Contrastive Learning of General Purpose Audio Representations (ICASSP, 2020)
https://arxiv.org/pdf/2010.10915.pdf
Contents
- Abstract
- Introduction
- Method
- Experiments
Abstract
COLA
- Contrastve Learning (CL) for learning a general-purpose representation of audio
- Pos & Neg
- Pos : from same recording
- Neg : from different recording
- build on top of recent advances in CL for computer vision and reinforcement learning
Experiments
-
Pre-train embeddings on the large-scale Audioset
-
Transfer to 9 diverse classification tasks
- including speech, music, animal sounds, and acoustic scenes
1. Introduction
Discriminative Pre-Training (DPT)
- learns a representation from pairs of similar inputs from unlabeled data & trains a model to recognize similar elements among negative distractors
- computationally efficient as it avoids input reconstruction entirely.
DPT models for audio
- used a metric learning approach with a triplet loss
- instance generation is achieved through …
- noise injection
- shifting along time-frequency dimensions
- extracting samples in temporally close neighborhoods.
Previous works
-
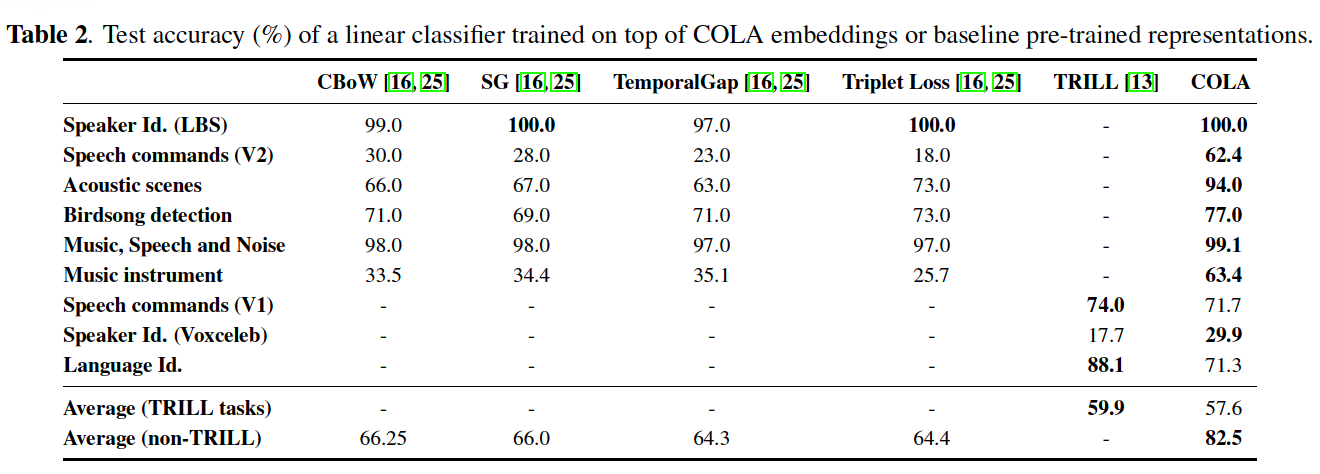
[13] : proposed a benchmark for comparing speech representations on non-semantic tasks.
-
[16] Audio2vec : pretext task of estimating temporal distance between audio segments.
Despite recent progress… two limitations!
Limitation 1: usualy focuses on speech tasks and ignores other audio tasks
- ex) acoustic scene detection or animal vocalizations.
Limitation2 : triplet-based objectives heavily rely on the mining of negative samples
- quality of learned features can vary significantly with the sample generation scheme.
COLA (COntrastive Learning for Audio)
-
POS = simply sample segments from the same audio clip
\(\rightarrow\) avoids exploring augmentation strategies entirely
-
NEG = simply associate segments from different clips in the same batch
\(\rightarrow\) does not require maintaining a memory bank of distractors as in MOCO
- Advantages
- allows us to consider a large number of negatives for each positive pair
- bypass the need for a careful choice of negative examples
- Different from CPC [2] as it does not predict future latent representations from past ones
Experiments
Diverse downstream tasks
- including speech, music, acoustic scenes, and animal sounds
Pre-training on the large-scale AudioSet
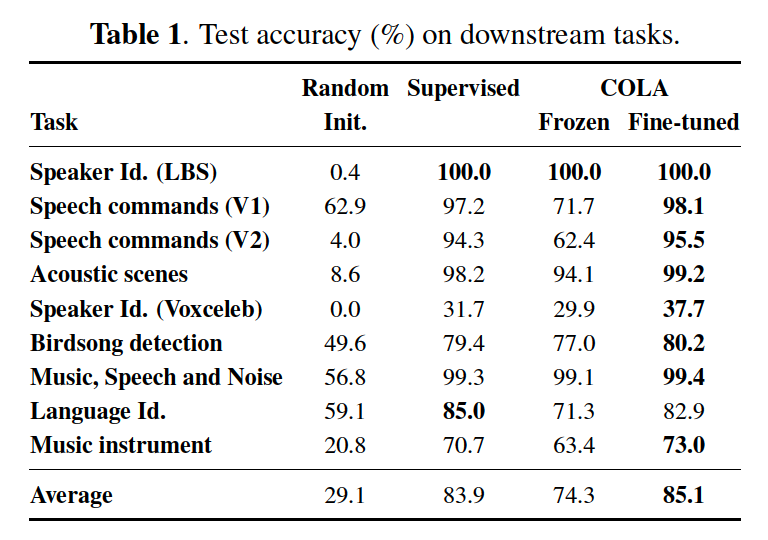
Downstream task : linear classifier trained over a COLA embedding gets close to the performance of a fully-supervised in-domain CNN
2. Method
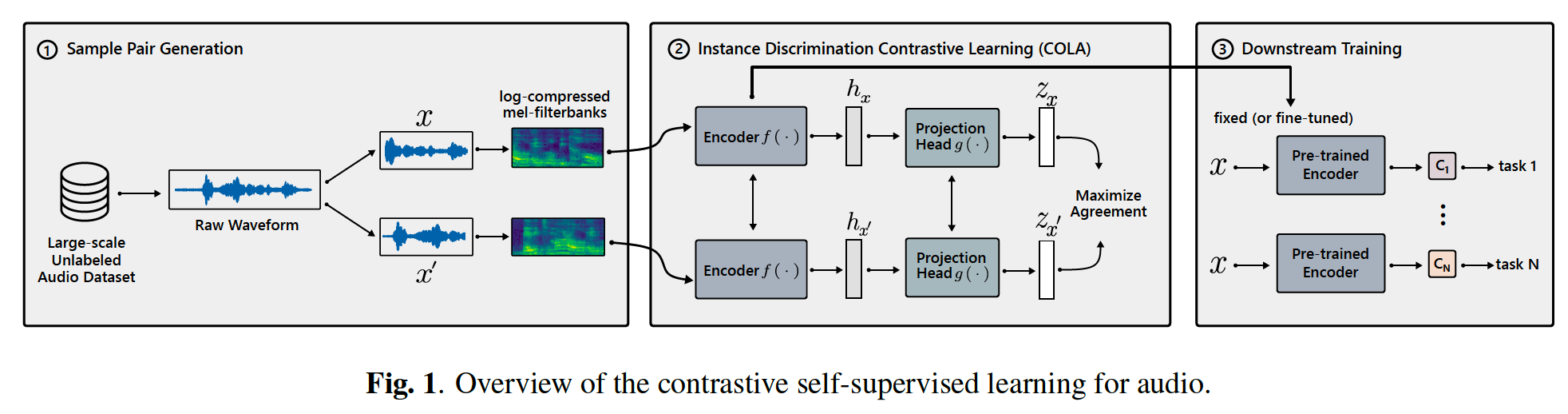
( Encoder = CNN )
Notation
- encoder \(f\)
- log-compressed melfilterbanks \(\mathbf{x} \in \mathbb{R}^{N \times T}\)
- \(N\) : # of frequency bins
- \(T\) : # of time frames
- projector (shallow NN) : \(g\)
Procedure
-
step 1) \(h=f(x) \in \mathbb{R}^d\).
-
step 2) \(z=\) \(g(h)\)
- where bilinear comparisons are performed
( bilinear parameters: \(W\) )
- step 3) bilinear similarity : \(\mathrm{s}\left(x, x^{\prime}\right)=g(f(x))^{\top} W g\left(f\left(x^{\prime}\right)\right)\).
- less common that cosine similarity
- experiment : bilinear sim > cosine sim
- step 4) \(\mathcal{L}=-\log \frac{\exp \left(\mathrm{s}\left(x, x^{+}\right)\right)}{\sum \exp \left(\mathrm{s}\left(x, x^{-}\right)\right)}\).
- \(x^{-} \in \mathcal{X}^{-}(x) \cup\left\{x^{+}\right\}\).
3. Experiments