
( 참고 : Fastcampus 강의 )
[ 13. Monte Carlo Learning 실습 ]
1. 환경 설정하기
1-1. Import Packages
import sys; sys.path.append('..')
import numpy as np
import matplotlib.pyplot as plt
from src.part2.monte_carlo import ExactMCAgent, MCAgent
from src.common.gridworld import GridworldEnv
from src.common.grid_visualization import visualize_value_function, visualize_policy
np.random.seed(0)
1-2. Make Environment
nx, ny = 4, 4
env = GridworldEnv([ny, nx])
1-3. Environment 소개
print(env.nS) ## 16
print(env.nA) ## 4
print(env.P_tensor.shape) # 4x16x16
print(env.R_tensor.shape) # 16x4
2. Agent 초기화
mc_agent = ExactMCAgent(gamma=1.0,
num_states=nx * ny,
num_actions=4,
epsilon=1.0)
Agent의 input
gamma: 감가율num_states: 상태공간의 크기 (4x4)num_actions: 행동공간의 크기 (4)epsilon: \(\epsilon\)-greedy policy의 parameter
Action Index
action_mapper = {
0: 'UP',
1: 'RIGHT',
2: 'DOWN',
3: 'LEFT'
}
3. Agent & Environment의 상호작용
반복:
-
에피소드 시작
반복:
- 현재 상태 <- 환경으로 부터 현재 상태 관측
- 현재 행동 <- 에이전트의 정책함수(현재 상태)
- 다음 상태, 보상 <- 환경에 ‘현재 행동’을 가함
- if 다음 상태 == 종결 상태 :
- 반복문 탈출
-
에이전트의 가치함수 평가 및 정책함수 개선
(1) Action
def get_action(self, state):
prob = np.random.uniform(0.0, 1.0, 1)
# epsilon-greedy
# (1) Explore
if prob <= self.epsilon: # random
action = np.random.choice(range(self.num_actions))
# (2) Exploit
else:
action = self._policy_q[state, :].argmax()
return action
(2) One Episode
def run_episode(env, agent):
# (1) environment 초기화
env.reset()
states = []
actions = []
rewards = []
# (2) 과정
#### 1) state 관찰
#### 2) action 취함
#### 3) reward & 다음 state 받음
while True:
state = env.observe()
action = agent.get_action(state)
next_state, reward, done, info = env.step(action)
states.append(state)
actions.append(action)
rewards.append(reward)
if done:
break
################# EVERY visit method ##############################
## (3) 하나의 epsiode가 다 끝나면, 해당 결과를 사용하여 agent 업데이트 ##
###################################################################
episode = (states, actions, rewards)
agent.update(episode)
(3) Update agent
계산의 효율성을 위해, reward 계산 시 “역순”으로 계산한다.
def update(self, episode):
states, actions, rewards = episode
states = reversed(states)
actions = reversed(actions)
rewards = reversed(rewards)
iter = zip(states, actions, rewards)
cum_r = 0
for s, a, r in iter:
cum_r *= self.gamma
cum_r += r
self.n_v[s] += 1
self.n_q[s, a] += 1
self.s_v[s] += cum_r
self.s_q[s, a] += cum_r
(4) Value 계산
위에서 계산한 (1) Return (s_v, s_q) / (2) State 방문 횟수 (n_v) / State-action 방문횟수 (n_q)를 통해..
- 1) state value function \(V\) 와
- 2) action value function \(Q\) 계산하기
def compute_values(self):
self.v = self.s_v / (self.n_v + self._eps)
self.q = self.s_q / (self.n_q + self._eps)
4. 최종 코드 ( MC Prediction, MC Policy Evaluation )
-
epsiode 수행 횟수 : 2000
-
로그 출력 간격 : 500
num_episode = 2000
print_log = 500
run_epsidoes : episode를 run하는 함수
- Input : 환경 / agent / 에피소드 횟수 / 로그 출력 간격
def run_episodes(env, agent, num_episode, print_log):
mc_values = []
log_iters = []
agent.reset_statistics()
for i in range(num_episode+1):
run_episode(env, agent)
if i % print_log == 0:
agent.compute_values()
mc_values.append(agent.v.copy())
log_iters.append(i)
info = dict()
info['values'] = mc_values
info['iters'] = log_iters
return info
MC Policy Evaluation 수행하기
info = run_episodes(env, mc_agent, num_episode, print_log)
log_iters = info['iters']
mc_values = info['values']
5. Variance of MC Predictions
Monte-carlo Policy evaluation는, 매번 실행할 때마다 계산된 value function이 다르다 ( \(\because\) stochastic 하므로 )
그렇다면, 여러번 계산 된 value function의 variance는?
(1) Set hyperparameters
총 3000번의 epsiode를 run하는 과정을, 총 10번 반복한다 (출력 간격 : 10)
num_repeat = 10
values_over_runs = []
num_episode = 3000
print_log = 30
(2) Repeat 10 times
10번 반복한 결과를 values_over_runs에 저장
- size : 10x101x16
- 10 : 총 10번 반복
- 101 : 3000번의 epsiode를 30간격으로 저장 (0,30,60,90,…,3000) …총 101회
- 16 : state의 개수 (4x4)
for i in range(num_repeat):
print("start to run {} th experiment ... ".format(i))
info = run_episodes(env, mc_agent, num_episode, print_log)
values_over_runs.append(info['values'])
values_over_runs = np.stack(values_over_runs)
print(values_over_runs.shape) # 10,101,16
(3) Calculate answer ( using DP )
정답 value function ( DP를 통해 계산한 참값이다 )
from src.part2.tensorized_dp import TensorDP
dp_agent = TensorDP()
dp_agent.set_env(env)
v_pi = dp_agent.policy_evaluation()
v_pi_expanded = np.expand_dims(v_pi, axis=(0,1))
(4) Calculate Error ( & mean.std of error )
- 추후에 TD와 비교하기 위해, error값들을 저장한다.
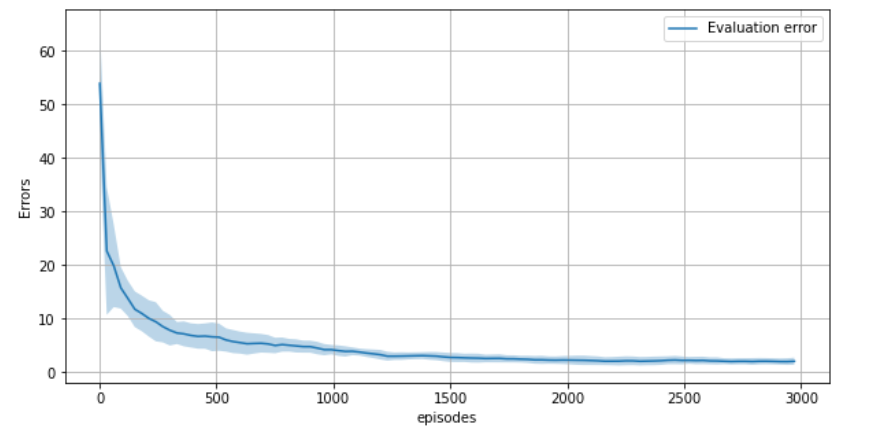
errors = np.linalg.norm(values_over_runs - v_pi_expanded, axis=-1)
error_mean = np.mean(errors, axis=0)
error_std = np.std(errors, axis=0)
np.save('mc_errors.npy', errors)
(5) Visualization
fig, ax = plt.subplots(1,1, figsize=(10,5))
ax.grid()
ax.fill_between(x=info['iters'],
y1=error_mean + error_std,
y2=error_mean - error_std,
alpha=0.3)
ax.plot(info['iters'], error_mean, label='Evaluation error')
ax.legend()
ax.set_xlabel('episodes')
ax.set_ylabel('Errors')
6. Incremental MC Prediction
(BEFORE)
(한번에) \(V(s) \leftarrow \frac{S(s)}{N(s)}\).
def compute_values(self):
self.v = self.s_v / (self.n_v + self._eps)
self.q = self.s_q / (self.n_q + self._eps)
def update(self, episode):
states, actions, rewards = episode
states = reversed(states)
actions = reversed(actions)
rewards = reversed(rewards)
iter = zip(states, actions, rewards)
cum_r = 0
for s, a, r in iter:
cum_r *= self.gamma
cum_r += r
self.n_v[s] += 1
self.n_q[s, a] += 1
self.s_v[s] += cum_r
self.s_q[s, a] += cum_r
(AFTER)
(online/incremental)
- \(V(s) \leftarrow V(s)+\frac{1}{N(s)}\left(G_{t}-V(s)\right)\).
- \(V(s) \leftarrow V(s)+\alpha\left(G_{t}-V(s)\right)\).
MCAgent : 기존의 ExacatMCAgent + learning rate \(\alpha\)
mc_agent = MCAgent(gamma=1.0,
lr=1e-3,
num_states=nx * ny,
num_actions=4,
epsilon=1.0)
Update 함수
- 더 이상 counter를 저장하지 않는다. n_v, n_q, s_v, s_q 필요 없음
- learning rate 사용
def update(self, episode):
states, actions, rewards = episode
states = reversed(states)
actions = reversed(actions)
rewards = reversed(rewards)
iter = zip(states, actions, rewards)
cum_r = 0
for s, a, r in iter:
cum_r *= self.gamma
cum_r += r
self.v[s] += self.lr * (cum_r - self.v[s])
self.q[s, a] += self.lr * (cum_r - self.q[s, a])
5000번의 epsiode를 run한다
for _ in range(5000):
run_episode(env, mc_agent)