MAE-AST: Masked Autoencoding Audio Spectogram Transformer (Interspeech, 2022)
https://www.isca-speech.org/archive/pdfs/interspeech_2022/baade22_interspeech.pdf
Contents
- Abstract
- Introduction and Related Work
- MAE-AST
- Model Architecture
- Mask Sampling
- Joint Discriminative and Generative Pretraining
- Experiments
- SSAST vs. MAE-AST
- Masking Strategies
- Pretext Task Ablation
Abstract
MAE-AST
- improvement over the recent SSAST
- leverage the insight that the SSAST uses a very high masking ratio (75%) during pretraining
- integrate MAE into the SSAST
- DEEP encoder operates on only unmasked input
- SHALLOW decoder operates on encoder outputs and mask tokens
- provide a 3× speedup and 2× memory usage reduction over the vanilla SSAST
1. Introduction and Related Work
Self-Supervised Audio Spectrogram Transformer (SSAST)
-
first patch-based and fully self-attention based pretraining strategies
-
achieved remarkable results for both
- (1) audio event classification
- (2) speech classification
-
limitation : massive computational overhead … \(O(N^2)\)
\(\rightarrow\) MAE : completely discards masked input tokens during the encoding
Propose MAE-AST = (1) MAE + (2) SSAST
Findings :
- (1) MAE-AST pretrains using significantly less time (3×) and memory (2×) than the SSAST
- (2) MAE-AST outperforms the SSAST under a shared encoder depth on several downstream tasks,
- (3) MAE-AST performs well with only a generative objective, while the SSAST sees a significant performance drop
2. MAE-AST (Masked Autoencoding Audio Spectogram Transformer)
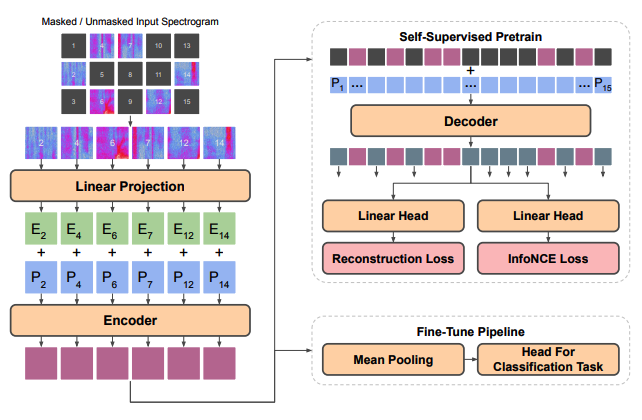
(1) Model Architecture
a) Input Processing
( Identical to the SSAST )
- input : 16khz audio waveform
- convert : into 128-dimensional log Mel filterbank features
- with a frame length of 25 ms
- with a frame shift of 10 ms.
- noramlize : \(N(0,0.5^2)\) …. same as AST and SSAST
- split spectogram into patches
- (patch-based) 16 filter × 16 frame tokens
- (frame-based)128 filter × 2 frame tokens
- masking
b) Positional Embeddings
use fixed sinusoidal positional embeddings for both patch-based and frame-based tokenization
input spectrogram data = only variable-length in time
\(\rightarrow\) use 1D positional embeddings for both tokenization
c) Encoder
( standard ViT architecture )
- flatten the unmasked input patches or frames via a linear projection ( into a 768-dim )
- add sinusoidal positional embeddings to all tokens before inputting into the decoder
d) Decoder
( only used during pretraining & composed of standard transformer encoder blocks )
- input = encoder output & mask tokens
- mask tokens : represented by a shared, learned embedding
e) Settings
-
encoder : 6 layers
-
decoder : 2 layers
-
both the encoder and decoder use : 12 heads and a width of 768.
-
no CLS token
( mean pool the encoder output last hidden states for classification tasks )
( For fair comparison between MAE-like and traditional BERT-like architectures )
Adopt the input pipelining and loss from the SSAST
But 2 minor changes
-
(1) overlapping
-
AST paper = overlap (O)
-
SSAST = overlap (X) … no cheating
-
however, adds overlap back during fine-tuning
( to match the original AST paper via interpolating learned positional embeddings )
-
-
MAE-AST = overlap (X) for both pretraining & finetuning
-
-
(2) positional embedding (PE)
- SSAST = interpolation or trunctation of PE to support variable-length inputs during finetuning
- MAE = no modifications to PE for finetuning
(2) Mask Sampling
2 considerations
- (1) % of masking
- (2) amount of chunking between masked tokens
To little (1) & (2) \(\rightarrow\) too easy task
higher masking ratio \(\rightarrow\) provide significant speedups (for MAE)
8 overall masking and input strategies via combinations of the following factors:
- (1) Patch-Based vs. Frame-Based inputs
- (2) Fully random vs. chunked masking
- (3) Different masking ratios.
(3) Joint Discriminative and Generative Pretraining
SSAST : combining both discriminative (classification) and generative (reconstruction) losses
MAE-AST : adopt this strategy, with small differences:
1-layer vs 2-layer NN for task
- SSAST : the encoder output is fed into 2 separate 2-layer NN
- 1 for reconstruction & 1 for classification
- MAE-AST : single linear layer for each
Loss functions ( identical to SSAST )
- (1) Reconstruction loss = MSE btw the unnormalized output normalized input
- (2) Classification loss = InfoNCE
- obtain negative samples from other masked inputs within the same audio segment
- Final Loss = two losses are summed and balanced by a factor \(\lambda\)
- same \(\lambda=10\) as SSAST.
3. Experirments
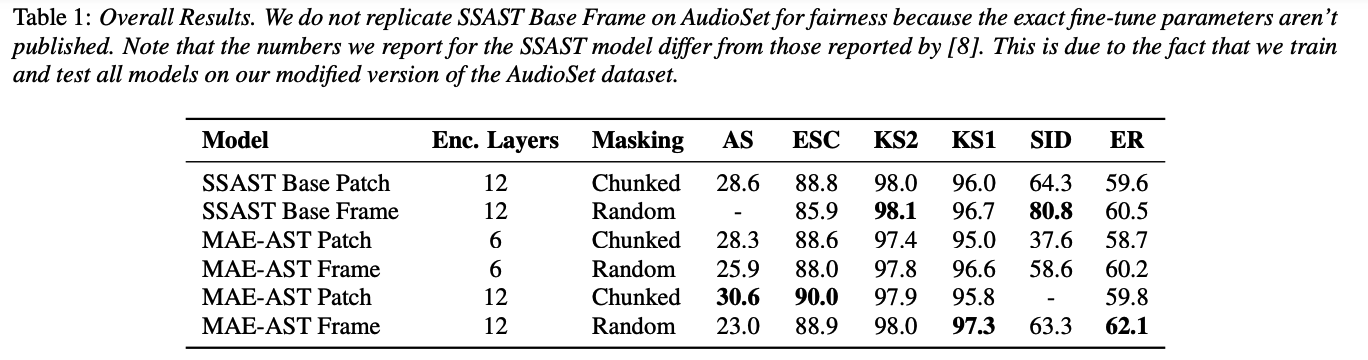
(1) SSAST vs MAE-AST
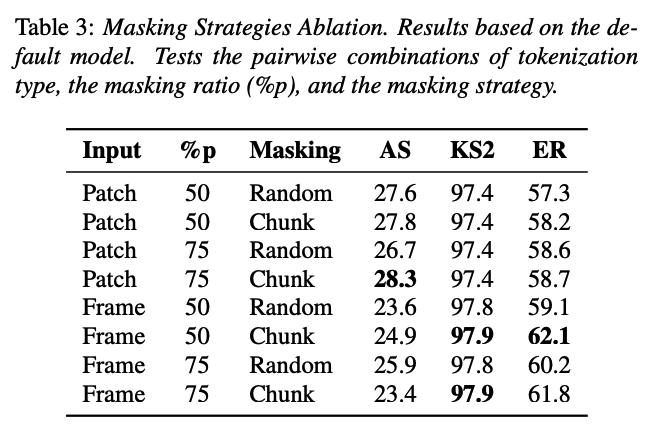
(2) Masking Strategies
(3) Pretext Task Ablation