( 참고 : Fastcampus 강의 )
[ 24.SARSA vs Q-learning 실습 ]
1. SARSA vs Q-learning
본질적인 차이 : OFF policy냐, ON policy냐!
-
on-policy :평가하는 정책 $$\pi(a s)\(와 행동 정책\)\mu(a s)$$이 동일 -
off-policy : 평가하는 정책 $$\pi(a s)\(와 행동 정책\)\mu(a s)$$이 다름
SARSA :
- 행동 정책 : \(\epsilon\)-greedy 정책 사용
- 평가하는 정책 : \(\epsilon\)-greedy 정책 사용
Q-learning :
- 행동 정책 : \(\epsilon\)-greedy 정책 사용
- 평가하는 정책 : 현재 추산된 \(Q(s,a)\)로 탐욕적 정책을 사용
1. Import Packages
import numpy as np
import matplotlib.pyplot as plt
from src.part2.temporal_difference import SARSA,QLearner
from src.common.gridworld import GridworldEnv
from src.common.grid_visualization import visualize_value_function, visualize_policy
np.random.seed(0)
2. Environment 소개
cliff_env = CliffWalkingEnv()

2. Agent 생성
sarsa_agent = SARSA(gamma=.9,
lr=1e-1,
num_states=cliff_env.nS,
num_actions=cliff_env.nA,
epsilon=0.1)
q_agent = QLearner(gamma=.9,
lr=1e-1,
num_states=cliff_env.nS,
num_actions=cliff_env.nA,
epsilon=0.1)
3. SARSA vs Q- Learning
(1) SARSA
\(Q(s, a) \leftarrow Q(s, a)+\alpha\left(r+\gamma \max _{a^{\prime}} Q\left(s^{\prime}, a^{\prime}\right)-Q(s, a)\right)\).
def update_sample(self, s, a, r, s_, a_, done):
td_target = r + self.gamma * self.q[s_, a_] * (1 - done)
self.q[s, a] += self.lr * (td_target - self.q[s, a])
def run_sarsa(agent, env):
env.reset()
reward_sum = 0
while True:
s = env.s
a = agent.get_action(s)
s_, r, done, info = env.step(a)
a_ = sarsa_agent.get_action(s_)
reward_sum += r
agent.update_sample(state=s,
action=a,
reward=r,
next_state=s_,
next_action=a_,
done=done)
if done:
break
return reward_sum
(2) Q-learning
\(Q(s, a) \leftarrow Q(s, a)+\alpha\left(r+\gamma \max _{a^{\prime}} Q\left(s^{\prime}, a^{\prime}\right)-Q(s, a)\right)\).
def update_sample(self, s, a, r, s_, done):
td_target = r + self.gamma * self.q[s_, :].max() * (1 - done)
self.q[s, a] += self.lr * (td_target - self.q[s, a])
def run_qlearning(agent, env):
env.reset()
reward_sum = 0
while True:
s = env.s
a = agent.get_action(s)
s_, r, done, info = env.step(a)
reward_sum += r
agent.update_sample(state=s,
action=a,
reward=r,
next_state=s_,
done=done)
if done:
break
return reward_sum
4. Experiment
num_eps = 1500
sarsa_rewards = []
qlearning_rewards = []
for i in range(num_eps):
sarsa_reward_sum = run_sarsa(sarsa_agent, cliff_env)
qlearning_reward_sum = run_qlearning(q_agent, cliff_env)
sarsa_rewards.append(sarsa_reward_sum)
qlearning_rewards.append(qlearning_reward_sum)
fig, ax = plt.subplots(1,1, figsize=(10,5))
ax.grid()
ax.plot(sarsa_rewards, label='SARSA episode reward')
ax.plot(qlearning_rewards, label='Q-Learing episode reward', alpha=0.5)
ax.legend()
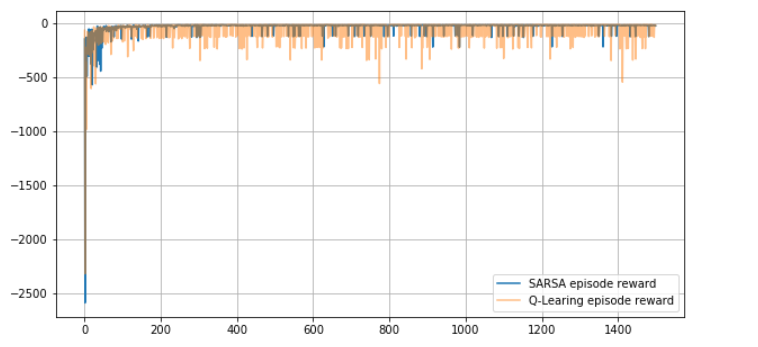
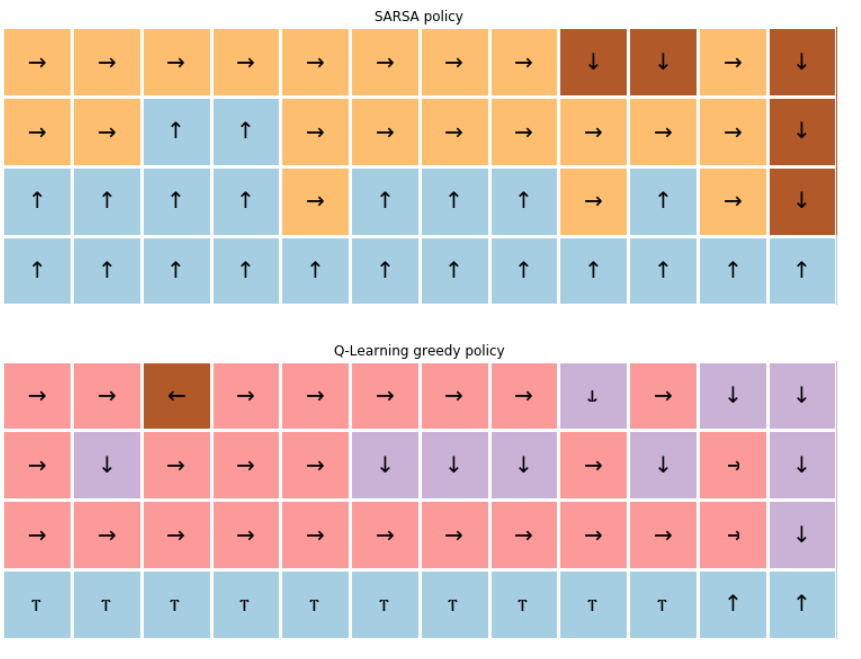
결론 :
[Reward] off-policy인 Q-learning < on-policy .. WHY?
Q-learning이, BEHAVOUR policy가 아니라, 현재 추산된 \(Q(s,a)\)로 탐욕적 정책을 사용한다면, 아래와 같은 효율적인 경로를 따라서 가게 될 것이다.
- SARSA : 안전하게 뺑 돌아감
- Q-learning : cliff에 붙어서 효율적으로 움직임
fig, ax = plt.subplots(2,1, figsize=(20, 10))
visualize_policy(ax[0], sarsa_agent.q, cliff_env.shape[0], cliff_env.shape[1])
_ = ax[0].set_title("SARSA policy")
visualize_policy(ax[1], q_agent.q, cliff_env.shape[0], cliff_env.shape[1])
_ = ax[1].set_title("Q-Learning greedy policy")