
( 출처 : 연세대학교 데이터베이스 시스템 수업 (CSI6541) 강의자료 )
Chapter 10. Indexing and Hashing (2)
Contents
- Static Hashing
- Dynamic Hashing
- Comparison of Ordered Indexing and Hashing
- Multiple-Key Access
- Bitmap Index
(1) Static Hashing
( https://huzz.tistory.com/60 )
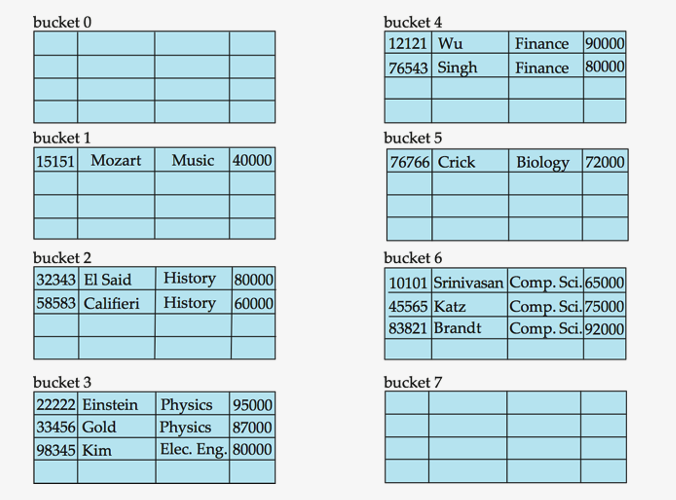
Bucket?
- unit of storage containing one or more records
- ( typically a disk block )
In hash file organization…
- obtain the bucket directly from its search-key value using a “hash function”
Records with different search-key values may be mapped to the SAME bucket
\(\rightarrow\) \(\therefore\) entire bucket has to be searched sequentially
Hash Organization
( Key : dpet_name )
Hash Indices
Hash can be used for both..
- (1) file organization
- (2) index-structure creation
Hash Index organizes the search keys
Deficiencies of Static Hashing
Static Hashing
hash function maps search-key values to a fixed set of bucket addresses
-
Databases grow with time
\(\rightarrow\) If initial number of buckets is too small, performance will degrade due to too many overflows
-
What if LARGE space at the first place ?
- significant amount of space will be wasted initially
- If database shrinks, space will be wasted
-
Option : re-organization of the index file with a NEW hash function
\(\rightarrow\) verey expensive
\(\rightarrow\) solved by using techniques that allow the number of buckets to be modified “dynamically”
Blog Summary
Introduction
- Bucket : 여러 개의 records를 저장
- Hash function ( = h ) : search key K를 받아 bucket address B를 계산
Static hashing
- h(K) 계산해서 bucket을 찾아간 후,
- 해당 bucket 안에 있는 모든 records에 대해 일치하는 records가 있는지 검사
Worst Possible Hash Function
- case : h(K)값이 모두 한 값으로 몰리게 되어 모든 records가 한 bucket에 저장
- 즉, 저장되어있는 모든 records를 전수 조사하는 꼴
\(\rightarrow\) 좋은 hash function을 선택해야!
좋은 hash function의 2가지 조건
-
1. Uniform: 가능한 모든 search key에 대해서 각 bucket으로 할당되는 key들의 개수가 균일해야 한다.
-
2. Random: 평균적으로, 각 bucket은 거의 비슷한 수의 key들이 할당되어야!
-
ex) string 길이, 알파벳 순 등외적 인 조건들을 이용한 함수 (X),
Random하게 계산되는 함수 (O)
-
Handling of Bucket Overflows
-
Bucket : 처음에 지정해준 size 만큼만 저장
\(\rightarrow\) 계속 insert하다보면 언젠가 bucket이 꽉 차게 될 것 ( = Bucket Overflow )
-
해결책 :
- (1) closed hashing
- (2) open hashing
1. Closed hashing:
- b1이 꽉 찼다면, 새로운 bucket b2을 만들고 b1 뒤에 b2를 연결
- bucket들을 linked list 같이 다루는 방식을 overflow chaining이라 함
2. Open hashing:
- ( 위처럼 뒤에 연결하는 것이 아니라 ) 일련의 규칙에 의해 다른 bucket에 record를 저장
- ex) 선형(또는 제곱)으로 몇 칸을 더 뒤로 간다든가(linear/quadratic probing) hash function을 한 번 더 적용한다든가 등
Open hashing ( vs. Closed hashing )
- 장점 ) 새로운 공간을 덜 사용
- 단점) deletion이 빈번히 일어나는 DB에 부적절
\(\rightarrow\) 일반적으로 closed hashing을 선호
(2) Dynamic Hashing
( https://huzz.tistory.com/61 )
Details :
- Suitable for DB that grows and shrinks in size
- Allows the hash function to be modified dynamically
- Ex) Extendable Hashing
Extendable Hashing
- Hash function : generates values over a large range
- use only a prefix of the hash function to index into a bucket address table
( 아래 참조하기 )
Blog Summary
Drawback of Static Hashing
-
Current size에 맞게 hash function을 구성
\(\rightarrow\) data 증가에 따른 성능 저하
-
Anticipated size에 맞게 hash function을 구성
\(\rightarrow\) Anticipated size에 도달하기 전까지는 wasted space가 발생
-
Size에 맞게 hash function을 변경하고 reorganization을 수행
\(\rightarrow\) TOO EXPENSIVE & reorganization 동안 data access 불가
Solution : Extendable hashing ( dynamic hashing의 기법 )
- extendable : 확장 가능한
- hash function h를 잘 선택해야!
- (1) unformity & randomness를 잘 만족
- (2) hash value가 32bit의 binary integer로 나타나게끔
- hash value와 정확히 1:1로 대응하는 bucket (X)
- 적당히 32bit의 prefix에 해당하는 n비트만을 사용 (O)
- n비트 이용 시 : 총 \(2^n\)개의 bucket
- 이 prefix bits들과 bucket들의 주소를 연결해주는 bucket address table을 함께 만들게됨
- lookup(search), insertion, deletion은 모두 간단하게 구현
- 요약 :
- (1) Search key를 hash function의 input으로 넣음
- (2) output 값의 앞 n비트만을 마치 hash value인 것처럼 사용
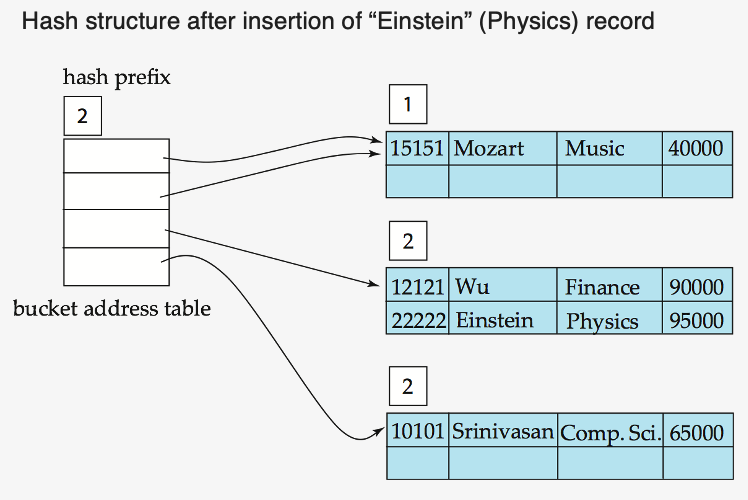
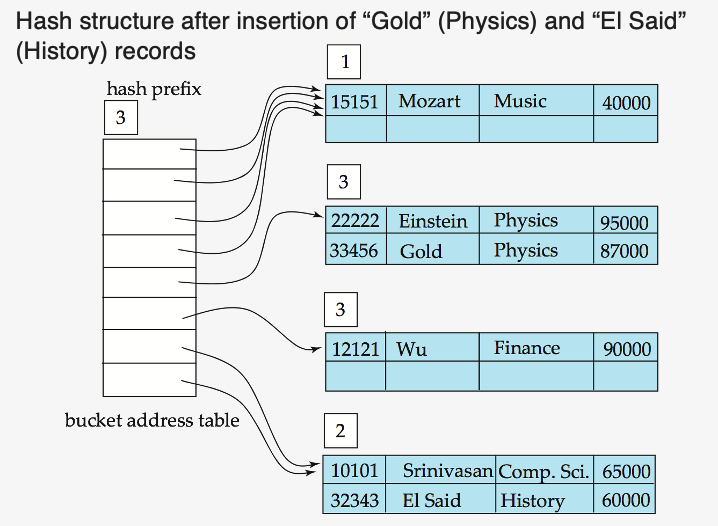
- 문제 : bucket overflow 시?
- 간단하게 bucket을 추가로 만들고, 사용하는 prefix 비트 수를 n 대신 n+1로
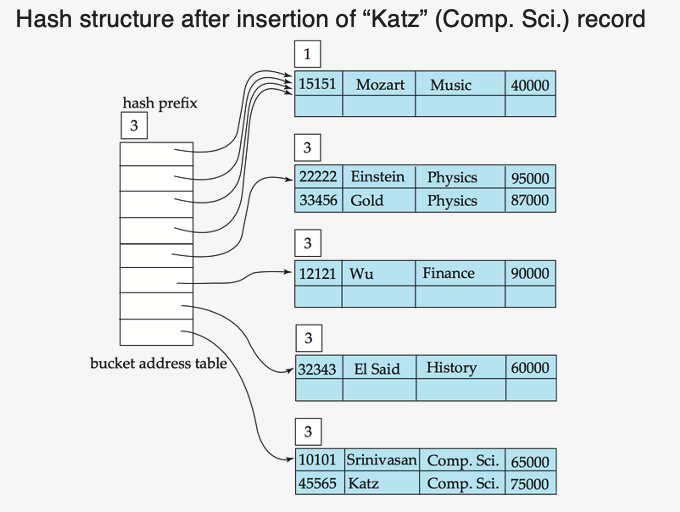
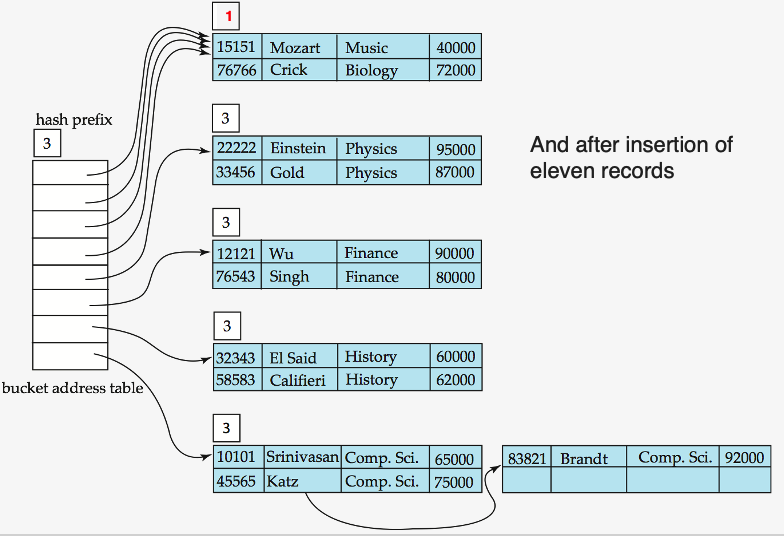
Example
- https://www.youtube.com/watch?v=Bxfo2LwOIj4 참고하기


Extendable Hashing ( vs. Other Schemes )
Pros
-
Hash performance does not degrade with growth of file
-
Minimal space overhead
Cons
- Extra level of indirection to find desired record
- Bucket address table may itself become very big
- Changing size of bucket address table is an expensive operation
(3) Comparison of Ordered Indexing and Hashing
(1) conditioning “=” \(\rightarrow\) Hashing
(2) conditioning “>”, “<” \(\rightarrow\) Ordered Indexing
(4) Multiple-Key Access
ex)
SELECT ID
FROM instructor
WHERE dept_name = “Finance” and salary = 80000
Possible strategies ( using indices on single attributes )
-
Use index on dept_name to find all instructors in the Finance department & test salary = 80000
-
Use index on salary to find all instructors with salary of $$80000 & test dept_name = “Finance”
-
Use dept_name index to find pointers to all records pertaining to the Finance department.
Similarly use index on salary.
Take intersection of both sets of pointers obtained
index on combined search-key (dept_name, salary)
-
fetch only records that satisfy both conditions
- Using separate indices is less efficient
- may fetch many records that satisfy only one of the conditions
- Efficient ex ) where dept_name = “Finance” and salary < 80000
- Inefficient ex ) where dept_name < “Finance” and salary = 80000
(5) Bitmap Index
( Bitmap = an array of bits )
-
special type of index designed for efficient querying on multiple keys
-
records in a relation are assumed to be numbered sequentially
- Applicable on attributes that take on a relatively small number of distinct values
- ex) gender, country, state, …
- Given a number n it must be easy to retrieve record n
simplest form
a bitmap index on an attribute has a bitmap for each value of the attribute
- Bitmap has as many bits as records ( =
nunique) - 1 if the record has the value v for the attribute, and is 0 o.w

Details
Queries are answered using bitmap operations
- AND, OR, NOT
Each operation takes two bitmaps of the same size
- ex) Males with income level L1
- 10010 AND 10100 = 10000