
데이터 분산 연산 (DP와 DDP)
Pytorch에서 병렬화를 사용하는 이유 2가지
- for 더 빠른 학습
- ex) 학습에 사용할 데이터를 병렬화
- 모델이 너무 커서, 이를 분할하여 GPU에 올리기 위해
1. torch.nn.DataParallel
(1) Forward Pass
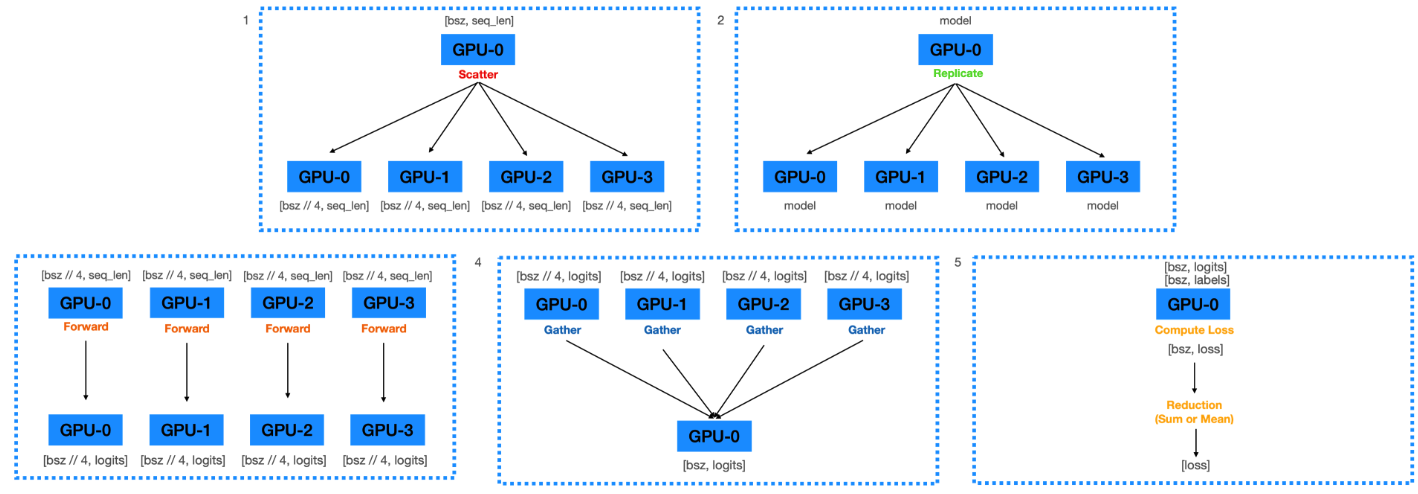
-
Scatter 연산
-
GPU0 에 올라온 데이터 배치를 4등분 & 각각 GPU0, GPU1, GPU2, GPU3 번에 전송
-
ex)
batch size= 16- step 1) GPU0 에 16을 올리고,
- step 2) GPU0, 1, 2, 3에 각각
batch size4씩 할당
-
- Replicate 연산
- GPU0 에 올라와 있는 model parameter를 GPU0, 1, 2, 3 에 전송
- Forward 연산 ( 각 디바이스 (GPU) 에 data와 model parameter이 있는 상황 )
- 각 디바이스 내에서 forward 연산을 수행하여
Logits을 계산
- 각 디바이스 내에서 forward 연산을 수행하여
- Gather 연산
- 각 디바이스에서 계산된
Logits값 들을 하나로 gather
- 각 디바이스에서 계산된
Logits으로 부터 Loss 를 계산
import torch.nn as nn
def data_parallel(module, inputs, labels, device_ids,
output_device):
# (1) [Scatter] data를 device들에 scatter
inputs = nn.parallel.scatter(inputs, device_ids)
# (2) [Replicate] model weight을 device_ids들에 복제
replicas = nn.parallel.replicate(module, device_ids)
# (3) [Forward] 각 device 에 복제된 model이 각 device의 data를 forward
logit = nn.parallel.parallel_apply(replicas, inputs)
# (4) [Gather] 모델의 logit을 output_device(하나의 device) 로 모음
logit = nn.parallel.gather(outputs, output_device)
return logits
(2) Backward Pass
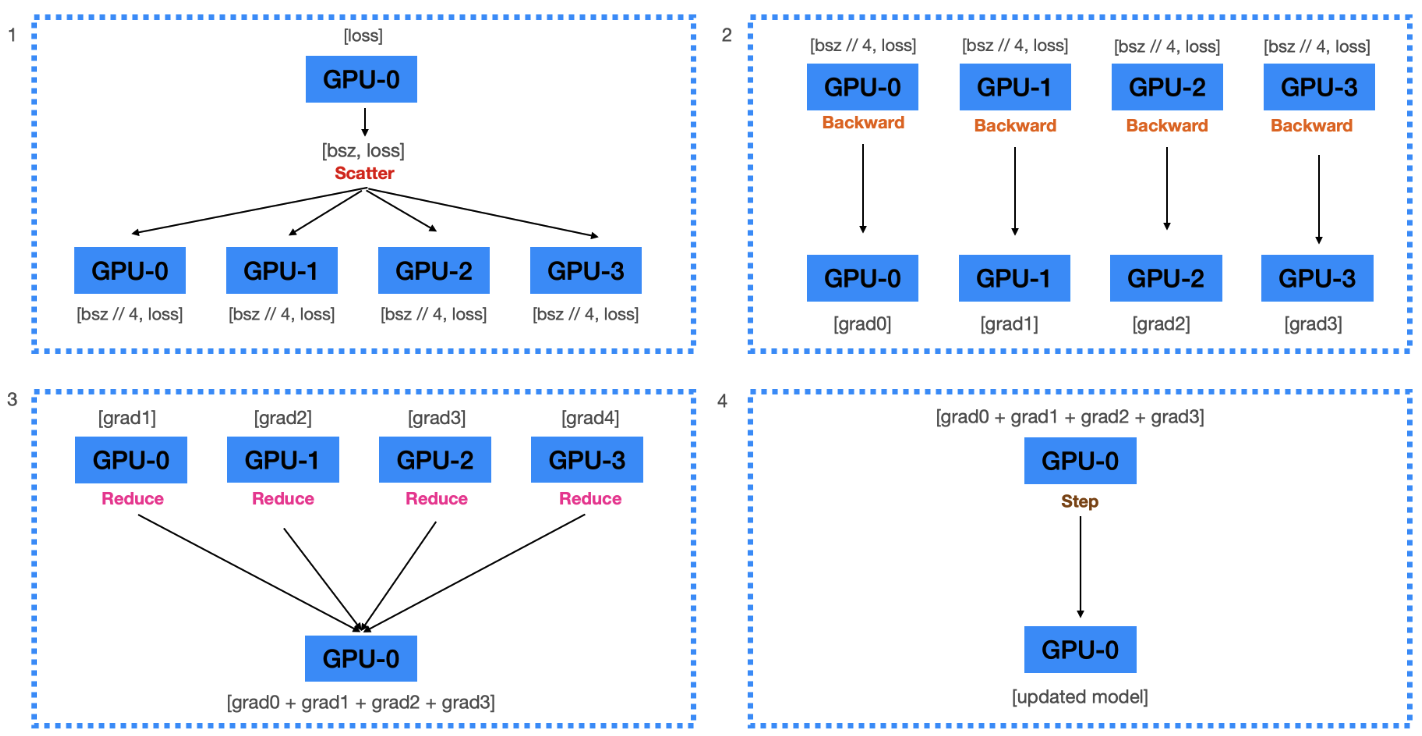
- Scatter 연산
- 하나의 디바에스에서 계산된 loss를 각 device에 scatter
-
Backward 연산
- 각 device는, 각자 전달받은 loss를 사용하여 각자 gradient 계산
-
Reduce 연산
-
계산된 모든 graidents를 GPU0으로 reduce
( = GPU0 에서 모두 더한 뒤, GPU의 수 만큼으로 나눠 줌 )
-
-
Update 연산
- Gradient를 이용해서 GPU0에 있는 모델을 업데이트
data_loader = DataLoader(datasets, batch_size=128,
num_workers=4)
model = nn.DataParallel(model, device_ids=[0, 1, 2, 3],
output_device=0)
문제점
메모리 사용량 : 0번 GPU > 다른 GPU
\(\because\) forwarding 연산 시 logits을 하나의 GPU ( = 0번 GPU ) 에 모은 뒤 loss를 계산하므로
\(\rightarrow\) 해결 : “각 GPU에서 loss 를 구한 뒤” 하나의 GPU에 “loss”를 모아주기
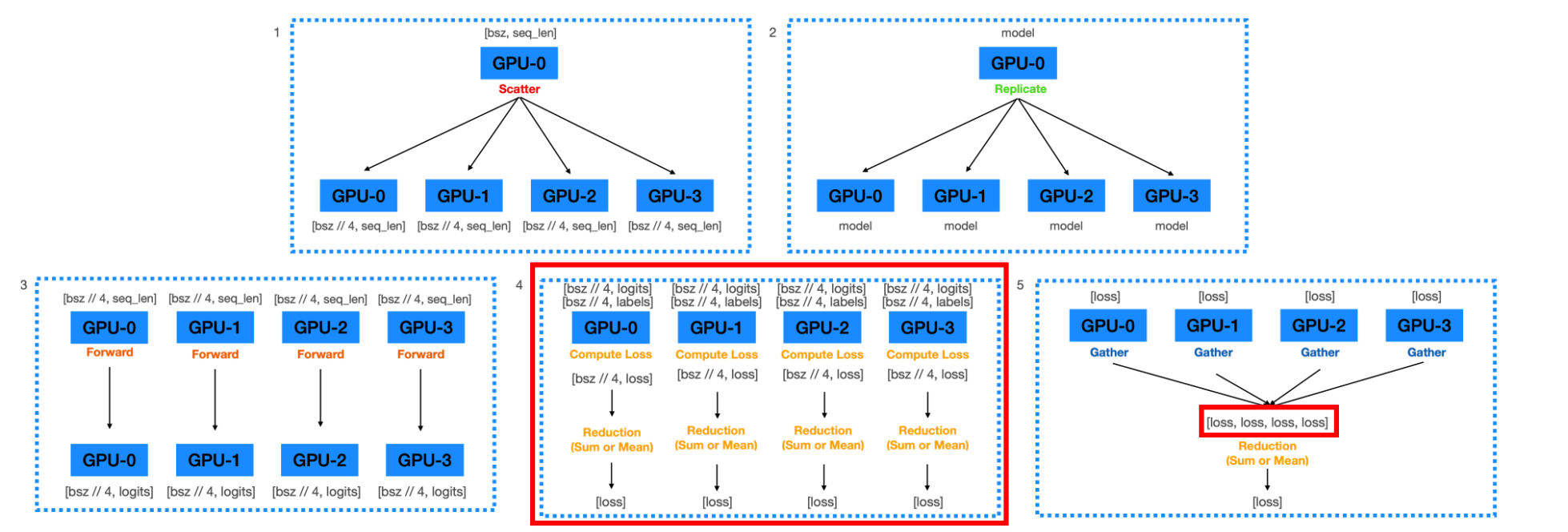
(3) Forward Pass 수정
따라서, 모델의 forward() 함수에 loss 계산하는 부분을 구현
class Model(nn.Module):
def __init__(self, input_dim, num_classes):
super().__init__()
self.linear = nn.Linear(input_dim, num_classes)
def forward(self, inputs):
outputs = self.linear(inputs)
return outputs
class ParallelLossModel(Model):
def __init__(self):
super().__init__()
def forward(self, inputs, labels):
logits = super().forward(inputs)
loss = nn.CrossEntropyLoss(reduction="mean")(logits, labels)
return loss
특이한 점 : Loss의 reduction이 2번 일어나게 됨
- (1) Multi-thread 에서
batch_size // 4개에서 loss가 나옴 ( = 그림 4 ) - (2) 각 device에서 출력된 4개의 Loss를 1개로 Reduction ( = 그림 5 )
\(\rightarrow\) 그렇다고 비효율적 ?? NO !!
- 이유 1) Loss computation 부분을 병렬화
- 이유 2) 0번 GPU에 가해지는 메모리 부담이 적어짐
참고
-
loss.backward(): Gradient를 계산 -
optimizer.step(): Parameter 업데이트( 계산 비용 :
backward()>step())
(4) torch.nn.DataParallel 의 문제점
-
Python에서는 비효율적
-
multi-thread 모듈
-
Python은 GIL (Global Interpreter Lock)
- 하나의 process에서 동시에 여러 thread 작동 불가
\(\rightarrow\) multi-thread가 아닌 multi-process 프로그램 으로 만들어서 여러 개의 프로세스를 동시에 실행
-
-
1개의 model에서 update된 모델을 모든 device로 계속 복제해야
- (현재 방식) Backward Pass시, 각 device에서 계산된 gradient를 하나로 gather 후 업데이트
- 따라서 매 step마다 다른 device로 복제 (broadcast) 해야 …. too expensive
- (new 방식) gradient를 gather하지 않고 각 GPU에서 자체적으로
step()- 모델 복제 불필요
- (현재 방식) Backward Pass시, 각 device에서 계산된 gradient를 하나로 gather 후 업데이트
All-reduce
-
reduce 를 수행한 뒤, “계산된 결과”를 모든 device에 복사
-
각 GPU에서 계산
Loss를 맞춰줄 수 있다면 자체적으로step()을 수행- 매번 모델을 특정 디바이스로부터 복제해 올 필요 X
-
BUT … 매우 비싼 연산 !
-
구현 방식
-
(1) Reduce + Broadcast
-
(2) All to All
-
(3) Ring All-reduce
( =
torch.nn.parallel.DistributedDataParallel(DDP) )
-
(1) Reduce + Broadcast
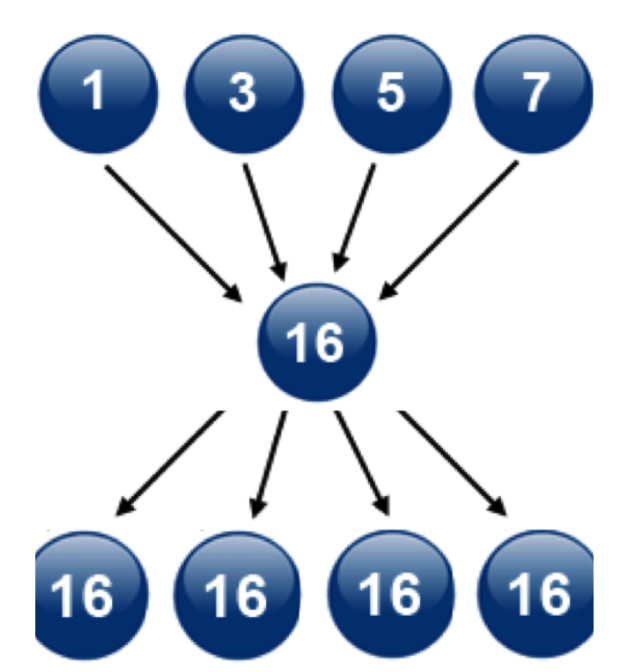
- 각 GPU의 연산들을 “1개의 마스터 프로세스 GPU에” 보내 마스터 프로세스가 연산을 완료
- “각 GPU”에 “연산될 결과값을 보내주는 방식”
- BUT …. 이 방식은 마스터 프로세스의 부하가 심해지며, 수가 증가할 때 마다 통신 비용이 매우 커짐
(2) All to All
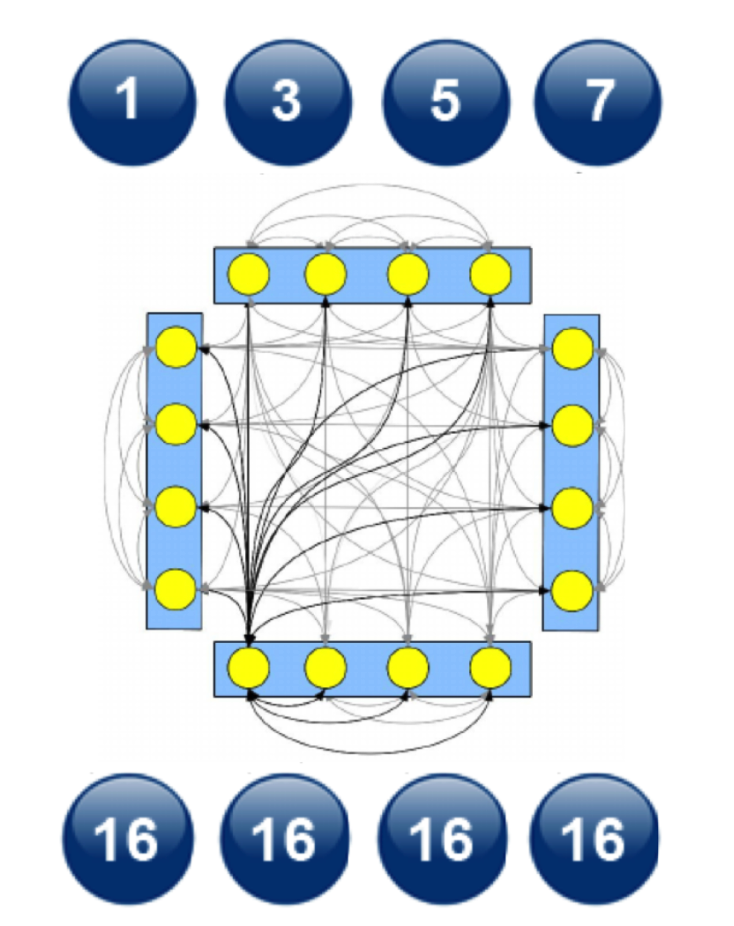
- 해당 방식은 모든 device가 개별 통신을 하여 각각의 값을 전송하는 방식
- \(n\)개의 장비가 있을 때, 약 \(n^2\) 의 통신이 발생
(3) Ring All-reduce
( = torch.nn.parallel.DistributedDataParallel(DDP) )
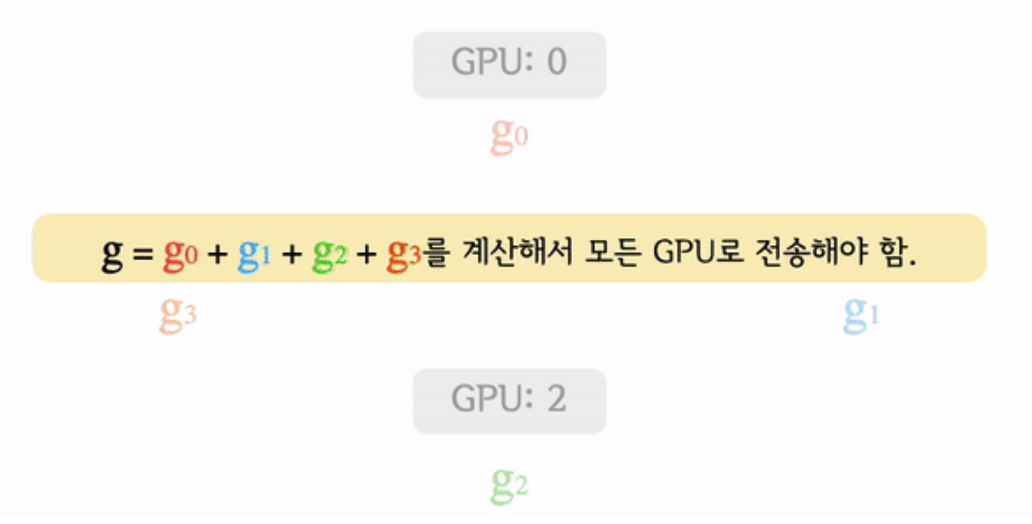
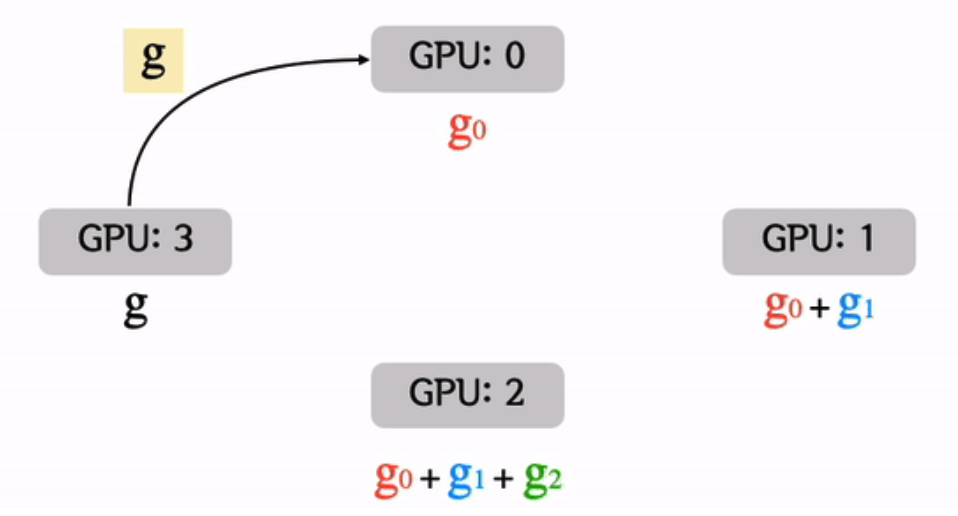
-
마스터 프로세스를 사용하지 않기 때문에 특정 device로 부하가 쏠리지 않음
-
All-to-All 처럼 비효율적인 연산 X
-
효율적인 방식으로 모든 device의 파라미터를 동시에 업데이트
- 모델을 매번 DP 처럼 replicate하지 않아도 됨!
(4) DDP
-
기존
DataParallel의 문제를 개선 -
single/multi-node & multi-GPU에서 동작하는multi-process모듈
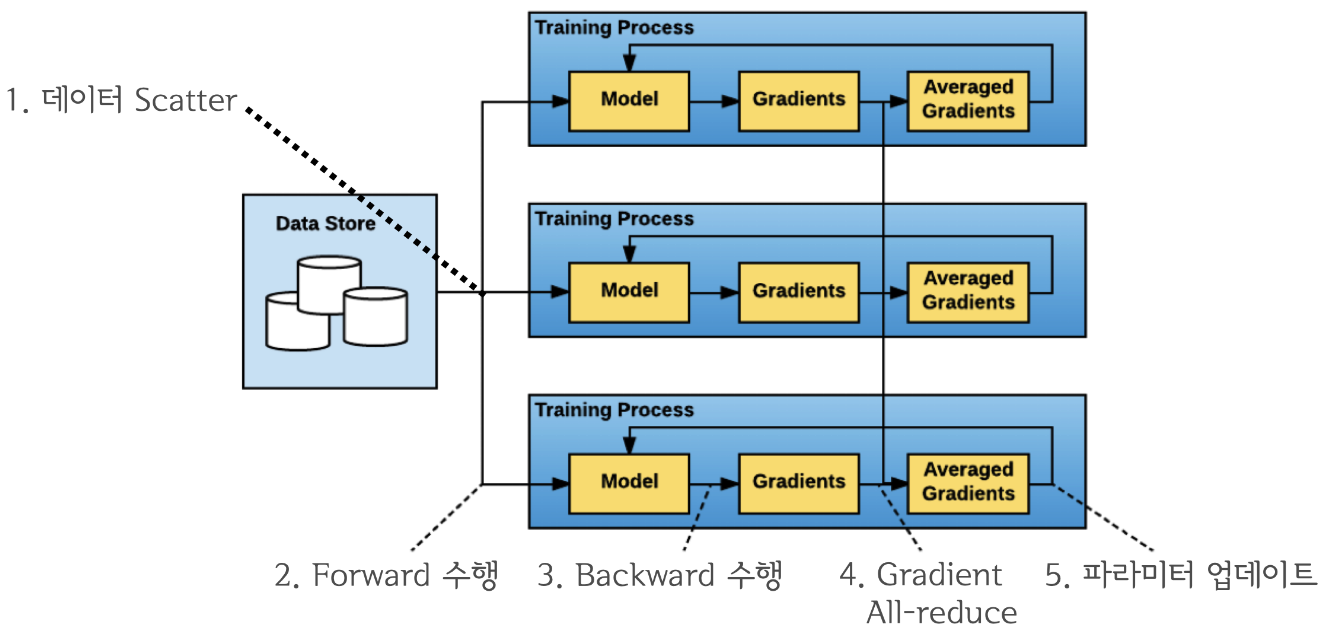
from torch.nn.parallel import DistributedDataParallel
from torch.optim import AdamW
from torch.utils.data import DataLoader, DistributedSampler
sampler = DistributedSampler(
datasets,
num_replicas=world_size,
rank=rank,
shuffle=True,
)
data_loader = DataLoader(
datasets,
batch_size=32,
num_workers=4,
sampler=sampler,
shuffle=False,
pin_memory=True,
)
model = DistributedDataParallel(model, device_ids=[device], output_device=device)
script 파일 실행 시…
- multi-process 애플리케이션이므로,
torch.distributed.launch를 사용해야!
python -m torch.distributed.launch --nproc_per_node=GPU개수 xxx.py