Self-Supervised Learning with Random-Projection Quantizer for Speech Recognition (ICML, 2022)
https://arxiv.org/pdf/2202.01855.pdf
Contents
- Abstract
- Introduction
- Related Work
- SSL with Random Projection Quantizer
- Random-projection Quantizer
- Pre-training
- Fine-tuning
- Understanding the effectiveness of random-projection quantizer
- Experiments
- Data: LibriSpeech
- Data: Multilingual Tasks
- Quantization Quality
- Effect of Pre-training Data Size
Abstract
SSL for speech recognition
Pretext task = predict the masked speech signals, in the form of discrete labels
Discrete labels : generated with a random-projection quantizer
-
Quantizer : projects speech inputs with a randomly initialized matrix
( & does a nearest-neighbor lookup in a randomly-initialized codebook )
-
Random-projection quantizer is not trained!!
( = No update for matrix & codebook )
\(\rightarrow\) makes the approach flexible and is compatible with universal speech recognition architecture.
Experiment on LibriSpeech
- similar word-error-rates as previous work using SSL with non-streaming models
- lower word-error-rates and latency than wav2vec 2.0 and w2v-BERT with streaming models
1. Introduction
Trend of SSL for speech recognition : BERT-inspired algorithms
Challenge in building BERT-style SSL for speech
= to bridge the gap between continuous speech signals and the discrete text tokens
Solution : learning speech representation or quantized representation
2 limitations of integration of representation learning & SSL
- (1) Model architecture limitation
- often requires the model to act the role of providing speech representation while still being effective for the downstream tasks.
- An effective representation model, however, may not always be effective for the downstream tasks.
- For example, a good representation learning model may require accessing the future context of the utterance, while downstream tasks may require a low latency model which prohibits the access of the future context.
- (2) Increased complexity.
- The objectives of representation learning and SSL are not always aligned
- Complexity of designing both algorithms and finding their balance can impede the research development.
- This complexity can also motivate the field toward designing more complicated algorithms instead of finding a simple and effective alternative.
BEST-RQ
BEST-RQ = BERT-based Speech pre-Training with Random-projection Quantizer
- simple and effective SSL algorithm for speech recognition
- Masked Modeling
- (1) mask speech signals
- (2) feed them to the encoder part of the speech recognition model
- (3) predict the masked region based on unmasked parts
- learning targets = labels provided by random-projection quantizer
- random projection quantizer projects speech signals to a randomly initialized matrix, and finds a nearest vector in a randomly initialized codebook
- The index of that vector is the target label
2. Related Work
Previous work on SSL for speech recognition = focus on learning speech representation
wav2vec (Schneider et al., 2019)
- applies CL to learn the future representation based on the past context
vq-wav2vec (Baevski et al., 2020a)
- uses wav2vec to learn the representations & quantizes them to discrete tokens
- performs BERT-style pre-training to further improve the representation learning.
DiscreteBERT (Baevski et al., 2019)
- extends vq-wav2vec by finetuning the BERT-pre-trained model on the downstream tasks.
wav2vec 2.0 (Baevski et al., 2020b)
- uses CL with both past and future context to predict the representation of the masked parts.
HuBERT (Hsu et al., 2021)
-
uses k-means to learn the initial quantizer that maps speech signals to discrete labels
-
performs BERT-style pre-training
( = inputs are masked speech signals & targets are discrete labels )
-
further uses the pretrained model as the new quantizer to train a new iteration of the model
w2v-BERT (Chung et al., 2021)
- uses a sub-network of the model to perform CL to learn speech representation
- use the rest of the network to perform BERT-style pre-training
BERT-RQ
distinguishes from these work in
- avoiding the requirement of representation learning
- separating the quantizer from the speech recognition model
Quantizer
-
project input signals with a random matrix
( = which is similar to performing dimension reduction for the input signals )
-
results = prediction target for SSL
Similar to BEiT (Bao et al., 2021),
- trains a VQ-VAE (van den Oord et al., 2018) as the quantizer
- use the VQ-VAE to perform BERT-style SSL
- (difference) BERT-RQ does not require training the quantizer
3. SSL with Random Projection Quantizer
BEST-RQ
-
applies a random-projection quantizer to map speech signals to discrete labels
-
quantizer randomly initializes a (1) matrix and a (2) codebook
- uses the matrix to project the input speech signals
- uses the codebook to find the nearest vector
( both are fixed during pre-training )
-
input data : normalized to \(N(0,1)\)
\(\rightarrow\) critical for preventing the random projection to collapse to a small subset of codes.
-
masked parts : replaced with a noise sampled from \(N(0,0.1^2)\)
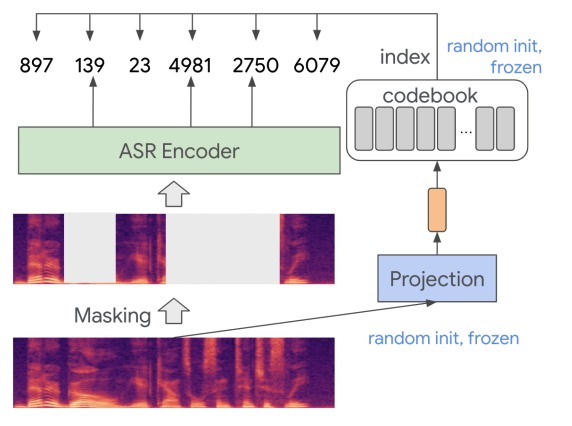
(1) Random-projection Quantizer
Input vector \(x\) (\(d\)-dimensional vector computed from speech signals)
Discrete labels \(y\)
-
\(y=\underset{i}{\operatorname{argmin}}\mid \mid \operatorname{norm}_{l 2}\left(c_i\right)-\operatorname{norm}_{l 2}(A x)\mid \mid\).
- \(A\) : a randomly initialized \(h \times d\) matrix
- \(C=\left\{c_1, \ldots, c_n\right\}\) : a set of randomly initialized \(h\) dim vectors
-
Projection matrix \(A\) use Xavier initialization
-
Codebook \(C\) use standard normal distribution for initialization
(2) Pre-training
Softmax layer on top of the ASR encoder to learn to predict the quantized speech labels
Random-projection quantizer = independent of the ASR encoder
\(\rightarrow\) pre-training is flexible & can work with different architectures of the ASR encoder
Study the effectiveness of the algorithm on both nonstreaming and streaming models
- use Conformer (Gulati et al., 2020) as the building block.
a) NON-streaming models
BERT-style pre-training is designed for the nonstreaming models
- uses both past and future context to learn to predict the quantized labels of the masked speech signals.
b) Streaming models
- Streaming architecture however is less well-studied in the previous SSL work compared to the non-streaming architecture
- Proopose two pre-training algorithms that are compatible with the streaming architecture:
- (a) Streaming pre-train
- (b) Non-Streaming pre-train
(a) Streaming pre-train
-
BERT-RQ does not require learning quantization & focuses only on training the ASR encoder
\(\rightarrow\) largely benefits the streaming models.
-
Pre-training for streaming models follows the same setup as non-streaming models,
but the ASR encoder now learns to predict the quantized labels of the masked part based only on the past context
(b) Non-Streaming pre-train
- neural network architecture like Transformer/Conformer allows switching from non-streaming to streaming behaviors by adding a mask for the future context within the same model, one can also perform pre-training with non-streaming setup for streaming models
(3) Fine-tuning
Focus on end-to-end models with RNN transducers (Graves, 2012)
- decoder uses LSTMs for the prediction network.
- an additional projection layer is added on top of the pre-trained encoder to help it adapt to the downstream ASR task.
Also updates the encoder during the supervised fine-tuning.
##
(4) Understanding the Effectivenss of the Random-projection Quantizer
random projection = dimension reduction for the speech signals
random codebook = approximated discrete representation of the speech data distribution.
2 Questions
- Q1) how good is the resulting quantization quality with this quantizer?
- Q2) how much does the quantization quality affect the effectiveness of the self-supervised learning?
Answer by comparing our quantizer with VQ-VAEs
- VQ-VAEs also provide a discrete representation for the speech signals
- but do so by learning a representation in the latent space that best preserves the speech data.
- Thus, Comparing with VQ-VAE is checking …
- (1) quantization quality of our quantizer
- (2) effect of representation learning for SSL
4. Experiments
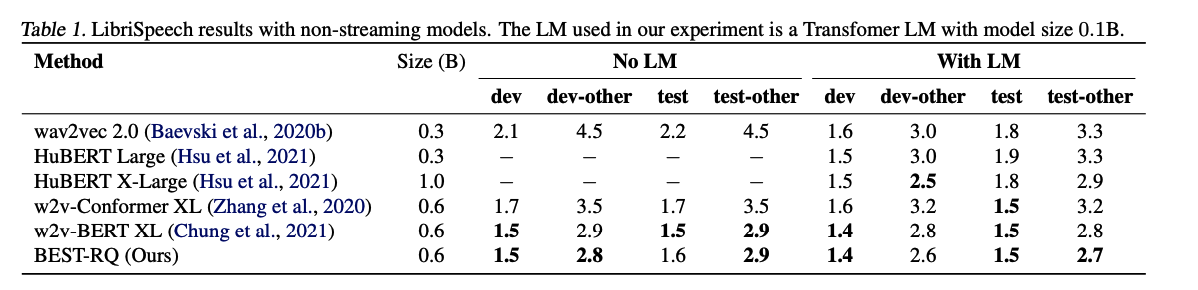
(1) Data: LibriSpeech
a) vs. Non-streaming models
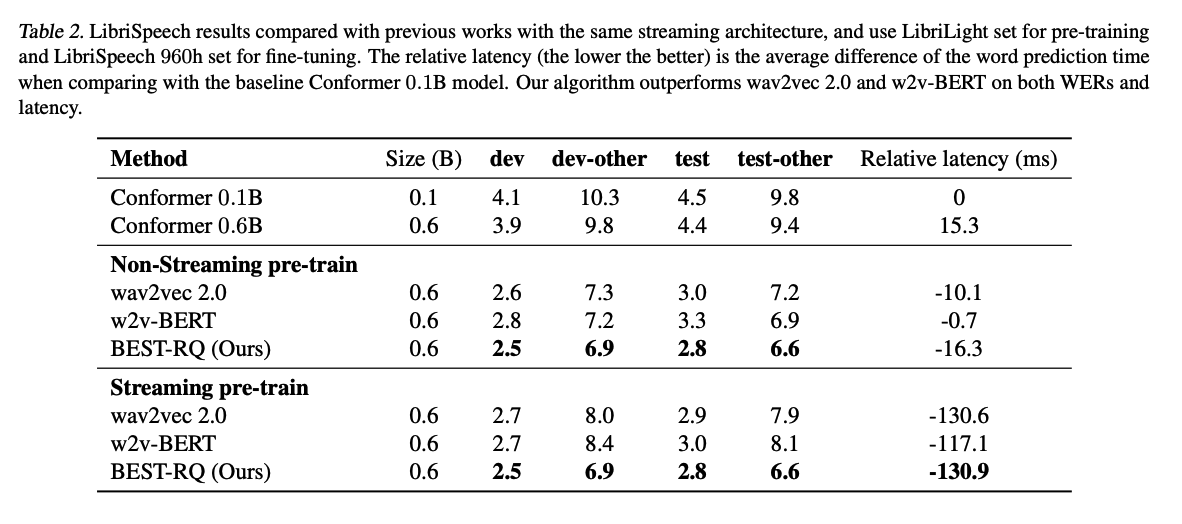
b) vs. Streaming models
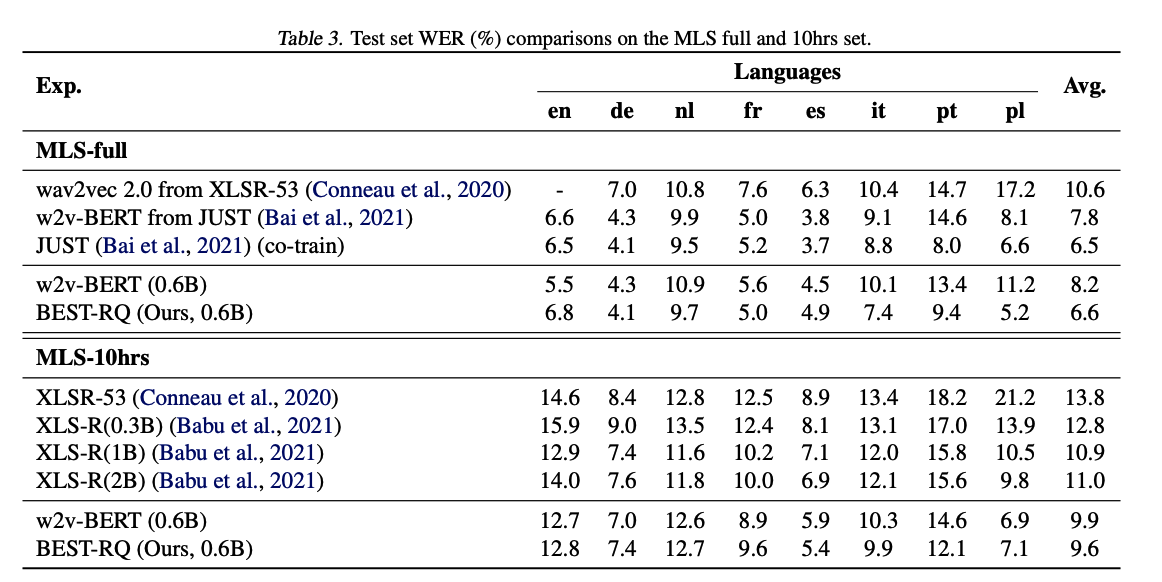
(2) Data: MultiLingual Tasks
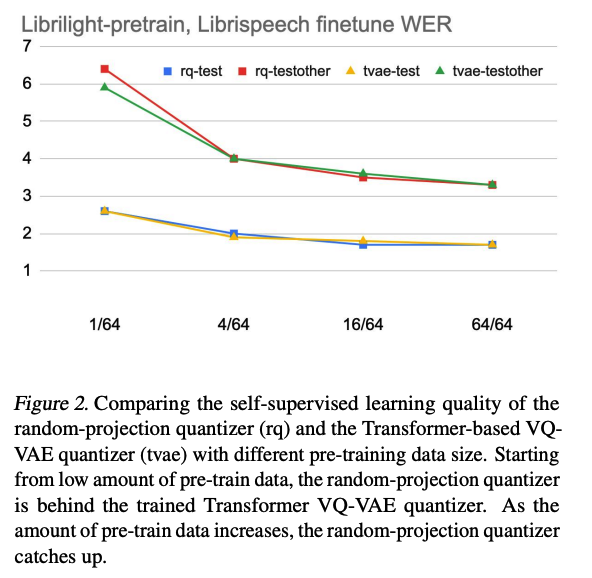
(3) Quantization Quality
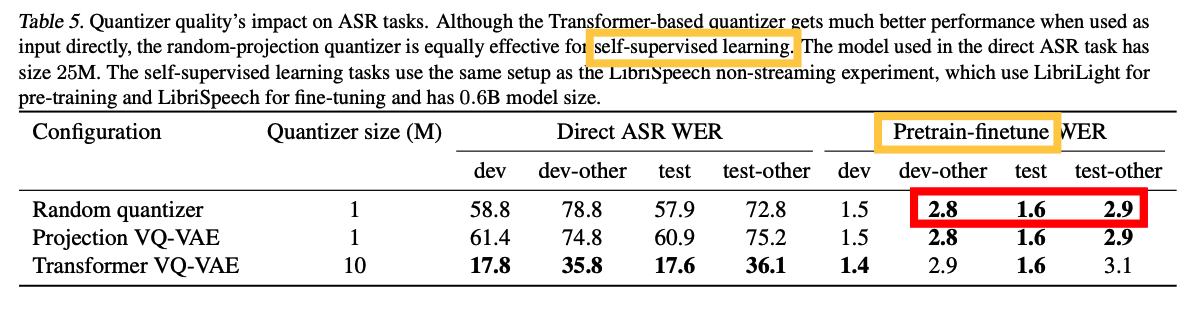
Result: all quantizers lead to similar WERs
\(\rightarrow\) indicates that the quantizer quality does not translate to SSL quality
(4) Effect of Pre-training Data Size