
Automatic Speech Recognition (ASR)
참고 :https://ratsgo.github.io/speechbook/docs/introduction
1. Introduction
Automatic Speech Recognition ( 자동 음성 인식 )
ASR 모델 = (1) + (2)
- (1) Acoustic model ( 음향 모델 )
- Ex) (기존) HMM, GMM
- (2) Language model ( 언어 모델 )
- ex) (기존) n-gram
2. Problem Setting
(1) Automatic Speech Recognition 이란
= 음성 신호(X)를 단어/음소(Y)로 변환하기
= speech2text
\(\rightarrow\) \(\hat{Y}=\underset{Y}{\operatorname{argmax}} P(Y \mid X)\).
(2) ASR + Bayes Theorem
-
문제점 : 사람마다 말하는 스타일이 상이함!
-
해결책 : direct하게 \(P(Y \mid X)\) 를 추정하는 대신, Bayes Theorem을 사용하자!
( with 2-step procedure )
ex) 2 종류의 단어/음소 ( = \(Y_1\) , \(Y_2\) )
\(\frac{P\left(X \mid Y_1\right) P\left(Y_1\right)}{P(X)}>\frac{P\left(X \mid Y_2\right) P\left(Y_2\right)}{P(X)}\).
- \(P(X \mid Y)\) : Acoustic model
- \(P(Y)\) : Language model
\(\rightarrow\) \(\hat{Y}=\underset{Y}{\operatorname{argmax}} P(X \mid Y) P(Y)\).
3. Architecture
(1) Acoustic Model ( 음향 모델 ) : \(P(X \mid Y)\)
음소/단어 \(Y\)가 주어졌을 때, 음향 신호 \(X\) 가 나올 확률
기존에는 HMM, GMM등이 많이 사용됨
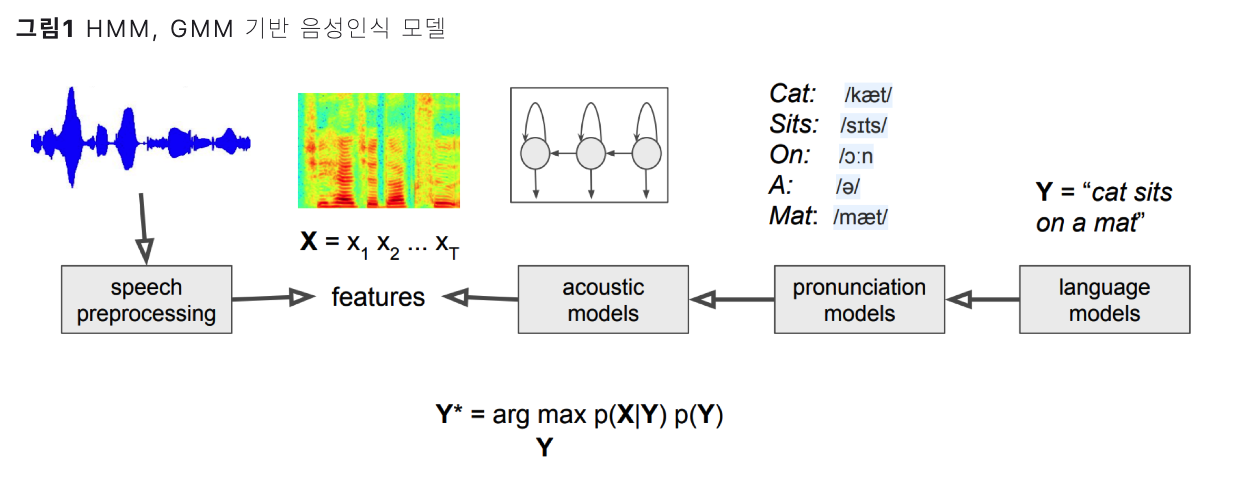
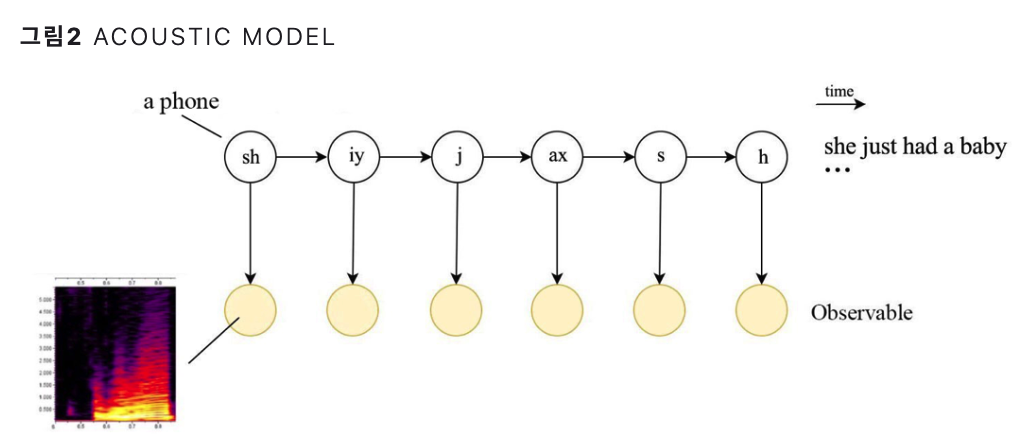
(2) Language Model ( 언어 모델 )
음소/단어 \(Y\)가 나올 확률
기존에는 n-gram 등의 모델 등이 사용됨
\(\rightarrow\) 요즈음은 위 (1), (2) 모두 DL 기반으로 바뀌는 중!
( + \(P(Y \mid X)\) 를 direct하게 추정하는 e2e 모델들도 나오는 중 )
4. Acoustic Features
Acoustic Model ( 음향 모델, \(P(X \mid Y)\) )의 입력으로 사용하는 feature들
\(\rightarrow\) 대표적으로 MFCCs
MFCCs (Mel-Frequency Cepstral Coefficients)
- key idea: 사람이 잘 인식할 수 있는 특성 부각 & 그렇지 않은 특성 생략
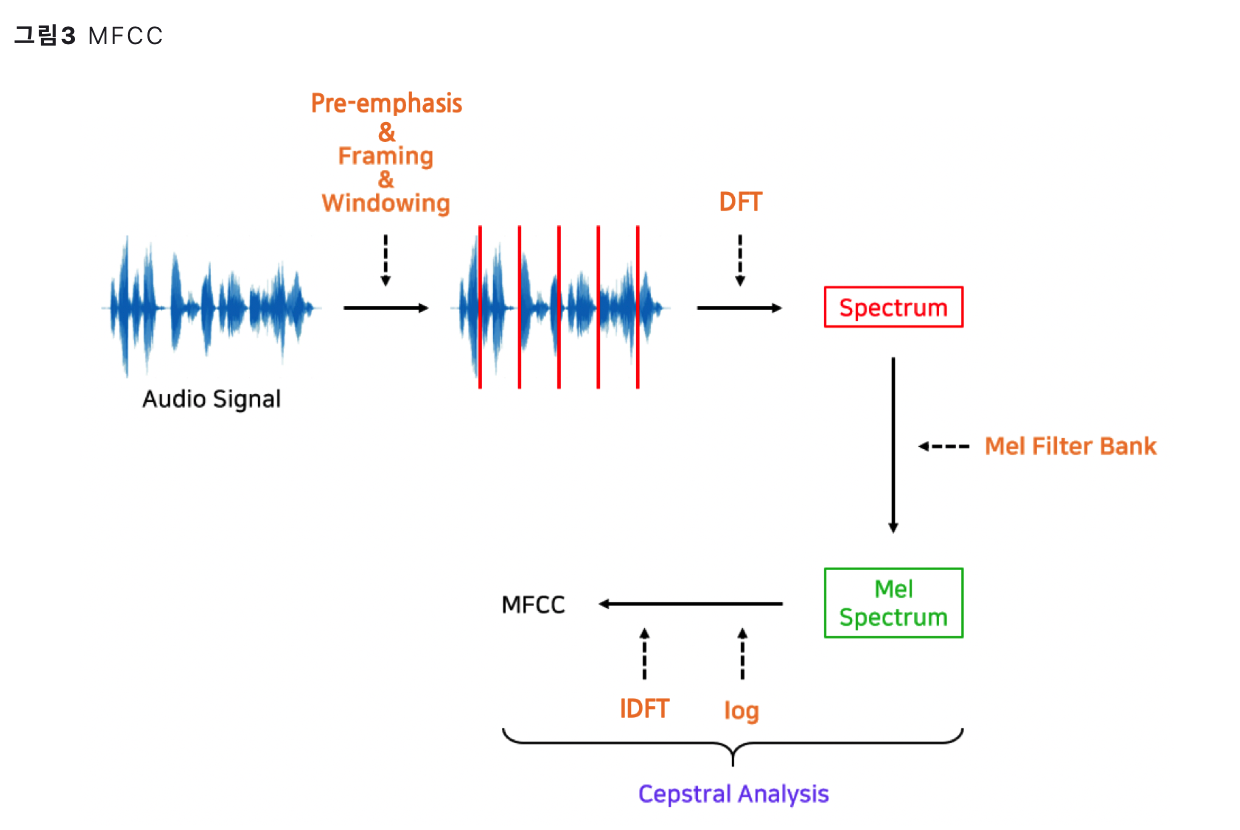
HOWEVER, 요즈음은 acoustic feature 추출 자체도, DL로써 하는 경향
- ex) Wav2Vec, SincNet