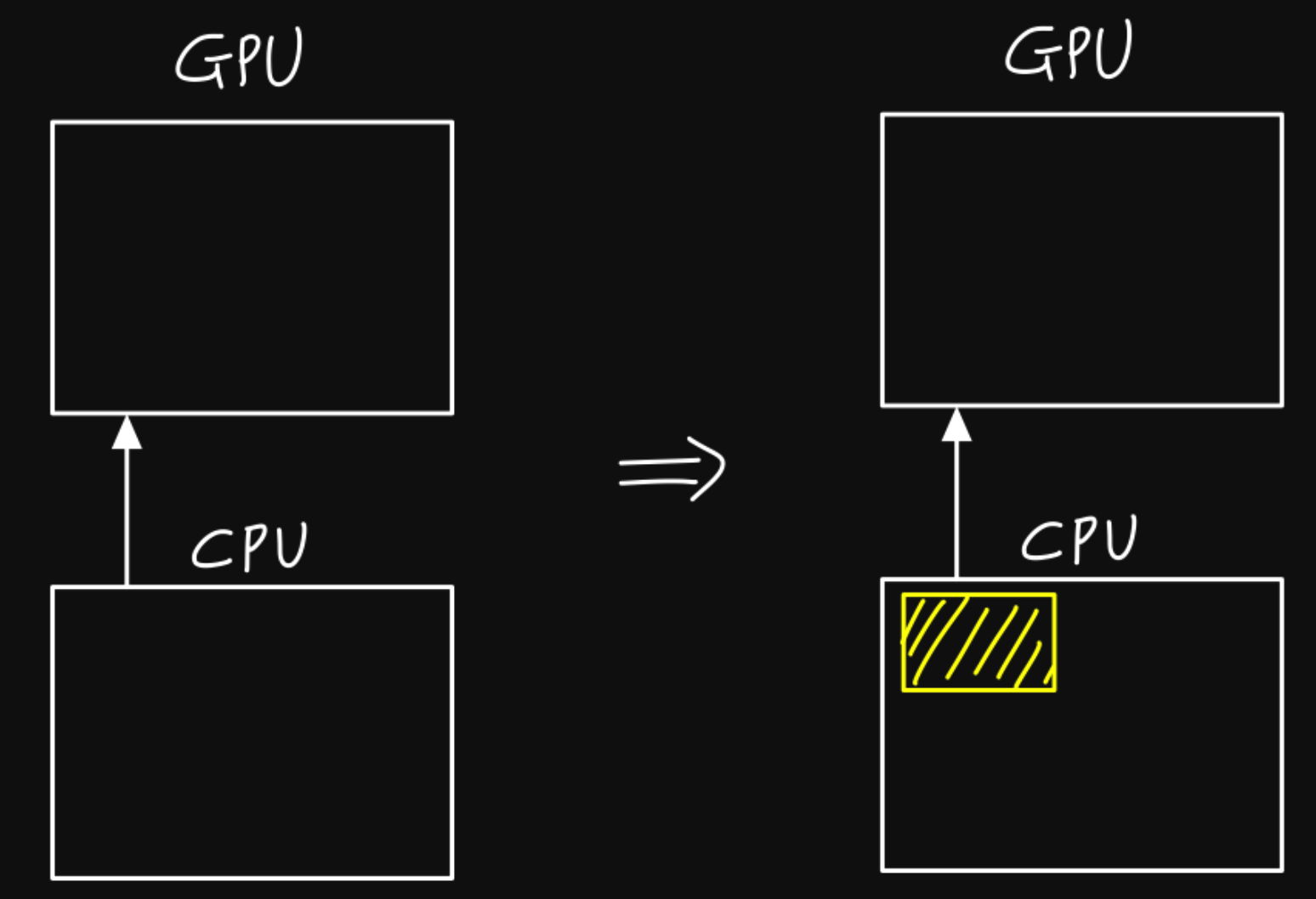
3. CPU & GPU transfer
CPU & GPU 사이의 데이터 transfer도 일임!
CPU \(\rightarrow\) GPU를 힘들게 했는데, 굳이 CPU로 다시 옮기는 과정은 비추천!
# BAD
.cpu()
.item()
.numpy()
# GOOD ( computational graph로부터 detach )
.detach()
(a) .detach
- 정의 : “Returns a new Tensor, detached from the current graph. The result will never require gradient.”
- computational graph에서 분리(detach)된 새로운 tensor를 반환
- before & after v0.4.0 : Variable과 Tensor가 합쳐짐
- before :
.data: Variable에서 값(데이터)를 뽑아냄 - after :
.detach
- before :
(b) .cpu()
- GPU 메모리에 있는 tensor를 CPU 메모리로 복사
(c) .numpy()
-
tensor를 numpy로 변환
-
.numpy()를 하기 위해서는 반드시 “CPU”에 먼저 올라가 있어야함!
best 순서 (dcn) :
.detach().cpu().numpy()
4. Construct tensors directly on GPU
# BAD
t = tensor.rand(2, 2).cuda()
# GOOD
t = tensor.rand(2, 2, device = torch.device('cuda'))
-
BAD 케이스 : cpu에서 생성 후, gpu로 load
-
GOOD 케이스 : directly gpu에서 생성
5. DP & DDP
-
DP : DataParallel = “multi-threading”
-
DDP : DistributedDataParallel = “multi-processing”
# DP
Trainer(distributed_backend='dp', gpus=8)
# DDP
Trainer(distributed_backend='ddp', gpus=8)
Process vs Thread
- process : 작업을 위해 실행되어야 할 명령어의 목록
- process를 실행하기 위해서는 memory가 필요
- thread : 명령어 목록의 명령어 하나하나를 실행하는 작업자
- 1개의 process에는 1개 이상의 thread가 있음
- 하나의 process내에 있는 thread들은 memory(자원)을 공유함
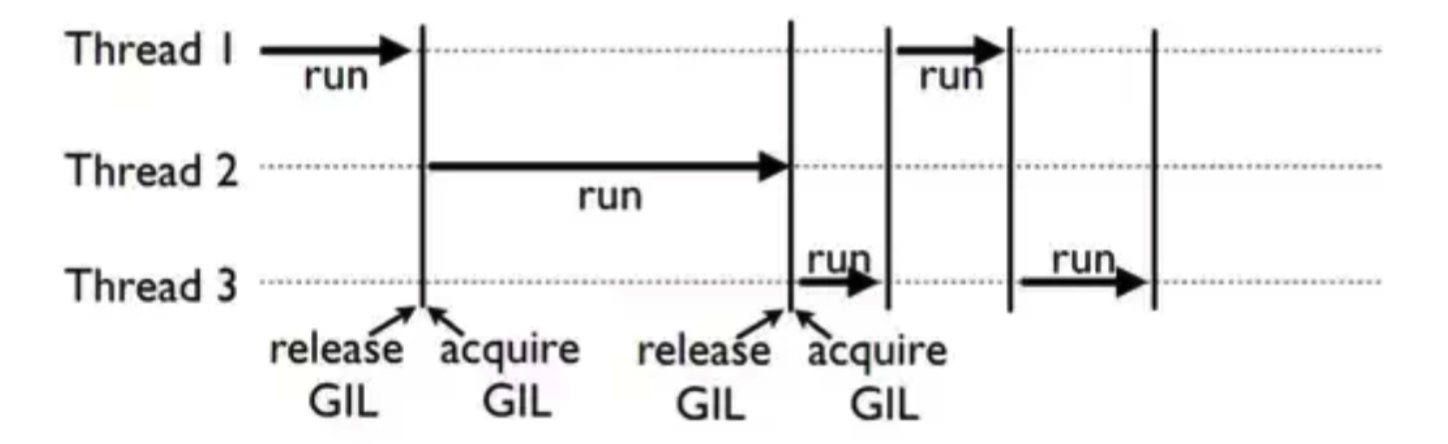
Python의 “GIL(Global Interpreter Lock)”
-
한 줄 요약 : 여러 개의 thread가 동시에 실행되지 못하도록 막는 기능
( 하나의 thread에 모든 자원을 허락, 그 후에는 Lock을 걸어 다른 thread는 실행 불가 )
-
따라서, pytorch에서는 DP보단 DDP 방식 사용!
6. Reproducibility
torch.manual_seed(random_seed)
torch.cuda.manual_seed(random_seed)
torch.cuda.manual_seed_all(random_seed) # if use multi-GPU
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(random_seed)
random.seed(random_seed)
7. ` torch.cuda.empty_cache()`
- 사용 되지 않는 gpu상의 캐시를 정리해 memory 확보
- ex)
del: 변수 & memory 사이의 관계를 끊음
lst=[]
for _ in range(5):
lst.append(torch.randn(10000,5).cuda())
# 변수 (=lst)와 메모리(=lst에 담긴 값들의 메모리) 사이의 관계 끊음
del lst
# 필요없어진 memory 비우기
torch.cuda.empty_Cache()
8. ` model.eval() vs torch.no_grad()`
model.eval() :
- 모델 내부의 모든 layer가 evaluation 모드
- ex) BN, DO …
torch.no_grad() :
- backprop (X) … 학습에서 제외
- Backprop에 필요한 메모리 등을 절약 \(\rightarrow\) 연산 faster
따라서, “특정 layer”에서 backprop 안하고 싶을 경우에는, 해당 layer에 torch.no_grad() 사용! 만약, 전체를 다 학습 하지 않고 evaluation만 진행할 경우, model.eval()을 사용!
example )
drop = nn.Dropout(p=0.3)
x = torch.ones(1, 10)
# Train mode
drop.train()
print(drop(x))
tensor([[1.4286, 1.4286, 0.0000, 1.4286, 0.0000, 1.4286, 1.4286, 0.0000, 1.4286, 1.4286]])
# Eval mode
drop.eval()
print(drop(x))
tensor([[1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]])
x = torch.tensor([1], requires_grad=True)
with torch.no_grad():
y = x * 2
y.requires_grad # False
9. nn.Dropout vs. F.dropout
nn.Dropout > F.dropout
- 근거 1) 모델의 train/eval 시 적용/해제 여부 자동으로 고려
F.dropout은 따로training = False를 설정해줘야!
- 근거 2) 모델이 모듈로써 인식 O
F.dropout은 model.summary에 표시 x
참고 :
-
https://velog.io/@jaylnne/Pytorch-%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-%EB%AA%A8%EB%8D%B8%EC%9D%98-%EC%84%B1%EB%8A%A5%EC%9D%84-%EA%B7%B9%EB%8C%80%ED%99%94%ED%95%98%EB%8A%94-7%EA%B0%80%EC%A7%80-%ED%8C%81
-
https://byeongjo-kim.tistory.com/32
-
https://ssungkang.tistory.com/entry/python-GIL-Global-interpreter-Lock%EC%9D%80-%EB%AC%B4%EC%97%87%EC%9D%BC%EA%B9%8C
-
https://westshine-data-analysis.tistory.com/m/132#:~:text=%E2%96%B7%20torch.cuda.empty_cache(),%EC%A4%84%20%EB%95%8C%20%EC%82%AC%EC%9A%A9%EA%B0%80%EB%8A%A5%ED%95%98%EB%8B%A4.
-
https://gaussian37.github.io/dl-pytorch-snippets/#gpu-%EC%82%AC%EC%9A%A9-%EC%8B%9C-datacudanon_blockingtrue-%EC%82%AC%EC%9A%A9-1