( 참고 : Fast Campus 금융공학/퀀트 강의 )
1. 시계열 데이터 분석 소개
(1) intro
-
시계열 : 시간의 흐름에 따라 기록된 데이터
\(\rightarrow\) 과거 & 현재 사이의 상관관계 존재
- 시계열 예측 : 과거 데이터 긱반으로, 현재 설명 & 미래 예측
-
활용 분야 : ex) 거시 경제 지표
- 계절(Trend), 계절성 (Seasonality), 경기 순환(Cycle) 분석
- 시계열 vs 회귀
- 회귀 : x & y 사이의 관계
- 시계열 : 현재 x & 과거 x 사이의 관계
(2) 시계열 분석을 위한 수학적 모델
- ARIMA : 자기상관관계를 모델링
- 분해법 (Decomposotion) : Trend & Seasonality로 분해
- 시계열 회귀 분석 : 회귀 모형 + 시계열 모형
- TBATS : 분해법 + ARIMA
- NN을 사용한 시계열 모형
(3) R 코드
데이터를 ts 오브젝트로 변환해야
( from data.frame / vetor to ts )
-
ts(data, frequency=12)( 주기가 12인 데이터로 예상할 경우 )
시계열 그래프
- 1) 데이터의 class가
ts인 경우 :plot(data) - 2) 데이터의 class가
ts가 아닌 경우 :ts.plot(data) - 3)
ggplot2사용해서autoplot(data, ts.colour='red', ts.linetype='dashed')
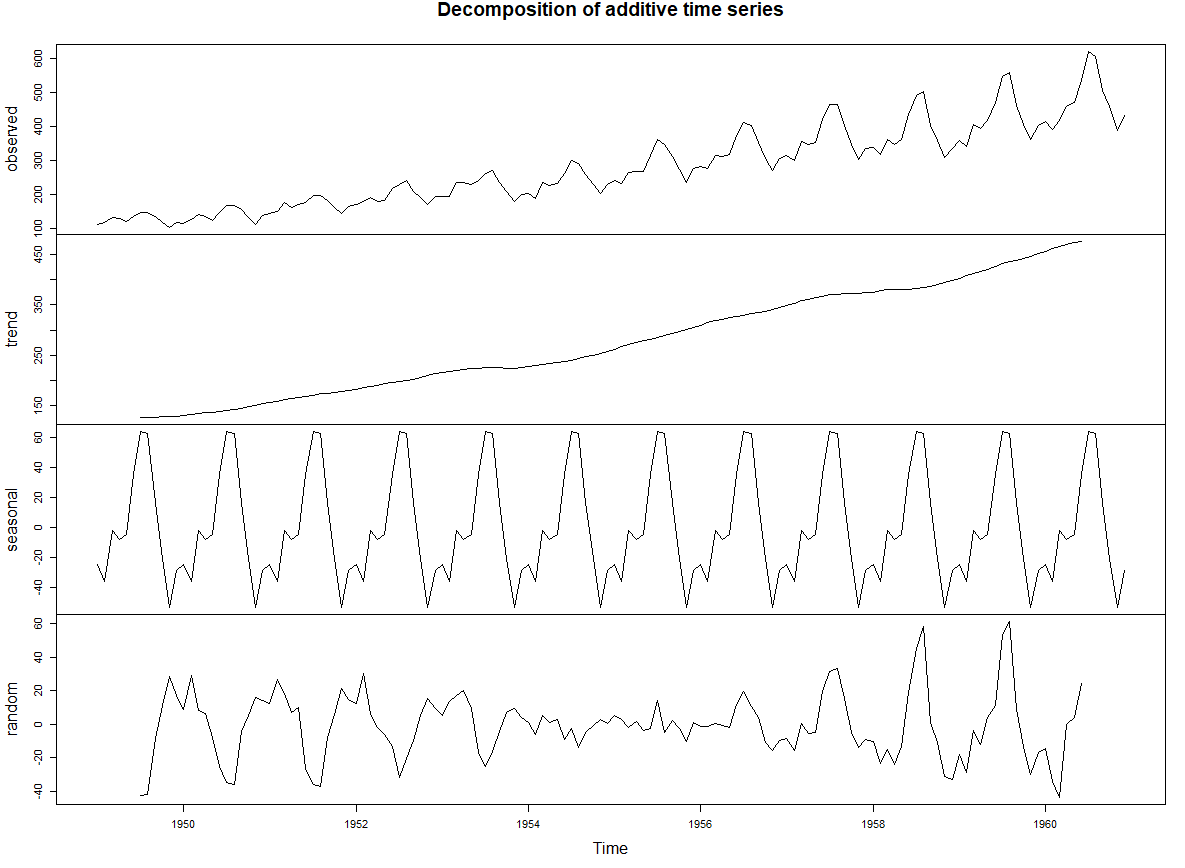
(4) 시계열의 구성 요소
TS = Trend + Seasonality + ERROR
추세(Trend) & 계절성(Seasonality)
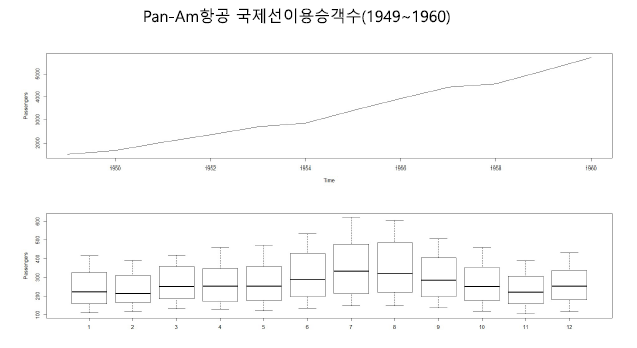
Example 1
-
ex) Trend : 추세로써 “각 연도 별 합계”
-
ex) 계절성 : 월별 분포
par(mfrow=c(2,1))
plot(aggregate(AirPassengers), ylab = "Passengers")
boxplot(AirPassengers~cycle(AirPassengers), ylab = "Passengers")
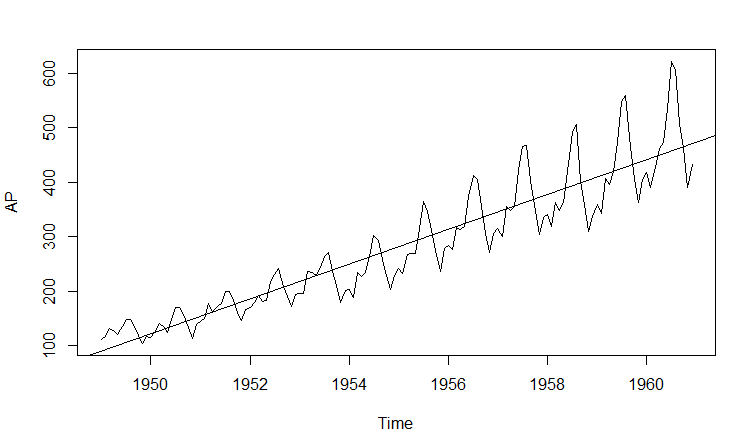
Example 2)
- ex) Trend : 시간으로 1차 회귀분석
AP.time = time(AP)
Reg = lm(AP~AP.time)
plot(AP)
abline(Reg)
Example 3)
decompose함수
plot(decompose(AP))