
Dilated Recurrent Neural Networks (2017)
Contents
- Abstract
- Introduction
- Dilated RNN
- Dilated recurrent skip-connection
- Exponentially Increasing Dilation
0. Abstract
RNN on long sequence… difficult!
[ 3 main challenges ]
- 1) complex dependencies
-
2) vanishing / exploding gradients
- 3) efficient parallelization
Simple, yet effective RNN structure, DilatedRNN
- key : dilated recurrent skip connections
- advantages
- reduce # of parameters
- enhance training efficiency
- match SOTA
1. Introduction
attempts to overcome problems of RNNs
- LSTM, GRU, clockwork RNNs, phased LSTM, hierarchical multi-scale RNNs
Dilated CNNs
-
length of dependencies captured by dilated CNN is limited by its kernel size,
whereas an RNN’s autoregressive modeling can capture potentially infinitely long dependencies
\(\rightarrow\) introduce DilatedRNN
2. Dilated RNN
main ingredients of Dilated RNN
- 1) Dilated recurrent skip-connection
- 2) use of exponentially increasing dilation
(1) Dilated recurrent skip-connection
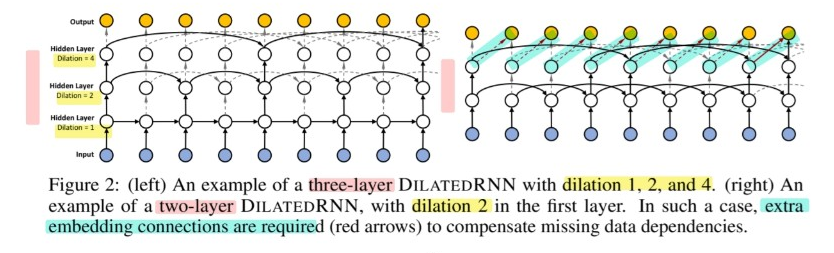
(2) Exponentially Increasing Dilation
-
stack dilated recurrent layers
- (similar to WaveNet) dilation increases exponentially across layers
- \(s^{(l)}\) : dilation of the \(l\)-th layer
- \(s^{(l)}=M^{l-1}, l=1, \cdots, L\).
- ex) figure 2 depicts an example with \(L=3\) and \(M=2\).
Benefits
- 1) makes different layers focus on different temporal resolutions
- 2) reduces the average length of paths between nodes at different timestamp
Generalized Dilated RNN
- does not start at one, but \(M^{l_{0}}\)
- \(s^{(l)}=M^{\left(l-1+l_{0}\right)}, l=1, \cdots, L \text { and } l_{0} \geq 0\).