
Semi-SL & Self-SL for Tabular Data
참고: https://www.youtube.com/watch?v=nt2d6JTIoH0
Contents
- Introduction
- VIME
- SubTab
- SCARF
- Contrastive Mixup
0. Introduction
(1) Semi-SL & Self-SL
Semi-supervised Learning
- pseudo labeling
- hybrid methods
Self-supervised Learning
- pretext task
- contrastive learning
(2) Tabular data
Tabular Data : 2차원의 데이터 ( 행& 열 )
Tabular Data의 트렌드 : 정형 데이터의 상대적 비중이 줄어들고 있음
(3) Tabular Data의 어려움
Perform poor on tabular
- missing value가 더욱 치명적
- outlier가 극단적
- class 불균형이 심한 문제들
Feature 간의 관계
- 특정한 규칙이 없음
- (이미지 : 인접 = 유사)
- (Tabular : 인접 != 유사)
전처리가 어려움
- 수치형 & 범주형 변수의 공존
- 범주형 변수: 원핫인코딩 \(\rightarrow\) 차원의 저주
- 기존의 data augmentation 기법의 적용 어려움
기존의 Self/Semi-SL 방법론들은 주로 비정형 데이터를 위하 고안됨.
(4) Different Approaches for Tabular Data
방법 1) 정형 데이터를 이미지화
- SuperTML (2019): https://arxiv.org/abs/1903.06246
- IGTD (2021): https://www.nature.com/articles/s41598-021-90923-y
방법 2) Attention mechanisum
- TabNet(2019): https://arxiv.org/pdf/1908.07442.pdf
방법 3) AE 기반 contextual embedding
- VIME (2020): https://proceedings.neurips.cc/paper_files/paper/2020/file/7d97667a3e056acab9aaf653807b4a03-Paper.pdf
- SubTab (2021): https://proceedings.neurips.cc/paper_files/paper/2021/file/9c8661befae6dbcd08304dbf4dcaf0db-Paper.pdf
방법 4) Contrastive Learning
- SCARF (2021): https://arxiv.org/pdf/2106.15147.pdf
- Contrastive Mixup (2021): https://arxiv.org/pdf/2108.12296.pdf
1. VIME ( NeurIPS, 2020)
Extending the Success of Self- and Semi-supervised Learning to Tabular Domain
Network
- Encoder
- Decoder
- Mask Estimator
Loss
- Reconstruction Loss
- Cross-Entropy (CE) Loss
a) Self-SL
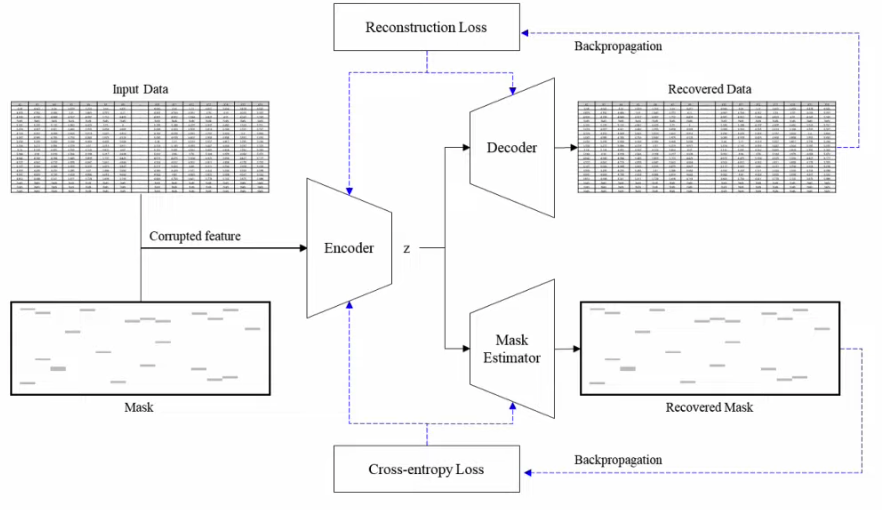
Two tasks:
- Task 1) Recover the masked part
- Task 2) Guess which part is masked
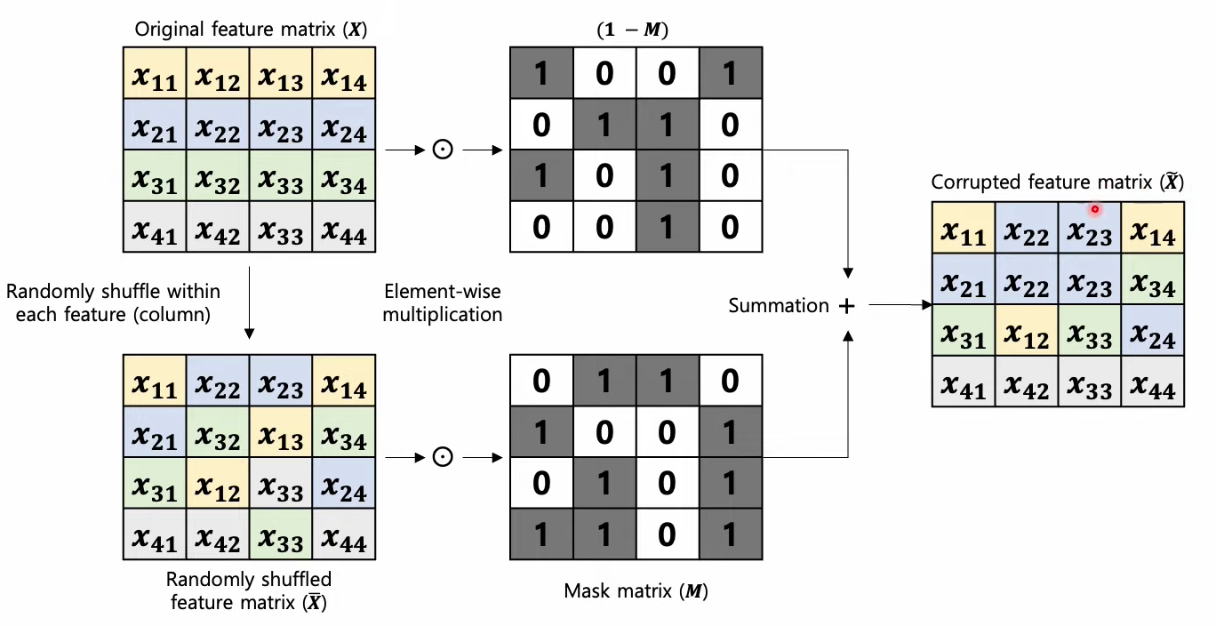
Noise Strategy : column-wise swap noise
= randomly shuffle WITHIN each column (feature)
( 이유 : 다른 column 간에는 매우 상이한 특징을 가지므로, column “내”에서 shuffle )
( 코드 상 구현 방법 )
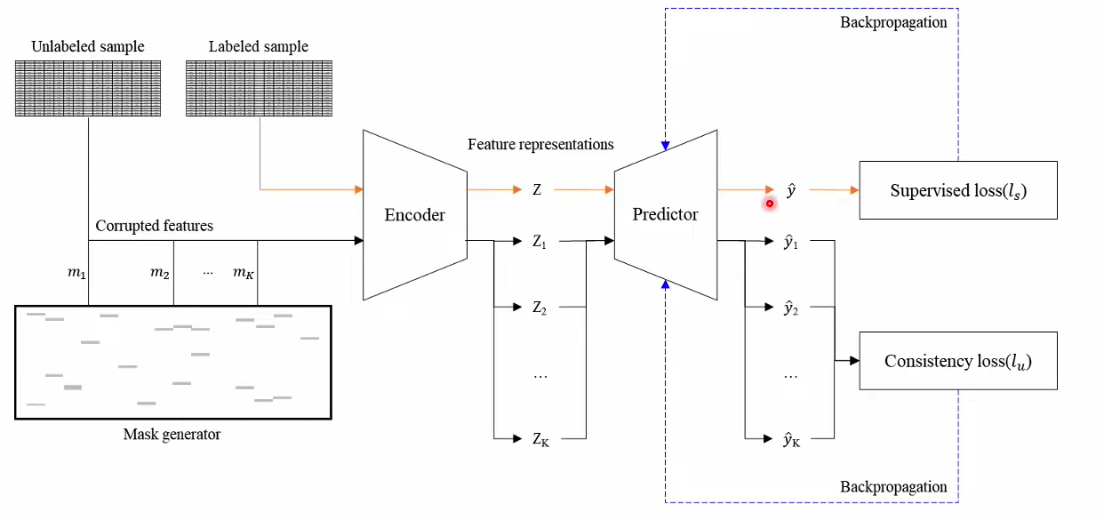
b) Semi-sl
Use the (fixed) PRETRAINED encoder with Self-SL
Losses
- Labeled Data: Supervised Loss
- Unlabeled Data: Consistency Loss
How to treat unlabeled data?
- augment \(K\) times … with random mask ( from mask generator )
- \(K\) outputs should be consistent
2. SubTab ( NeurIPS, 2021 )
SubTab: Subsetting Features of Tabular Data for Self-supervised Representation Learning
Network
- Encoder
- Decoder
- Projection
Loss
- Reconstruction Loss
- Contrastive Loss
- Distance Loss
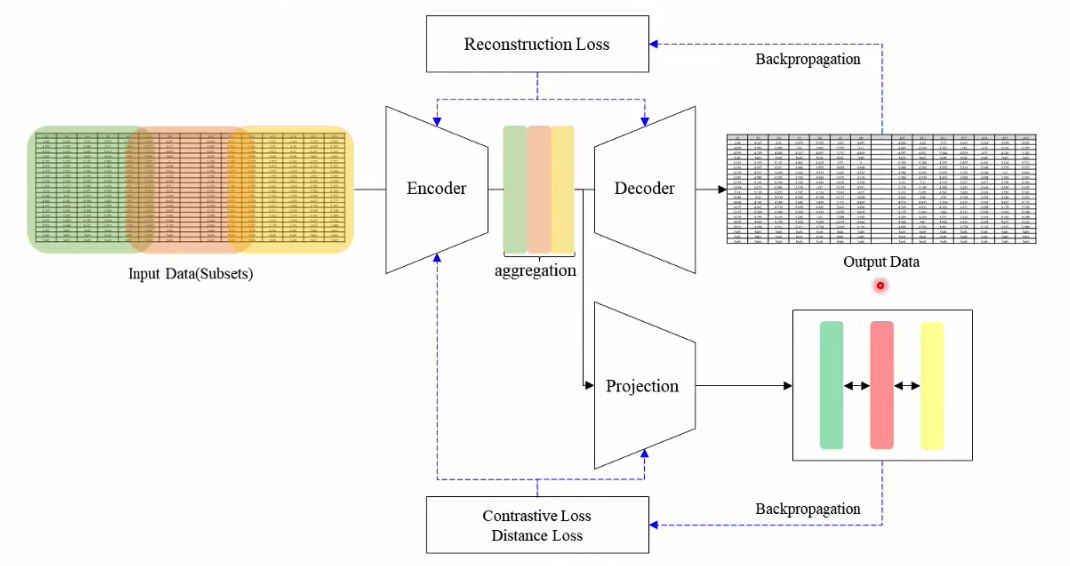
Input을 여러 개의 subset으로 나눔
- subset 1: col1, col2, col3
- subset 2: col3, col4, col5
- subset 3: col5, col6, col7
( 각 subset 별로 “동일한 칼럼 개수”를 가진다 )
## a) Reconstruction Loss
2가지 옵션
- (1) reconstruct the SUBSET
- (2) reconstruct the WHOLE
b) Contrastive Loss & Distance Loss
( optional loss )
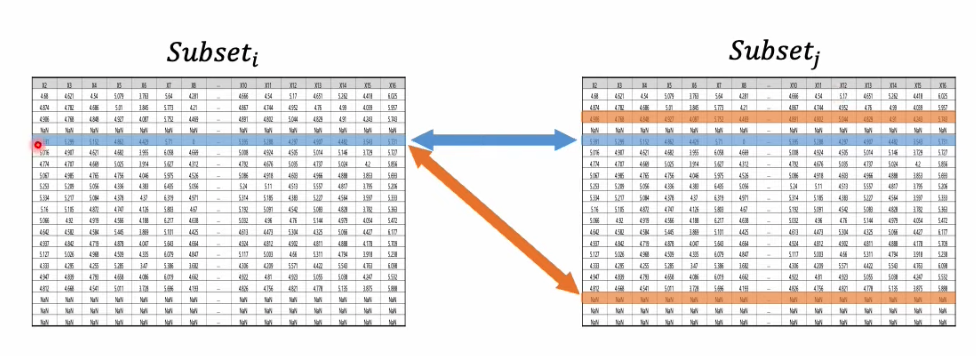
[ Contrastive Loss ]
Q) How to define pos/neg pairs?
A) 서로 다른 2개의 subset ( = 2 views )
- 같은 row : positive pair
- 다른 row : negative pair
( 추가: class 수가 많을 수록, negative pair 가능성 UP \(\rightarrow\) 효과 UP )
[ Distance Loss ]
같은 row, 다른 subset: embedding space에서 가까워야!
\(\rightarrow\) MSE loss 추가 부여 가능
3. SCARF ( ICLR, 2022 )
Self-supervised Contrastive Learning using Random Feature Corruption
Network
- Encoder \(f\) ……….. pretrain
- Pretrain head \(g\) ……….. pretrain
- Cls head \(h\) ……….. finetune
Loss
- Contrastive Loss ……….. pretrain
- Cross-Entropy Loss ……….. finetune
( 노란색: pretrain & 파란색: fine-tune )
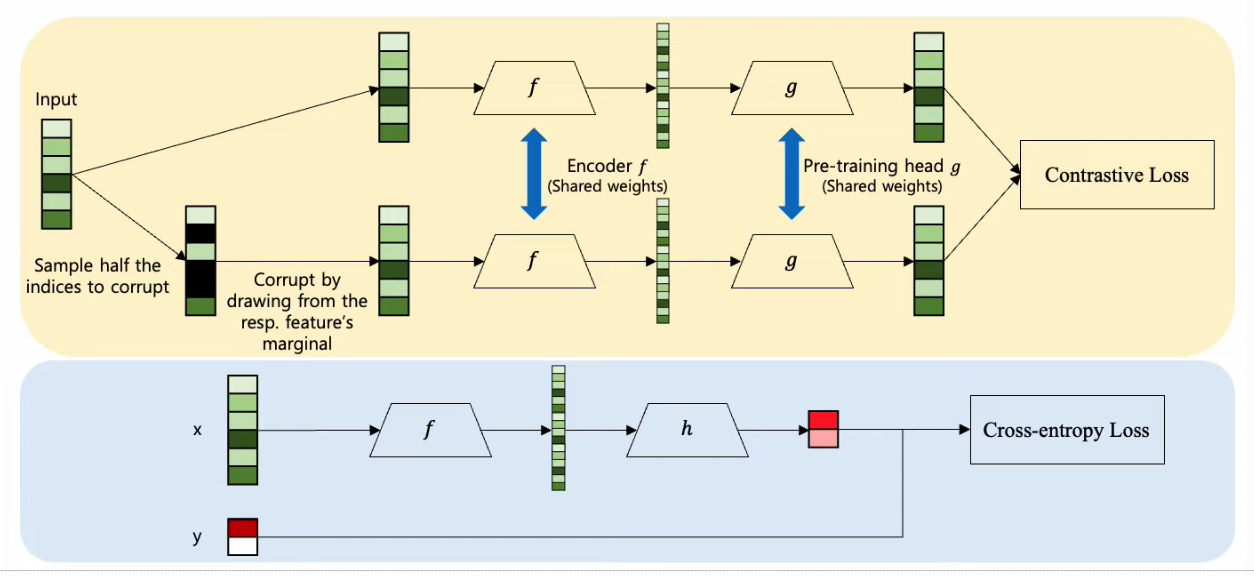
Data augmentation:
- 변수 별 marginal distribution에서 sampling해서 corrupt 시킴
Details
- fine-tune 시, encoder도 재학습한다.
- pretrain 시, reconstruction loss를 사용하지 않음 ( only CL loss )
4. Contrastive Mixup ( 2022 )
Self- and Semi-supervised Learning for Tabular Domain
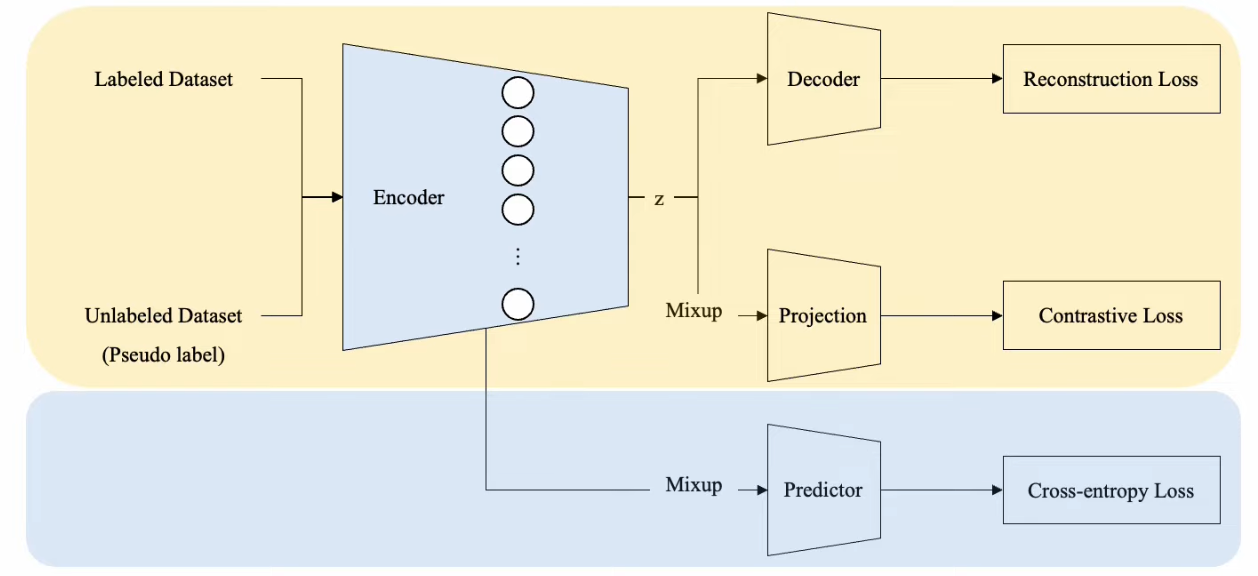
Network
- Encoder ………. pretrain
- Decoder ………. pretrain
- Projection ………. pretrain
- Predictor ………. finetune
Loss
- Reconstruction Loss ………. pretrain
- Contrastive Loss ……….. pretrain
- Cross-Entropy Loss ……….. finetune
a) Mixup ( LABELED data )
- (1) “data space”가 아닌 “embedding space”에서 진행
- (\(\because\) categorical var는 섞을 수 없음)
- (2) “동일한 label”을 가진 sample 간에서만 진행
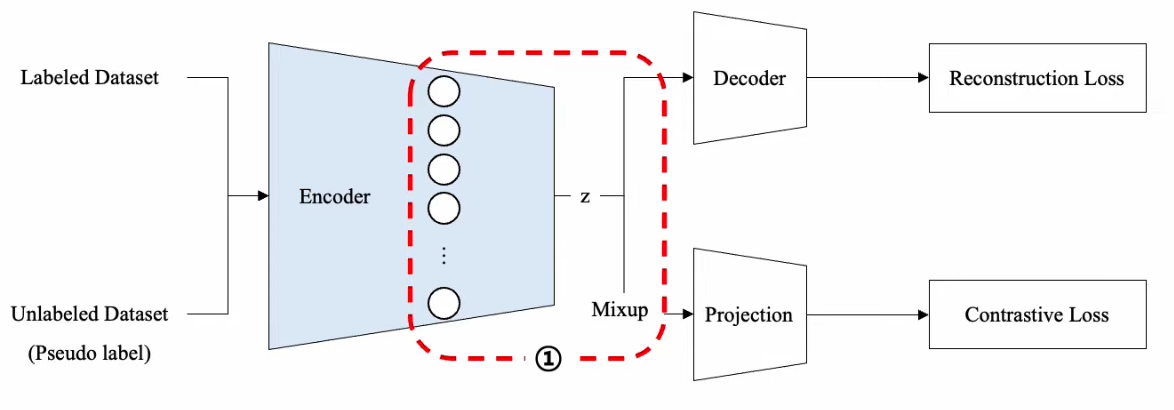
b) Pseudo-label ( UNLABELED data )
- embedding space에서 가장 유사한 labeled data의 label을 사용
- 매 epoch마다 pseudo-label이 변화(update)함
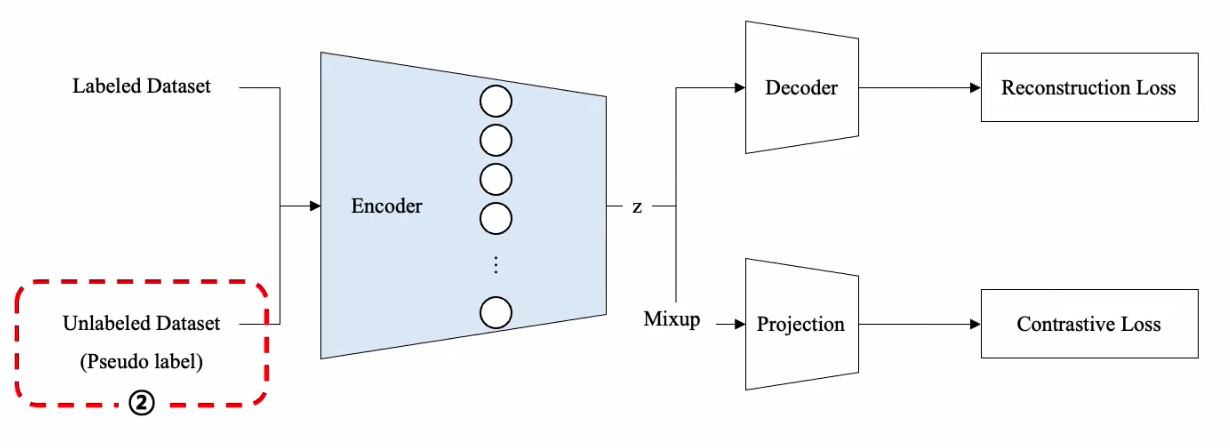
c) Overall Procedure
( 참고: pseudo-label은 \(K+1\) 번째 epoch 이후로 진행 … 그 이전까지는 labeled data로만 )
Reconstruction Loss
- Labeled + Unlabeled data
Contrastive Loss
- Labeled data ( with Mixup )
Contrastive Loss
- Unlabeled Loss (K+1번째 epoch 이후)
d) Fine-tune
Labeled data 뿐만 아니라, Unlabeled data ( + pseudo-label )도 함께 사용