[ Semi-supervised Learning ]
참고 : https://sanghyu.tistory.com/177
1. Limitation of Supervised Learning
labeled data를 확보하기 어려울 수
\(\rightarrow\) labeled data가 적은 경우, 데이터의 true distn 전체를 커버하지 못할 수도 있음
2. What is Semi-supervised Learning?
적은 labeled data + 많은 unlabeled data
- with 적은 labeled data : label을 맞추는 모델
- with 많은 unlabeled data : 데이터 자체의 본질적인 특성이 모델링
\(\rightarrow\) 소량의 labeled data로도 좋은 예측 성능 가능할 것!
Loss Function
supervised + unsupervised task가 1 stage로 이루어짐
\[L = L_s + L_u\]- \(L_s\) : supervised loss
- (continuous value) regression loss / (discrete value) classificaiton loss
- \(L_u\) : unsupervised loss
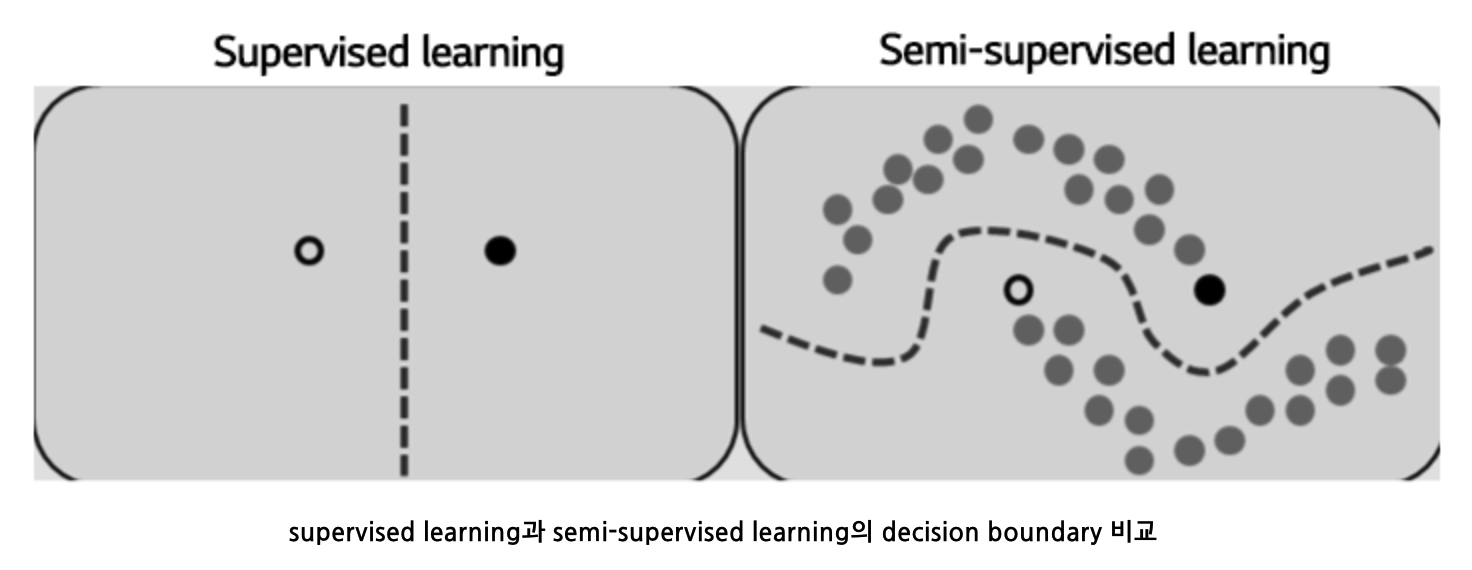
3. Assumption of Semi-supervised Learning
(1) Smoothness Assumption
“x1 & x2가 high-density region에서 close \(\rightarrow\) y1 & y2도 close”
- classification엔 도움
- regression에선 그닥…
(2) Cluster assumption
“data들이 같은 cluster에 있다면, 같은 class일 것”
- 즉, decision boundary는 low density region을 통과해야!
(3) Manifold Assumption
“high-dim data를 low-dim manifold로 보낼 수 있다.”
-
unlabeled data를 사용해서 low-dim representation을 얻고,
labeled data를 사용해 더 간단한 task를 풀 수 있을 것!
4. Algorithms
대부분 computer vision + classification task

List of Algorithms
- (1) Entropy Minimization
- (2) Proxy-label method
- (3) Generative Models
- (4) Consistency Regularization
- (5) Holistic Methods
- (6) Graph-based Methods
(1) Entropy Minimization
Paper List
Key Assumption : ‘decision boundary는 데이터의 low density region에서 형성될 것’
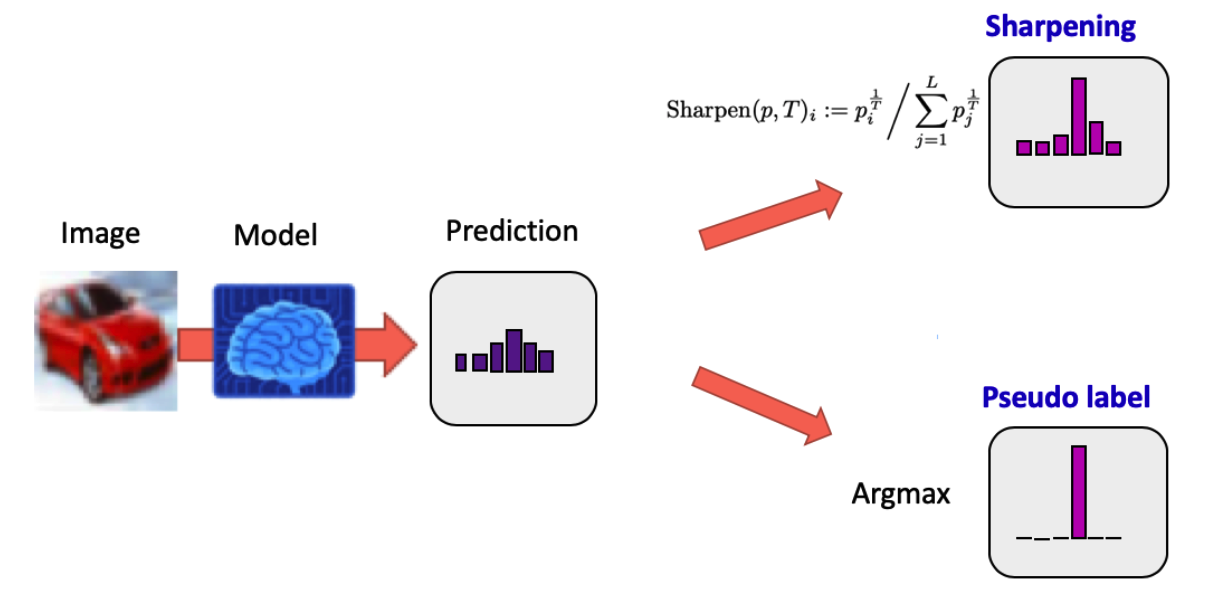
Key Idea : unlabeled data output의 entropy를 minimize
- Ex) 개 0.6, 고양이 0.4 « 개 0.9, 고양이 0.1
Example
-
MixMatch, UDA, ReMixMatch : temperature sharpening
-
FixMatch : pseudo-label
(2) Proxy-label method
Paper List
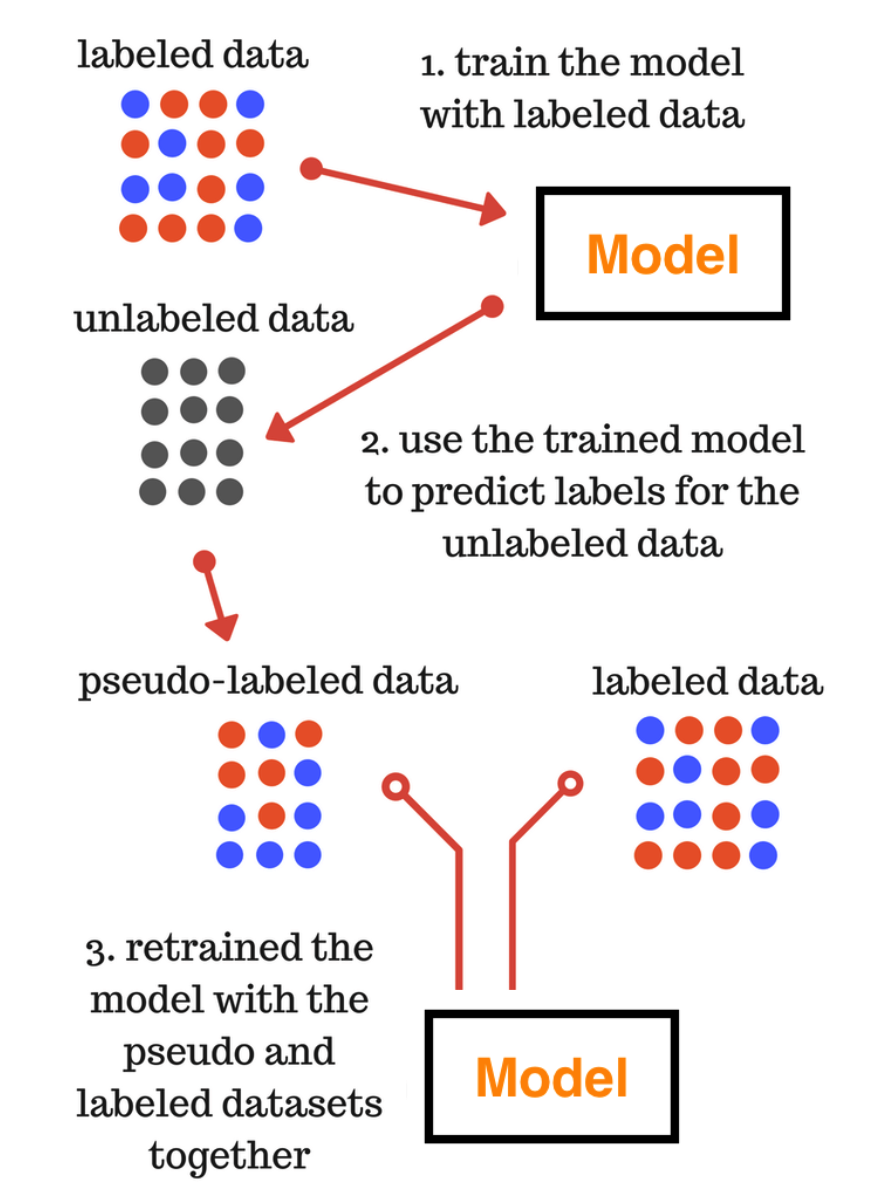
Key Idea : unlabeled data에 label을 달아주기
- ( ex. pseudo-label의 confidence가 높은 data에만 label 부여 )
Pros & Cons
-
[Pros] classification, regression에 모두 사용할 수 있다는 장점
-
[Cons] labeled set의 분포를 벗어나는 샘플들에는 제대로된 label을 달아주기 어렵기 때문에 성능향상에 한계가 있다는 단점
Example
- self-training : pseudo-label, meta pseudo-label, noisy student
- multi-view training : Co-training
(3) Generative Models
Paper List
Reconstruction Task
-
w.o label
-
semi-supervised learning에서 unlabeled data에 주는 unsupervised task로 적합
Example : VAE를 활용한 semi-supervised learning
-
M1 model 과 M2 model
-
M1 model : 2번의 과정 ( pre-trained & fine tuning )
-
step 1) labeled, unlabeled data를 모두 활용하여 VAE를 pre-train
-
step 2) pre-trained된 VAE 뒷단에 classifier/regressor를 붙인 뒤,
labeled data를 이용한 labeled task에 specific하게 파라미터를 조정
-
-
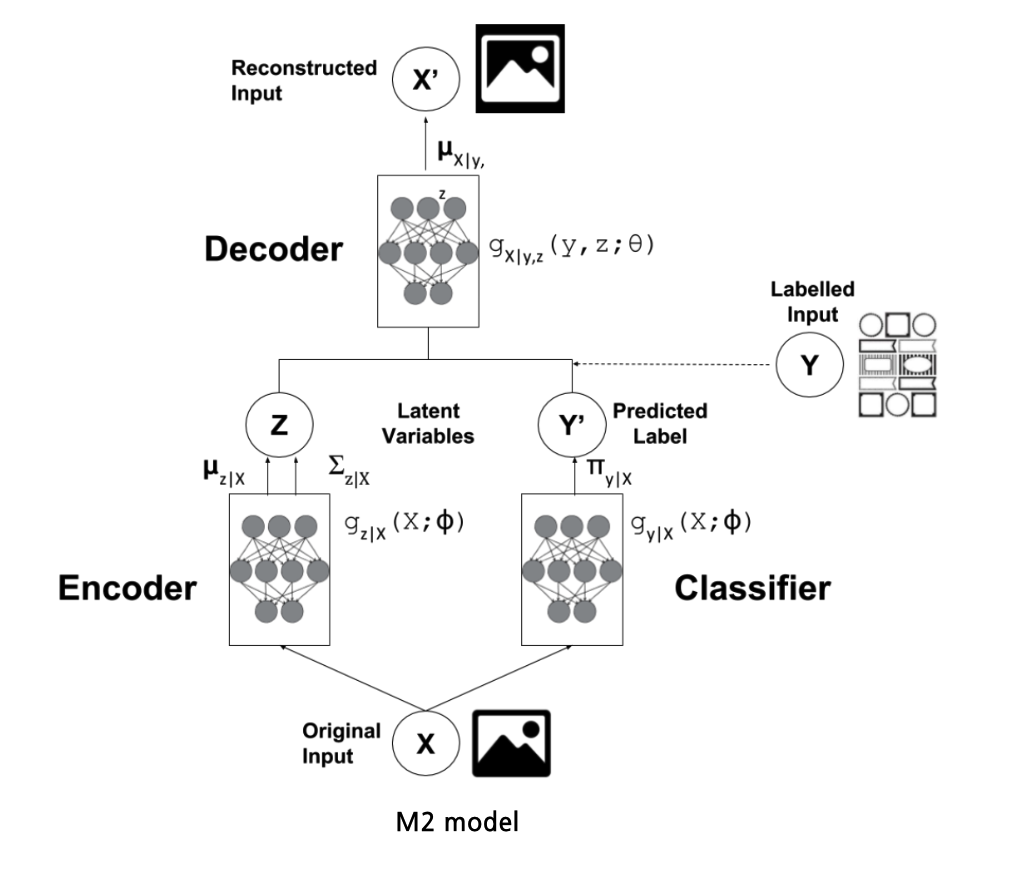
M2 model : 1번의 과정
- encoder의 output인 \(z\)에 예측된 label \(y\)를 concatenate & decoder에 보내기
-
또 다른 방안 : M1 + M2 (stack)
- input of M2 = output of M1 ( = z )
-
(4) Consistency Regularization
Paper List
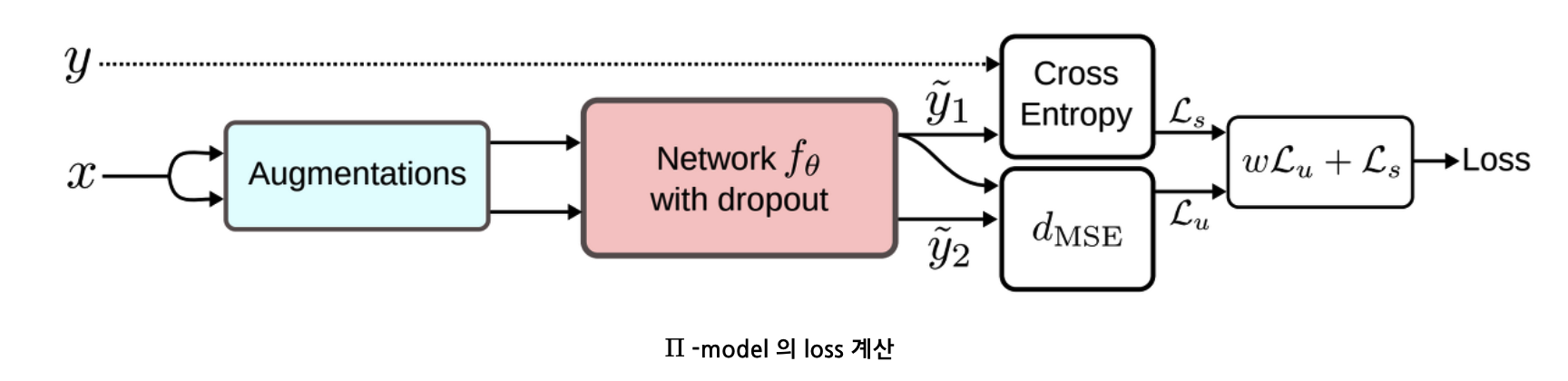
Key Assumption : unlabeled data에 small perturbation을 주어도 output은 consistent
- small perturbation = data augmentation
- \(\therefore\) computer vision에서는 work well…. 다른 도메인에서는 글쎄…
Key Idea : predicted output of “original” & “perturbed version”이 같도록 unsupervised loss 부여
- via consistency regularization
Example
- Π-model, Temporal Ensemble, Mean Teacher, Virtual Adversarial Training (VAT), unsupervised data augmentation (UDA)
(5) Holistic Methods
Paper List
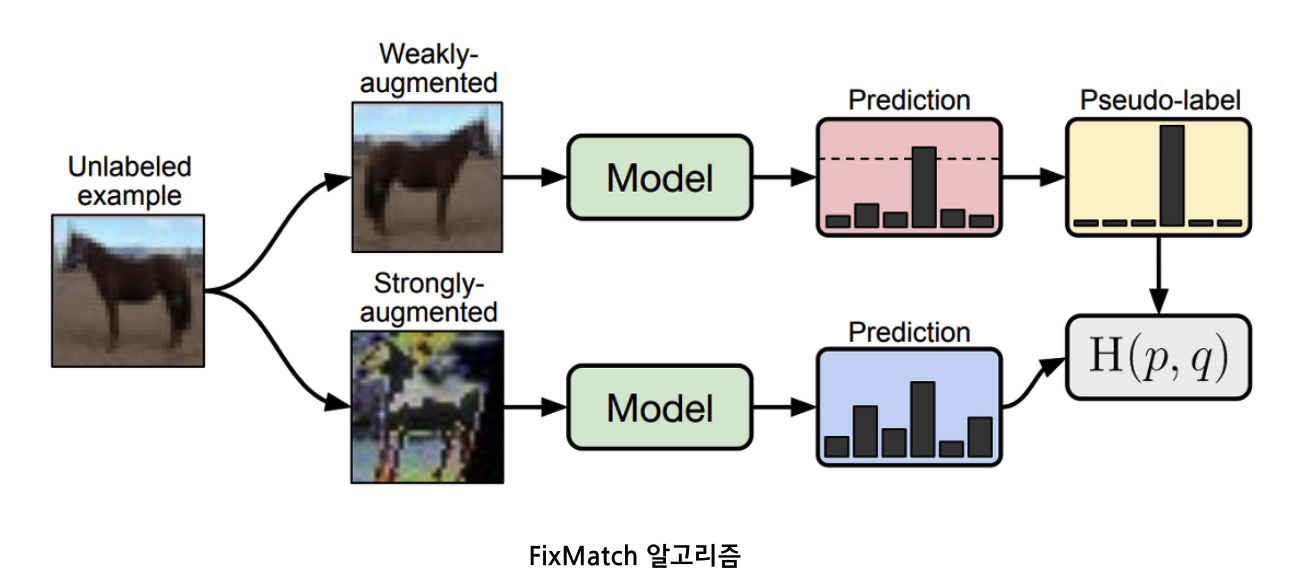
Key Idea : semi-supervised learning 기법들 + Mixup data augmentation
Example
- MixMatch, ReMixMatch, FixMatch
(6) Graph-based Methods
Paper List
기존 vs Graph based method의 main focus
- 기존 ) unlabeled data로 labeled data의 예측성능을 올리고 싶다
- Graph ) unlabeled data의 label을 알고싶다
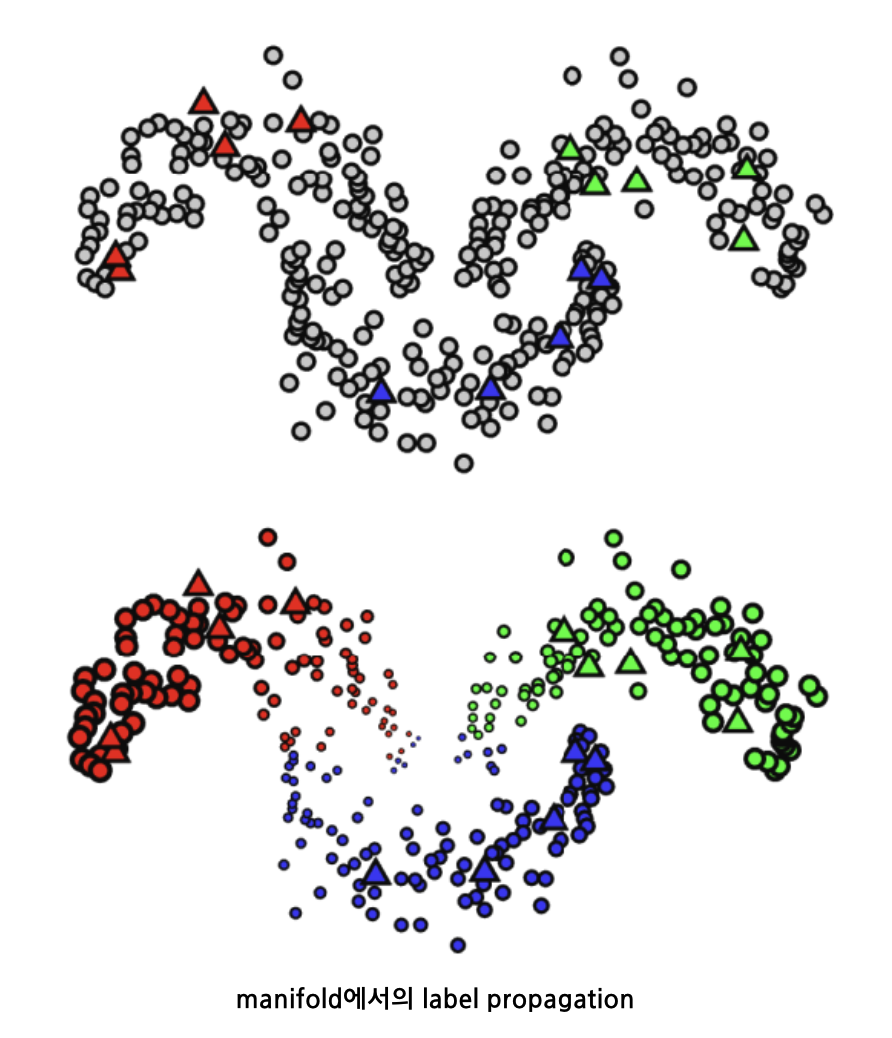
Example : Label Propagation
- node embedding으로 데이터를 represent
- node사이의 similarity를 바탕으로, 높은 similarity를 가진 node의 정보/label을 propagate