
A Comprehensive Survey on Test-Time Adaptation under Distribution Shifts
https://arxiv.org/pdf/2303.15361.pdf
0. Abstract
Robust model = generalize well to test sample
-
Problem) performance drop due to UNKNOWN test distribution
-
Solution) TTA (Test-time adaptation)
TTA (Test-time adaptation)
- Adapt a pre-trainedd model to unlabeled data DURING TESTING
- Three categories
- (1) SFDA (Source-free domain adaptation = Test-time domain adaptation)
- (2) TTBA (Test-time batch adaptation)
- (3) OTTA (Online test-time adaptation)
- (4) TTPA (Test-time prior adaptation)
1. Introduction
Traditional ML: assume train distn = test distn
\(\rightarrow\) Not true in real world
To solve this issue…
- (1) DG (Domain Generalization)
- Inductive setting ( only access to train data during training )
- Train a model using data from (one or more) source domains
- Inference on OOD target domain
- (2) DA (Domain Adaptation)
- Transductive setting ( have access to both train & test data for inference )
- Leverage knowledge from a labeled source \(\rightarrow\) unlabeled target domain
- (3) TTA (Test-time Adaptation) \(\rightarrow\) main focus
TTA > (DG, DA)
-
TTA vs. DG
-
DG) operates only on training phase
-
TTA) can access test data from the target domain during test phase
( adaptation with the availability to test data )
-
-
TTA vs. DA
- DA) requires access to both labeled source & unlabeled target
- not suitable for privacy-sensitive applications
- TTA) only requires access to the pretrained model from the source domain
- more secure & practical
- DA) requires access to both labeled source & unlabeled target
Categories of TTA
( Notation: \(m\) unlabeled minibatches \(\left\{b_1, \cdots, b_m\right\}\) at test time )
- (1) SFDA (Source-free domain adaptation = Test-time domain adaptation)
- (2) TTBA (Test-time batch adaptation)
- (3) OTTA (Online test-time adaptation)
- (4) TTPA (Test-time prior adaptation)
-
(1) SFDA
- utilizes all \(m\) test batches for adaptation before generating final predictions
-
(2) TTBA
-
individually adapts the pre-trained model to one or a few instances
( = predictions of each mini-batch are independent of the predictions for the other mini-batches )
-
-
(3) OTTA
-
adapts the pre-trained model to the target data \(\left\{b_1, \cdots, b_m\right\}\) in an online manner
( = each mini-batch can only be observed only once )
-
-
(Not main focus) (4) TTPA (Test-time prior adaptation)
- (1)~(3) : Data shift ( = covariate shift = \(X\) shift )
- (4) : Label shift ( = \(Y\) shift )
Outlines
-
Concept of TTA & view four topics ( SFDA, TTBA, OTTA, TTPA )
-
Advanced algorithms of these topics
2. Related Research Topics
(1) DA & DG
Domain Shift
- (1) Covariate (\(X\)) shift
- (2) Label (\(Y\)) shift
DA & DG: Both are transfer learning techniques
-
DA: Domain Adaptaiton
-
DG: Domain Generralization
DA vs. DG:
- DG: inductive
- Train model using (source) train data & Inference (target) test data
- DA: transductive
- Inference using both (source) train & (target) test data
- Example of transductive model) KNN
- 4 categories
- a) Input-level translation
- b) Feature-level alignment
- c) Output-level regularization
- d) Prior estimation
- Inference using both (source) train & (target) test data
DA method for SFDA
SFDA problem can be solved using DA methods,
if it is possible to generate TRAINING DATA from the source model
- (1) One-shot DA
- Adapting to only “ONE unlabeled target” instance & “source” data
- (2) Online DA
- Similar to One-shot DA, but streaming target data ( = deleted after adaptation )
- (3) Federated DA
- Acquires feedback from the target data to source data
(2) Hypotheseis Transfer Learning (HTL)
Pretrained models retain infformation about previously encountered tasks
\(\rightarrow\) Still require a certain number of labeled data in target domain
(3) Continual Learning & Meta-Learning
a) Continual Learning (CL)
- Learning a model for mulitple tasks in a SEQUENCE
- Knowledge from previous tasks is gradually accumulated
- Three scenarios
- (1) Task-incremental
- (2) Domain-incremental
- (3) Class-incremental
- Three categories
- (1) Rehearsal-based
- (2) Parameter-based regularization
- (3) Generative-based
- (1) vs. (2,3)
- (1) Access to training data of previous task (O)
- (2,3) Access to training data of previous task (X)
b) Meta learning
( Meta Learning = Learning to learn )
-
Similar to CL
-
But with training data randomly drawn from a task distribution
& test data are tasks with few examples
-
Offers a solution for TTA w/o incorporation of test data in the meta-training stage
(4) Data-Free Knowledge Distillation
Knowledge Distillation (KD)
- Knowledge from teacher model \(\rightarrow\) student model
- To address privacy concerns … Data-Free KD is proposed
Two categories of Data-Free KD
- (1) Adversarial training
- Generates worst-case synthetic samples for student learning
- (2) Data prior matching
- Generates synthetic samples that satisfies certain priors
- i.e.) class prior, batch-norm statistics
- Generates synthetic samples that satisfies certain priors
Compared with TTA…
- Data-Free KD focues on
- transfer between models (O)
- transfer between datasets (X)
(5) Self-supervised & Semi-supervised Learning
Self-supervised Learning
- Learn from unlabeled data
Semi-supervised Learning
-
Learning from both labeled & unlabeled data
- Common objective = (1) + (2)
- (1) Supervised Loss ( calculated with labeled data )
- (2) Unsupervised Loss ( calculated with labeled + unlabeled data )
-
Depending on Loss (2), can be divieded into ..
- a) Self-training
- b) Consistency regularization
- c) Model variations
( https://seunghan96.github.io/ssl/SemiSL_intro/ )
Self- & Semi- SL can also be incorporated to unsupervisedly update the pretrained model for TTA tasks
3. Source-Free Domain Adaptation (SFDA)
(1) Problem Definition
a) Domain
Domain \(\mathcal{D}\) is \(p(x, y)\) defined on space \(\mathcal{X} \times \mathcal{Y}\),
- \(x \in \mathcal{X}\) and \(y \in \mathcal{Y}\) denote the input & output
Notation
-
Target domain \(p_{\mathcal{T}}(x, y)\)
-
domain of our interest
-
unlabeled data
-
- Source domain \(p_{\mathcal{S}}(x, y)\)
- labeled data
- ( Unless otherwise specified, \(\mathcal{Y}\) is a \(C\)-cardinality label set )
b) Settings
Settings
- Labeled source domain \(\mathcal{D}_{\mathcal{S}}=\left\{\left(x_1, y_1\right), \ldots,\left(x_{n_s}, y_{n_s}\right)\right\}\)
-
Unlabeled target domain \(\mathcal{D}_{\mathcal{T}}=\left\{x_1, \ldots, x_{n_t}\right\}\)
-
Data distribution shifts: \(\mathcal{X}_{\mathcal{S}}=\mathcal{X}_{\mathcal{T}}, p_{\mathcal{S}}(x) \neq p_{\mathcal{T}}(x)\),
including the covariate shift assumption \(\left(p_{\mathcal{S}}(y \mid x)=\right.\) \(p_{\mathcal{T}}(y \mid x)\) ).
Unsupervised domain adaptation (UDA)
= leverage knowledge in \(\mathcal{D}_{\mathcal{S}}\) to help infer the label of each target sample in \(\mathcal{D}_{\mathcal{T}}\).
Three scenarios
- (1) Source classifier with accessible models and parameters
- (2) Source classifier as a black-box model
- (3) Source class means as representatives.
\(\rightarrow\) Utilizes all the test data to adjust the classifier learned from the training data
c) Source-free Domain Adaptation (SFDA)
Notation
- Pretrained classifier \(f_{\mathcal{S}}: \mathcal{X}_{\mathcal{S}} \rightarrow \mathcal{Y}_{\mathcal{S}}\) on the \(\mathcal{D}_{\mathcal{S}}\)
- Unlabeled target domain \(\mathcal{D}_{\mathcal{T}}\),
SFDA:
-
aims to leverage the labeled knowledge implied in \(f_{\mathcal{S}}\)
to infer labels of all the samples in \(\mathcal{D}_{\mathcal{T}}\),
in a transductive learning manner.
-
All test data (target data) are required to be seen during adaptation.
(2) Taxonomy on SFDA algorithm
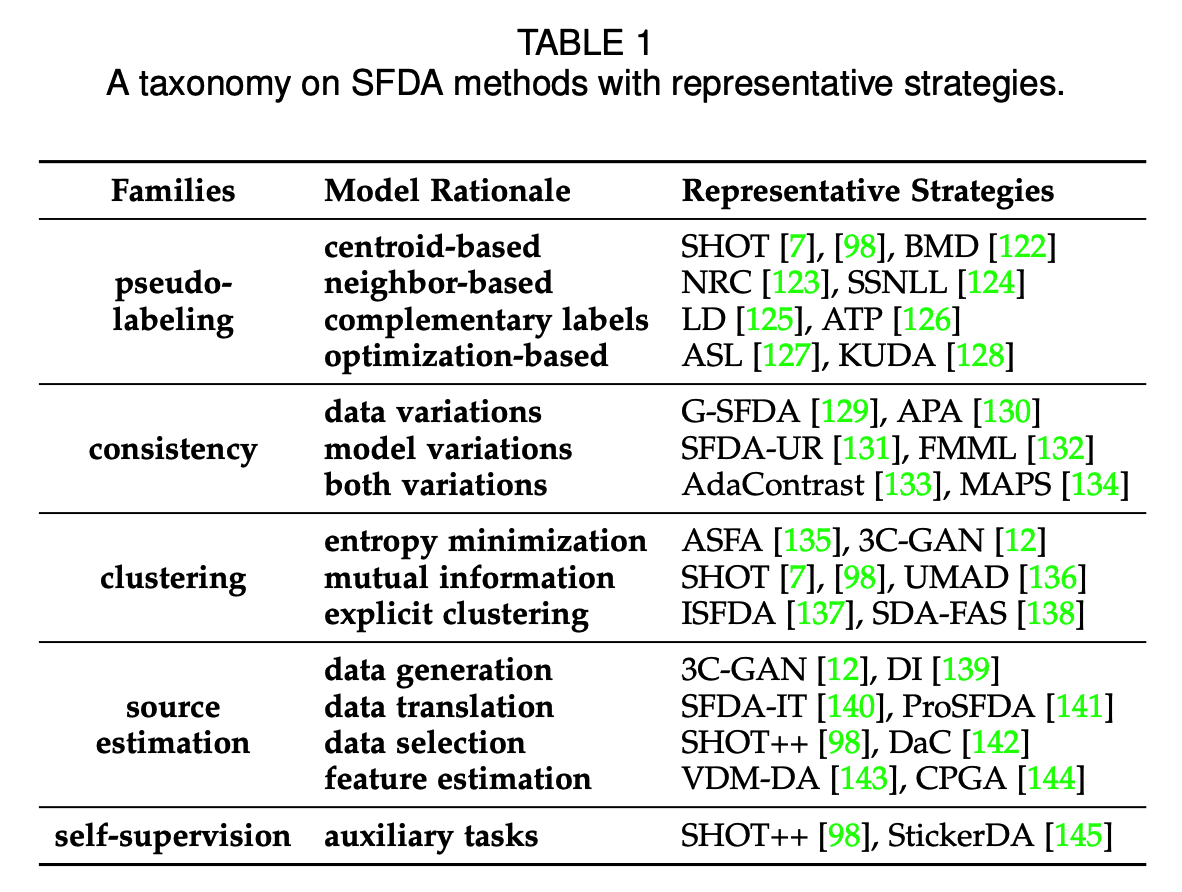
a) Pseudo-labeling
- Centroid-based pseudo labels
- Neighbor-based pseudo labels
- Complementary pseudo labels
- Optimization-based pseudo labels
- Ensemble-based pseudo labels
b) Consistency Training
- Consistency under data variations
- Consistency under model variations
-
Consistency under data & model variations
- Miscellaneous consistency regularization
c) Clustering-based Training
- Entropy minimization
- Mutual-information maximization
- Explicit clustering
d) Source Distribution Estimation
- Data generation
- Data translation
- Data selection
- Feature estimation
- Virtual doomain alignment
e) Others
-
(3.2.5) Self-superviesed Learning
- (3.2.6) Optimization Strategy
- (3.2.7) Beyond Vanilla Source Model
(3) Learning Scenarios of SFDA algorithms
a) Closed-set vs. Open-set
( Most existing SFDA methods focus on a closed-set scenario )
- Closed- set: \(\mathcal{C}_s=\mathcal{C}_t\)
- Partial-set: \(\mathcal{C}_t \subset \mathcal{C}_s\)
- Open-set: \(\mathcal{C}_s \subset \mathcal{C}_t\)
- Open-partial-set: \(\left(\mathcal{C}_s \backslash \mathcal{C}_t \neq \emptyset, \mathcal{C}_t \backslash \mathcal{C}_s \neq \emptyset\right.\))
Several recent studies even develop a unified framework for both open-set and open-partial-set scenarios.
b) Single-source vs. Multi-source
c) Single-target vs. Multi-target
Multi-target DA
-
Multiple unlabeled target domains exist at the same time
-
Domain label of each target data may be even unknown
-
Each target domain may come in a streaming manner
\(\rightarrow\) model is successively adapted to different target domains
d) Unsupervised vs. Semi-supervised
e) White-box vs. Black-box
f) Active SFDA
Few target data can be selected to be labeled by human annotators
e) Imbalanced SFDA
ex) ISFDA: class-imbalanced SFDA
- source & tareget label distns are different & extremely imbalanced