( 참고 : Fastcampus 강의 )
[ 43. 모델 기반 강화학습 소개 ]
1. 모델 기반 강화학습
“모델 기반 강화학습” :
- 현재 정책에 대한 reward / transition model 또한 배우게 된다!
- $f_\theta(s_t,a_t) \rightarrow s_{t+1}, r_t$… 환경 = $f_{\theta}$
- 환경이란 “모델”이 추가된 것이라고 생각하면 됨!
Notation 변화
| 강화학습 | 최적 제어 | |
|---|---|---|
| 상태 | $s_t$ | $x_t$ |
| 행동 | $a_t$ | $u_t$ |
| 관측 | $o_t$ | $y_t$ |
| 보상 | $r_t$ | $-c_t$ |
2. Planning
“모델이 있다면, 미래에 무슨 일이 있을지에 대해 어느정도 생각을 해보면서 행동을 할 수 있다”
-
Planning : 모델에 대한 정보가 있을 때
-
Learning : 모델에 대한 정보가 없을 때
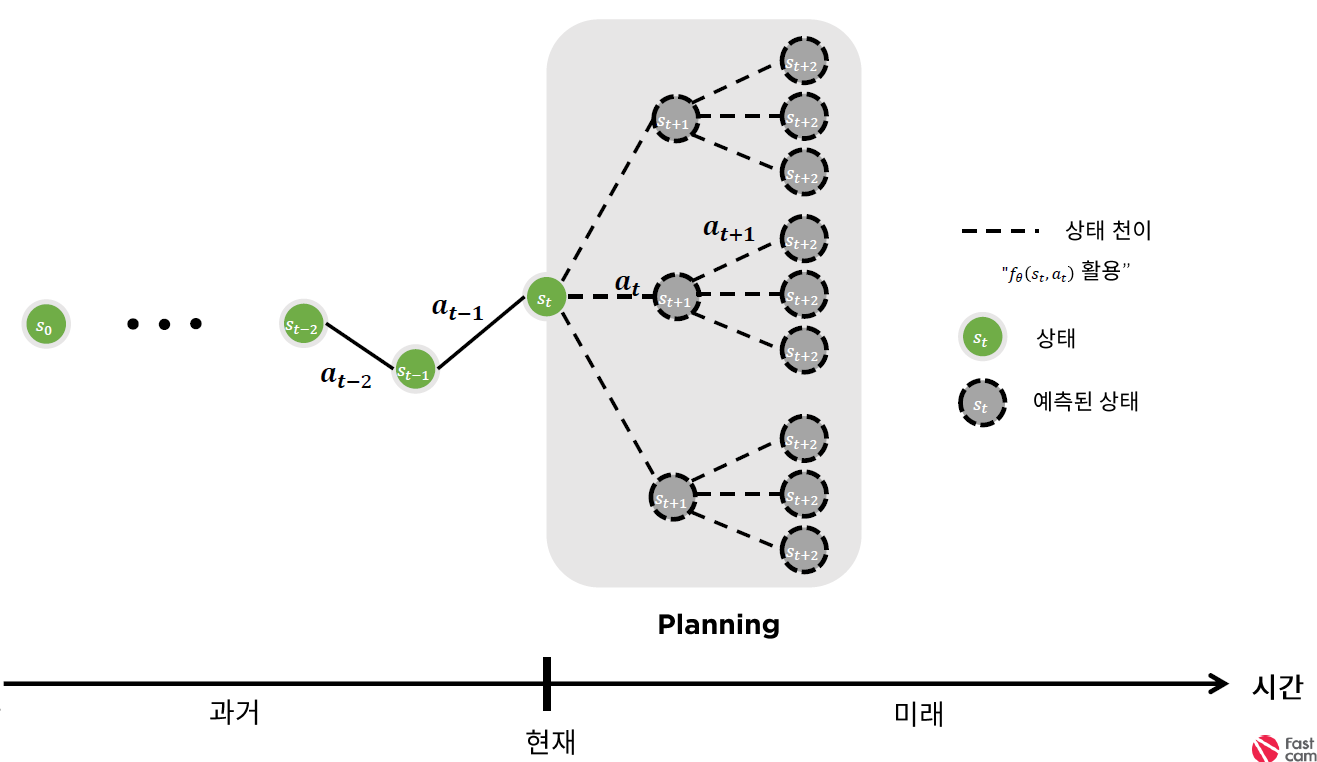
Planning의 종류
(1) DISCRETE state/action space
- Beam search
- Monte-Carlo Tree search
(2) CONTINUOUS state/action space
- Optimal Control
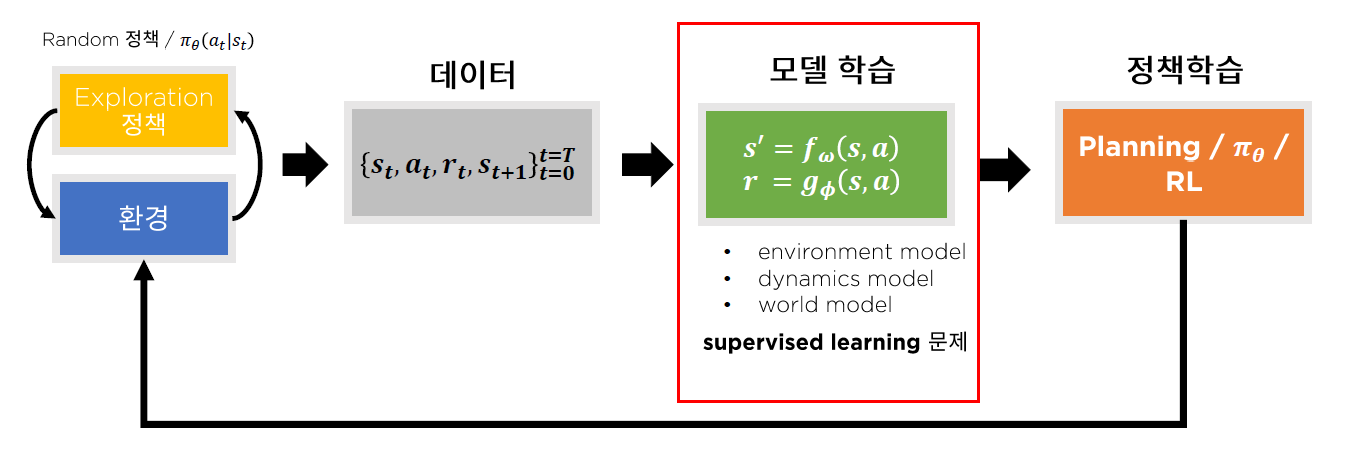
3. Framework
모델 기반 RL = 기존의 RL + “모델 학습”
모델 학습
- discrete) classification
- continuous) regression
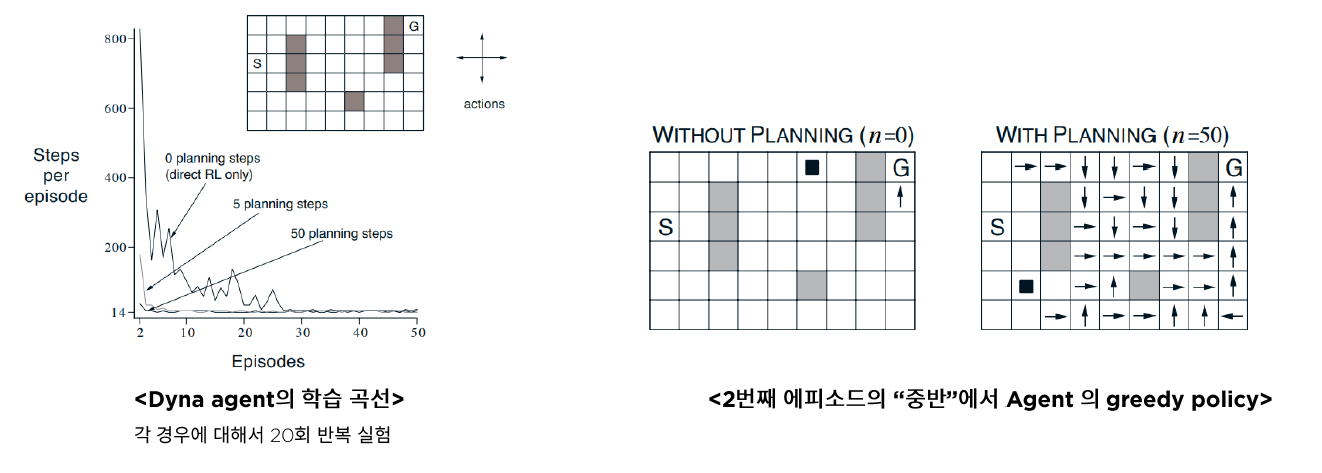
4. Dyna : 모델을 활용한 Bellman update
( $Q(s,a)$와 Model$(s,a)$는 처음에 0으로 초기화 되어있다. )
크게 세 개의 과정으로 이루어짐
- 1) Q-Learning
- 2) “모델 학습”
- supervised learning 방식으로 학습
- 3) Planning
- 모델 학습 이후, 모델을 사용하여 planning
- $n$회 반복을 정해줌
- 과거에 방문했던 $s$와, 해당 state에서 했던 행동 $a$에 대해서 update를 진행한다.
- $Q(s, a) \leftarrow Q(s, a)+\alpha\left(r+\gamma \max _{a^{\prime}} Q\left(s^{\prime}, a^{\prime}\right)-Q(s, a)\right)$.
Pseudocode

Experiment
$n$의 설정에 따라 최적의 경로를 찾기까지 걸리는 episode의 차이를 확인할 수 있다.
( planning $\uparrow$ $\rightarrow$ faster to optimal policy )