SSAST: Self-Supervised Audio Spectrogram Transformer ( AAAI 2022 )
https://arxiv.org/pdf/2110.09784.pdf
Contents
- Abstract
- SSAST
- AST Model Architecture
- Two modifications to AST for SSL
- Joint Discriminative and Generative Masked Spectogram Patch Modeling
- Experiments
Abstract
Audio Spectrogram Transformer (AST)
- achieves SOTA results on various audio classification benchmarks
- However, Transformer models tend to require more training data compared to CNNs
SSAST: Self-Supervised Audio Spectrogram Transformer
-
leverage SSL using unlabeled data
- pretrain the AST model with …
- joint (1) discriminative and (2) generative masked spectrogram patch modeling (MSPM)
- using unlabeled audio from AudioSet and Librispeech
- first patch-based SSL framework in the audio and speech domain
( Code at https://github.com/YuanGongND/ssast. )
1. Introduction
Critical issue of such pure self-attention based models = require more training data than CNNs
Solution: AST uses cross-modal pretraining with ImageNet data (Deng et al. 2009).
Limitation
- (1) supervised pretraining on ImageNet data is complex and expensive
- (2) validity and transferability of such cross-modal pretraining for a specific audio or speech task are unclear.
Motivation
can easily get web-scale unlabeled audio and speech data from radio or YouTube
\(\rightarrow\) leverages unlabeled data !!
SSAST: Self-Supervised Audio Spectrogram Transformer
novel joint discriminative and generative Masked Spectrogram Patch Modeling (MSPM)
Previous SSL methods
-
wav2vec or autoregressive predictive coding (APC)
-
use an objective that predicts future or masked temporal spectrogram frames
\(\rightarrow\) learn only the temporal structure of the spectrogram.
-
-
proposed MSPM
-
predict a specific frequency band in a specific time range (i.e., a “spectrogram patch”) given the neighboring band and time information,
\(\rightarrow\) learn both the temporal and frequency structure.
-
show that the SSL model can be generalized to both (1) speech and (2) audio tasks.
- pretrain our model using both Librispeech and AudioSet
-
2. SSAST
(1) AST Model Architecture
( similar to original AST architecture to make a fair performance comparison )
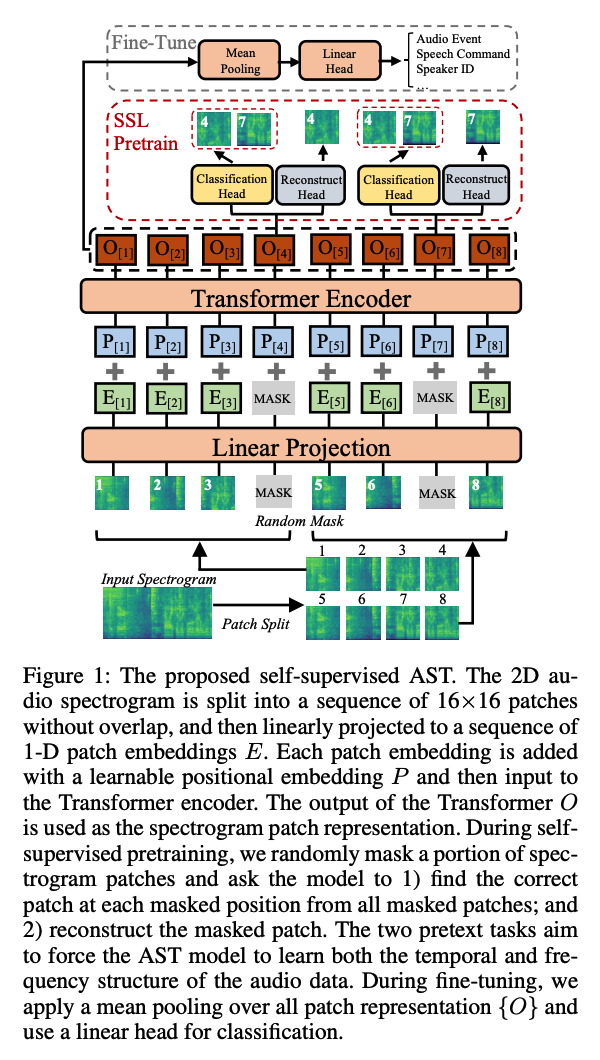
Step 1) Convert to Melspectogram
- Input audio waveform of \(t\) seconds \(\rightarrow\) sequence of 128-dim log Mel filterbank (fbank) features
- omputed with a 25ms Hamming window every 10ms.
- Result : 128×100\(t\) spectrogram ( = input to AST )
Step 2) Patching
- split the spectrogram into a sequence of \(N\) 16×16 patches with an overlap of \(6\) in both time and frequency dimension
- number of pacthes \(N=12\lceil(100 t-16) / 10\rceil\)
Step 3) Flatten ( using a linear projection layer )
- each \(16 \times 16\) patch \(\rightarrow\) \(1 D\) patch embedding of size 768
- also called patch embedding layer
Step 4) Trainable positional embedding
- \(\because\) Transformer does not capture the input order information & and the patch sequence is also not in temporal order
- ( + append a [CLS] token at the beginning of the sequence )
Output of the Transformer encoder = patch representation \(O\).
\(\rightarrow\) ( fine-tuning and inference ) apply a mean pooling over the sequence of patch representation \(\{O\}\) to get the audio clip level representation & use a linear head for classification
(2) Two modifications to AST for SSL
a) Presence of CLS token
(original AST)
- a [CLS ] token is appended to the beginning
- output representation of the [CLS] token is used as the audio clip level representation
(SSAST)
- apply mean pooling over all patch representation \(\{O\}\) as the audio clip level representation
- WHY??
- For SSL, supervision is applied to each individual patch representation, and the mean of all patch representations is a better summary of the audio clip.
b) Overlap
(original AST) spectrogram patches are split with overlap
(SSAST) without overlap during pretraining ( to prevent shortcut )
(3) Joint Discriminative and Generative Masked Spectogram Patch Modeling
- masking strategy
- pretext task
a) Masked Patch Sampling
Details:
-
use a fixed-length audio of 10s
-
convert it to spectrogram of size \(1024 \times 128\)
-
splits the spectrogram into \(512\) \(16\times 16\) patches
-
8 in the frequency dimension
-
64 in the time dimension
-
Mask spectrogram patches rather than the entire time frames during pretraining
\(\rightarrow\) enables to learn both the temporal and frequency structure of the data
Masking hyperparameter : cluster factor \(C\)
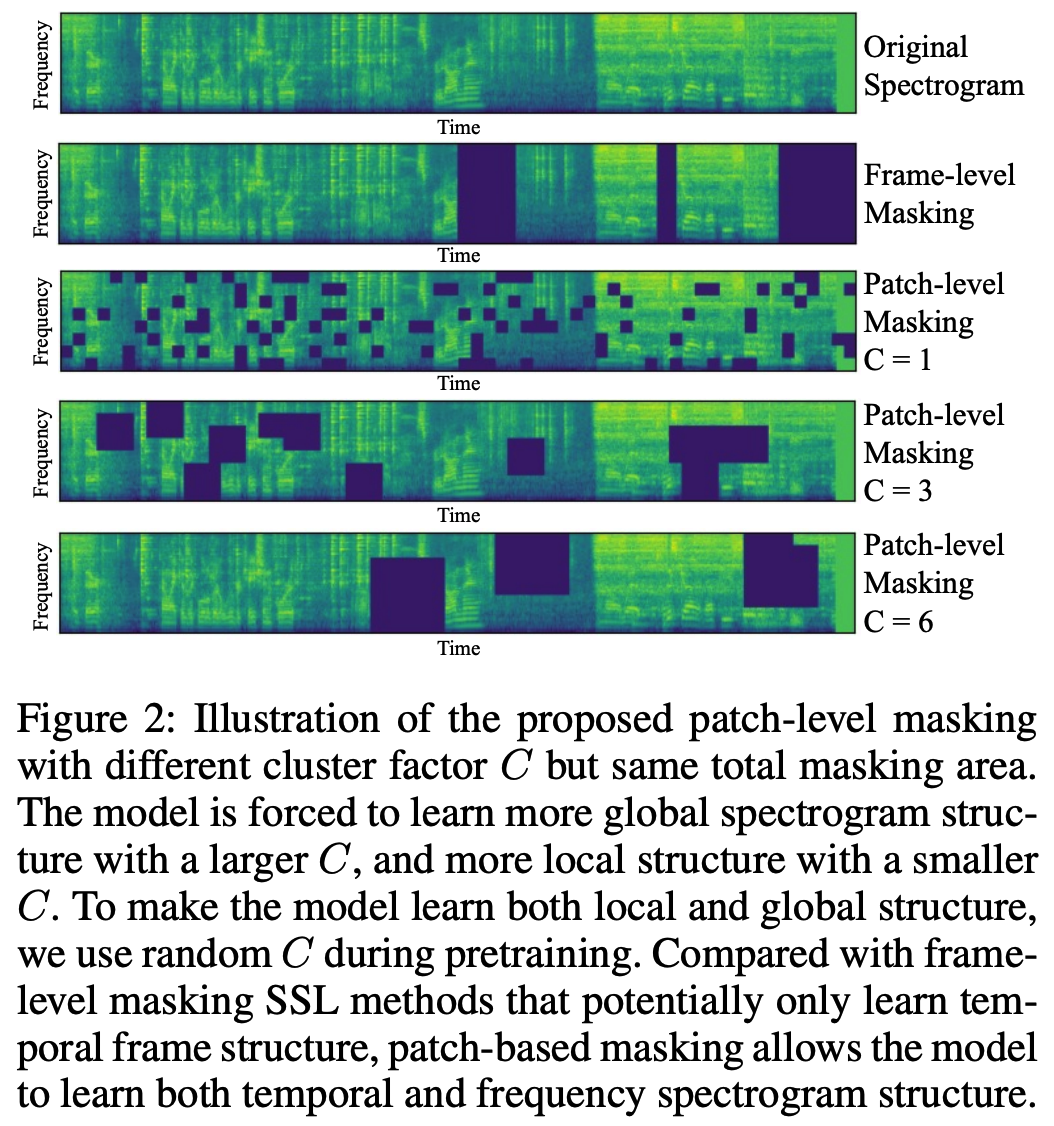
-
to control how masked patches cluster
- How?
- (1) randomly select a patch
- (2) mask the square centered at the patch with a side length of \(C\)
- e.g., if \(C=3\), we mask a cluster of 9 patches that has a total size of \(48 \times 48\).
- The model is forced to learn …
- more global spectrogram structure with a larger \(C\)
- more local structure with a smaller \(C\).
- use random \(C \sim[3,5]\) during pretraining.
b) Joint Discriminative and Generative Masked Spectogram Patch Modeling
Prior pretasks
- discriminative (e.g., wav2vec)
- generative (e.g., APC)
\(\rightarrow\) SSAST: joint discriminative & generative objective for pretraining.

Mask patches : with a learnable mask embedding \(E_{\text {mask }}\)
Classification and Reconstruction heads : two-layer MLPs
Two losses
- \(\mathcal{L}_d\) : InfoNCE ( for the discriminative objective )
- \(\mathcal{L}_g\) : MSE ( for the generative objective )
\(\begin{gathered} \mathcal{L}_d=-\frac{1}{N} \sum_{i=1}^N \log \left(\frac{\exp \left(c_i^T x_i\right)}{\sum_{j=1}^N \exp \left(c_i^T x_j\right)}\right) \\ \mathcal{L}_g=\frac{1}{N} \sum_{i=1}^N\left(r_i-x_i\right)^2 \end{gathered}\).
- where \(N\) is the number of masked patches.
Final Loss function : \(\mathcal{L}=\mathcal{L}_d+\lambda \mathcal{L}_g\)
- set \(\lambda=10\).
3. Experiments
(1) Pretraining Datasets
- AudioSet-2M
- Librisspeech
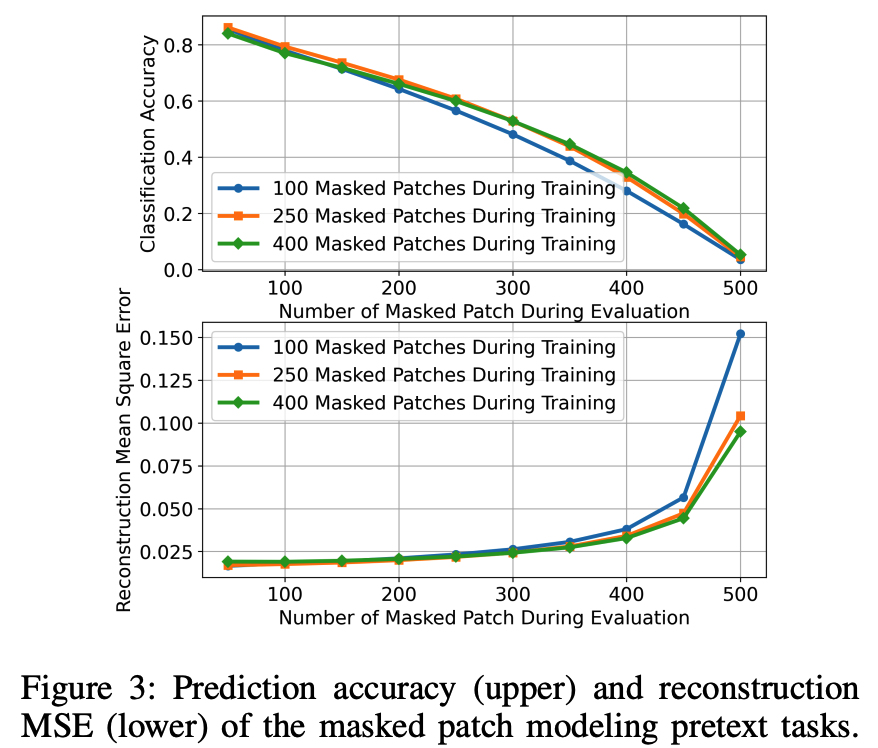
(2) Performance of Pretext Tasks
(3) Downstream Tasks and Datasets
6 commonly used audio and speech benchmarks
- Audio : 3 benchmarks (AudioSet-20K, ESC-50, and Speech Commands V2=KS2)
- Speech : 3 benchmark
- Speech Commands V1: keyword spotting (KS1)
- VoxCeleb 1: speaker identification (SID)
- IEMOCAP : emotion recognition (ER)
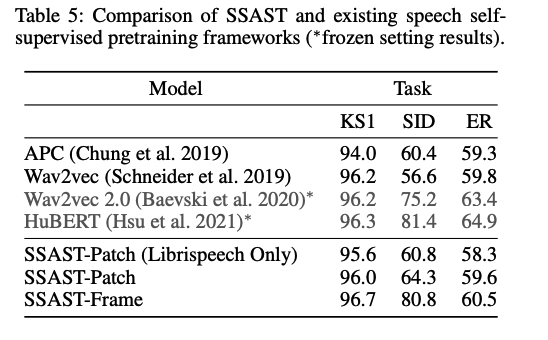
(4) Performance on Downstream Tasks
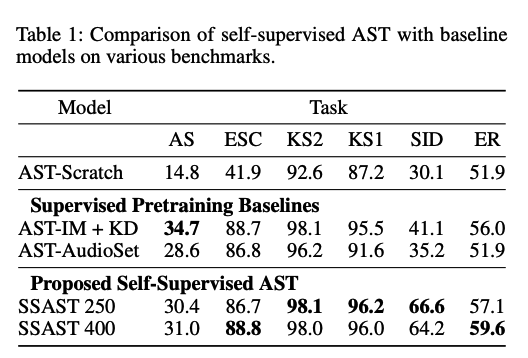
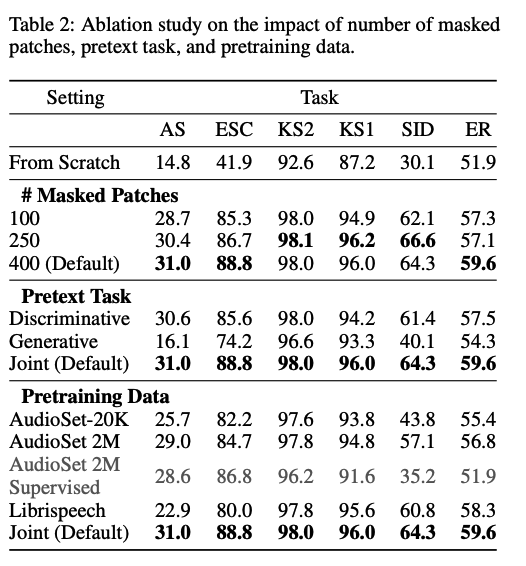
(5) Performance Impact of Pretraining Settings
a) Impact of Number of Patches
b) Impact of Pretext Tasks
c) Impact of Pretraining Data
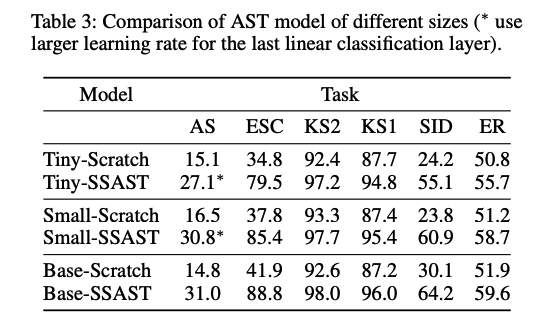
(6) Performance Impact of AST Model Size
Tiny Model (6M parameters)
- encoder has 12 layers with 3 attention heads
- embedding dimension of 192
Small Model (23M parameters)
-
encoder has 12 layers with 6 attention heads
-
embedding dimension of 384.
Base Model (89M parameters) … default model
- encoder has 12 layers with 1 attention heads
- embedding dimension of 768
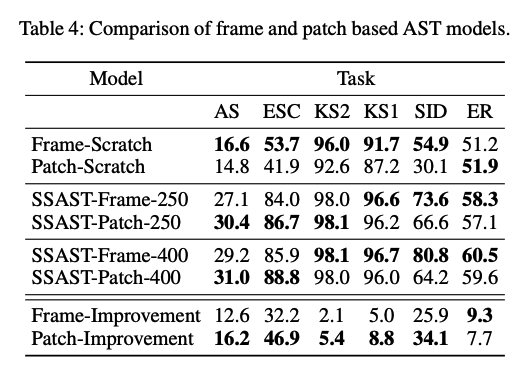
(7) Comparing Patch-based and Frame-based AST
(8) Comparing with Existing Speech SSL Frameworks