
Reasoning over Time Series with LLMs
참고 자료:
- https://dsba.snu.ac.kr/seminar/?mod=document&uid=3106
-
https://www.youtube.com/watch?v=MpbVuXS5ElA
- Merrill, Mike A., et al. “Language models still struggle to zero-shot reason about time series.” EMNLP, 2024
Contents
- Introduction
- Motivation
- TS Reasoning
- LLM for TS
- Language Models Still Struggle to Zero-shot Reason about Time Series
- TS Reasoning Task
- Dataset
- Results
- Summary
1. Introduction
(1) Motivation
TS & LLM
- a) 기존 TS 연구: (textual 대신) numerical value에만 집중
- b) 기존 LLM 연구: 다양한 context 파악 가능, but TS에서의 활용은 아직
\(\rightarrow\) LLM을 활용하여 TS에 대해 reasoning을 해보자!
Example)
- Kong Yaxuan, et al. “Time-MQA: Time Senes Mult-Task Question Answering with Context Enhancement.” arXiv preprint ar00. 2503.01875 (2025).
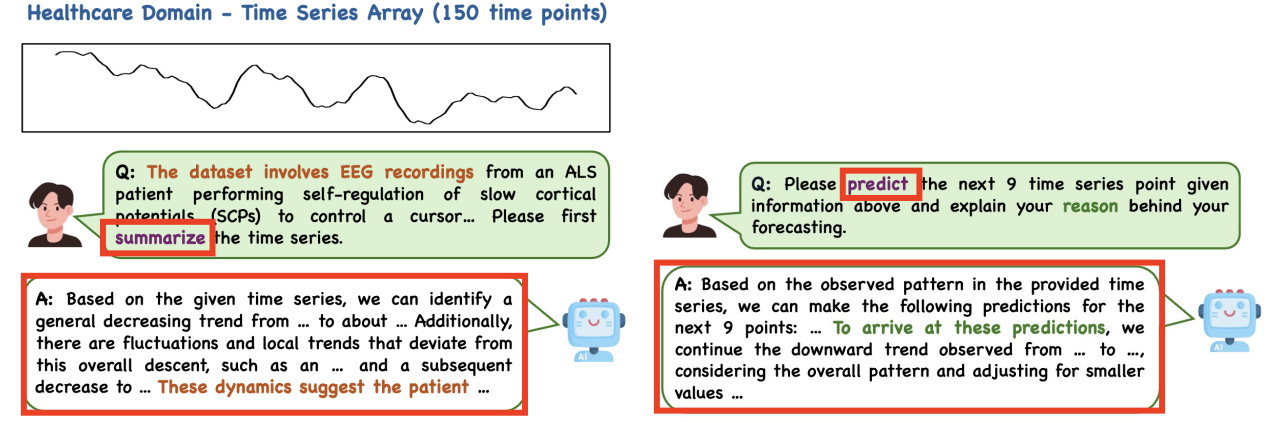
(2) TS Reasoning
특정 task 국한 X
\(\rightarrow\) 사람처럼 논리적으로 시계열 데이터를 이해 & 해석 가능! (context-awareness)
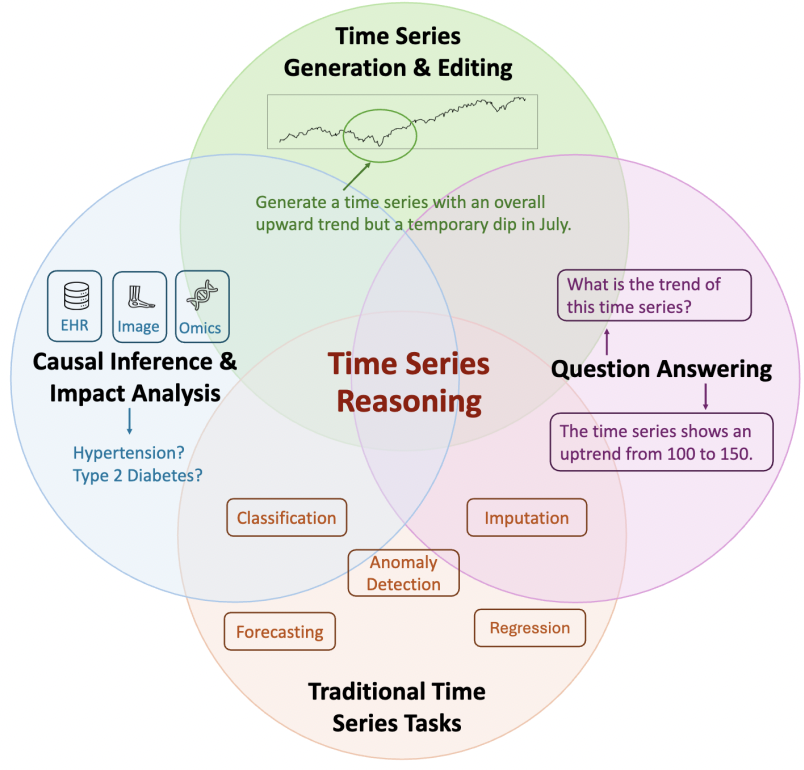
Kong, Yaxuan, et al, “Position: Empowering Time Series Reasoning with Multimodal LLMs.” arXiv preprint arXov-2502.01477 (2025).
(3) LLM for TS
LLM이 TS 분야에 적용된 사례는 꽤 있다!
주로 Model 관점에서, 크게 2가지 방식으로:
- (1) Prompt-engineering approaches
- TS as a Text (Prompt) token
- (2) Aligning approaches
- TS as a TS token
- Align TS & Text modality (feat. PEFT)
2. Language Models Still Struggle to Zero-shot Reason about Time Series (EMNLP 2024)
(1) TS Reasoning task
Notation
\(p_M(Y \mid x, C)=M(Y, x, C)\).
- \(x=\left\{x_0, \cdots, x_n\right\}, x \in \mathbb{R}_n\) : Time Series
- \(M\): LLM
- \(C\): Context token sequence
- \(Y\): Output token sequence
세 종류의 reasoning task
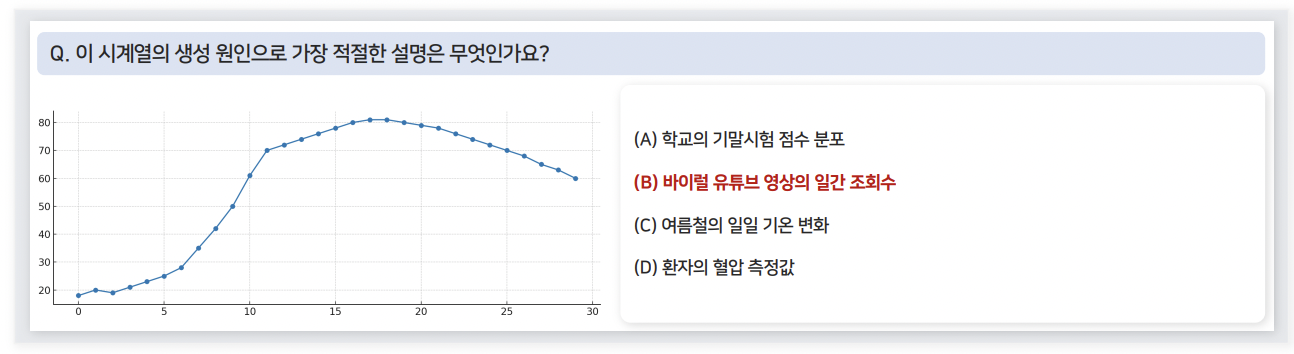
- a) Etiological Reasoning
- b) Question Answering
- c) Context-Aided Forecasting
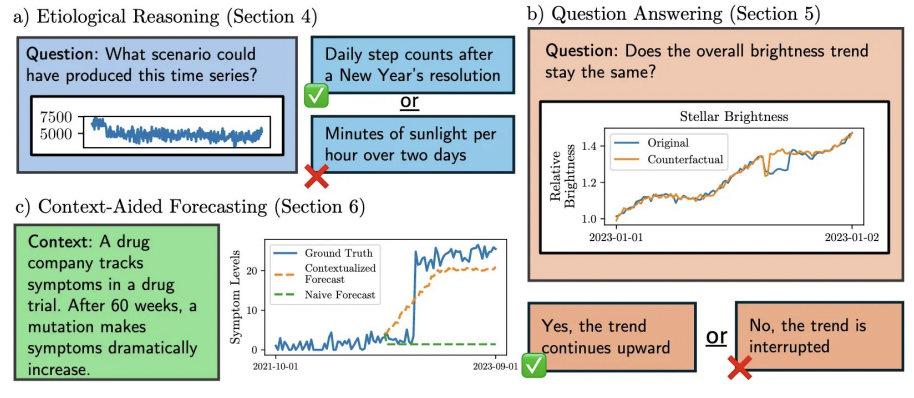
a) Etiological Reasoning
어떠한 원인에 의해 해당 TS가 발생했는지를 추론
- \(p_M\left(D^{+} \mid x, C\right)>p_M\left(D^{-} \mid x, C\right)\).
- 다양한 선택 지 중, “가장 그럴듯한” 원인 선택 (e.g., 4지선다)
b) Question Answering
TS 패턴 기반으로 QA task 풀기
- \(p_M\left(A^{+} \mid x, Q\right)>p_M\left(A^{-} \mid x, Q\right)\).
- 다양한 선택 지 중, “가장 그럴듯한” 원인 선택 (e.g., 4지선다)
- \(p_M\left(A^{+} \mid x, Q\right) \gg p_M\left(A^{+} \mid Q\right)\).
- Text만이 아닌, TS를 활용해서 예측을 하도록 유도
c) Context-Aided Forecasting
과거 TS + Text \(\rightarrow\) 미래 TS 예측
- \(p_M\left(x_{t+1}, \cdots, x_n \mid x_0, \cdots, x_t, D\right)>p_M\left(x_{t+1}, \cdots, x_n \mid x_0, \cdots, x_t\right)\).
- Text 설명이 실제로 예측에 도움을 주어야!
Examples:
a) Etiological Reasoning
b) Question Answering
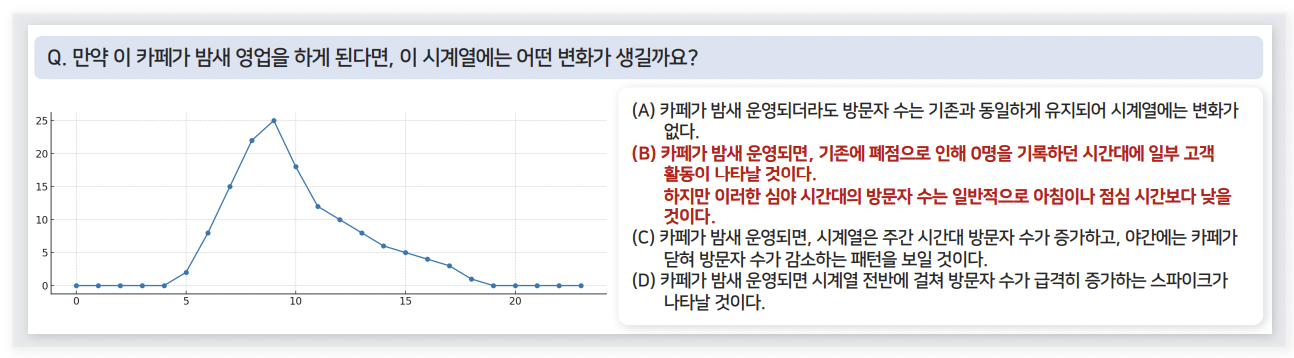
c) Context-Aided Forecasting
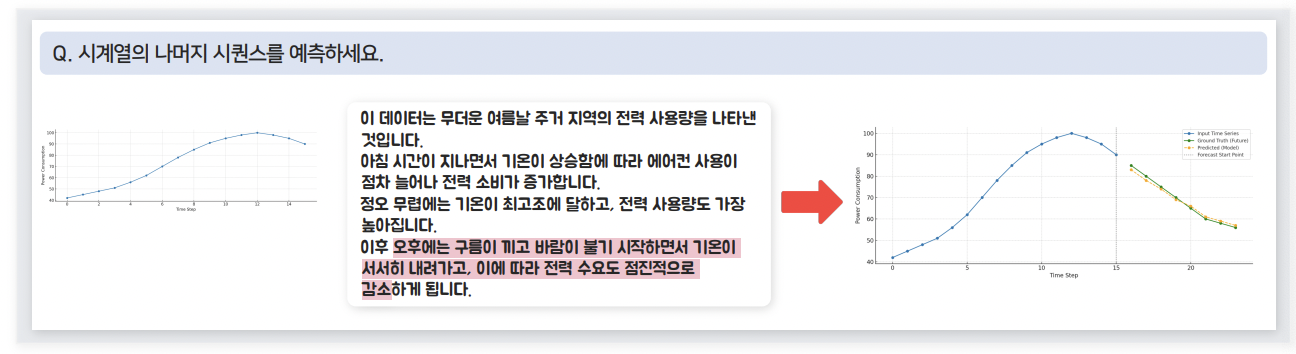
(2) Dataset
Dataset for evaluating TS inference
- LLM의 TS reasoning 능력 평가를 위해, (TS & Text) pair로써의 데이터셋이 필요함
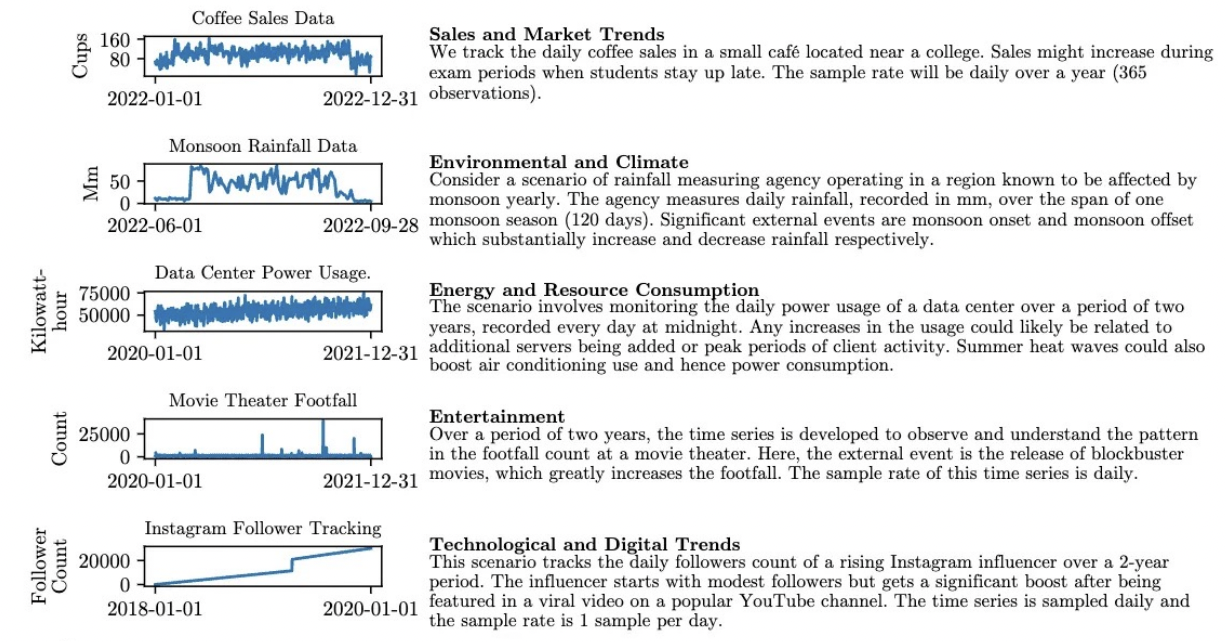
제안: Synthetic multi-domain TS & Text 생성
-
How? GPT-4로 하여금 TS 생성 python script 요청
( \(\because\) Text-generated TS < Code-generated TS )
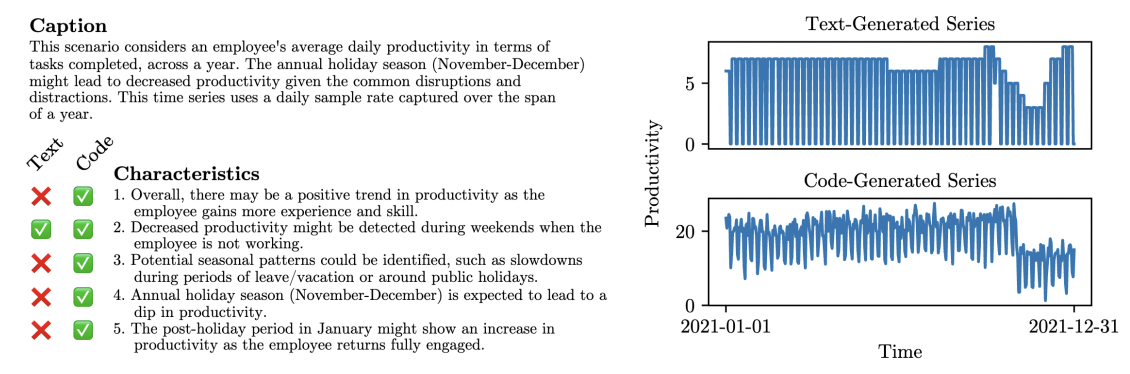
Example

Details
- (For diversity) 20개의 시나리오 제시 & 이전과 중복되지 않도록, 다른 시나리오 생성 요구
- (Filtering) null/\(\infty\) 등의 값 필터링
- 아래와 같은 다양한 multi-domain synthetic dataset 완성
(3) Results
a) Reasoning 1: Etiological Reasoning
- [Format] 4지선다 (1 유관 정답 + 3 무관 오답)
- [Data] TS only
- Numerical value 변환을 통해
- (GPT-4-Vision) TS as graph!
- [Metric] Acc. (%)
Results
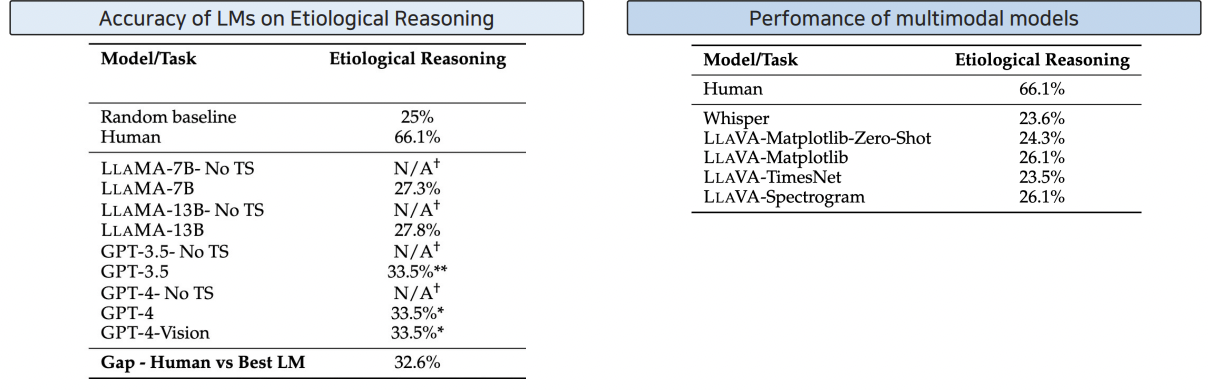
- (1) [Table 1] TS as text: Human 66.1% > Others 2,30% 대
- (2) [Table 2] TS as image: Human 66.1% > Others 20% 대
\(\rightarrow\) 결론: 아직까지 zero-shot LLM이 Etiological Reasoning를 하는데에는 부족하다!
b) Reasoning 2: Question Answering
- [Condition] Answer가 단순히 Question뿐만 아니라, 반드시 “TS를 참고해서” 풀도록해야함.
- [Data] 230,000 multiple choice QA
- [Types]
- 1TS = 1개의 TS 기반 질문
- 2TS = 2개의 TS 기반 “비교” 질문
- [Details] “What-if” 시나리오
- 특정 시나리오 가정 \(\rightarrow\) 이로 인해 생길 수 있는 변화에 대해 설명
What-if 시나리오 예시

(Details) 2TS = 2개의 TS 기반 “비교” 질문
- 2개 TS의 “차이”에 focus
- 구성 방법
- Step 1) What-if 시나리오 생성
- Step 2) 위의 What-if 시나리오에 따라, \(x\)와 쌍을 이룰 \(x^{'}\) 데이터 생성
- Step 3) Question 생성
- \(x\) & \(x^{'}\)의 유사성/차이점 기반한 질문 생성
- TS 없이도 맞출 수 있는 Question은 제거
Results
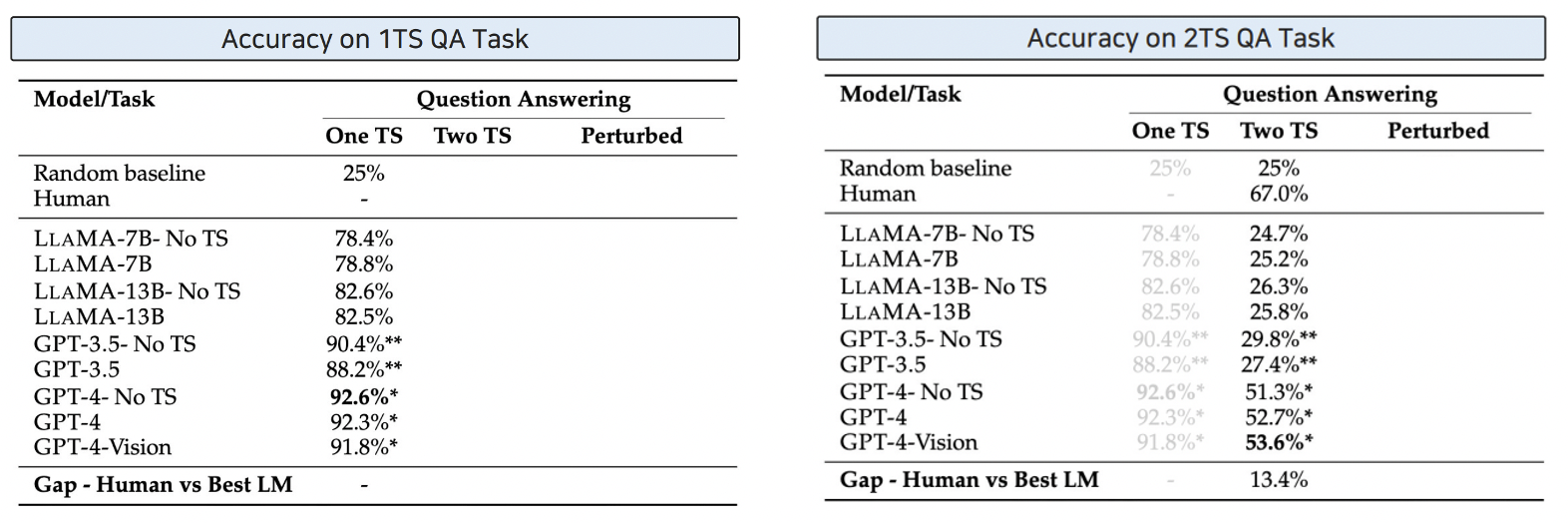
- 1TS: 무의미함. Text만으로도 충분히 맞출 수 있음 ( + TS의 추가 정보가 크게 도움 안됨 )
- 2TS: 마찬가지!
\(\rightarrow\) 결론: 아직까지 zero-shot LLM이 Question Answering을 하는데에는 부족하다!
c) Reasoning 3: Context-Aided Forecasting
- [Condition] 과거 TS & Text 정보 함께
- [Data] Caption + Metadata와 함께, 2000개의 TS 무작위 선택
- [Task] TS의 첫 80%로 나머지 20% 예측
- [Metric] MSE, MAE
Results
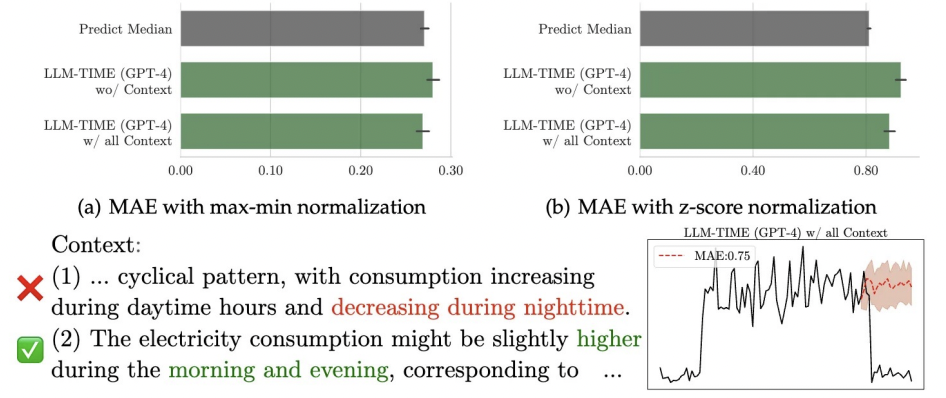
\(\rightarrow\) 결론: 아직까지 zero-shot LLM이 Context-aided Forecasting을 하는데에는 부족하다!
그렇다고 무의미하다 보는 것은 아님!
(1) (쉬운 & 어려운 TS에서) caption은 모두 도움이 된다!
- 쉬운 TS

- 어려운 TS

(4) Summary
SOTA LLM들도 아직까지 TS Reasoning task를 잘 못푼다!
-
TS 도움 없이, Text 정보만으로도 어느정도 잘 맞춘다
= LLM을 활용하여 문제를 생성했을 당시의 정보를 기반으로 함!