Siamese Masked Autoencoders (NeurIPS, 2023)
https://arxiv.org/pdf/2305.14344.pdf
Contents
- Abstract
- Related Work
- Method
- Patchify
- masking
- Encoder
- Decoder
- Ablation Studies
Abstract
Siamese Masked Autoencoders (SiamMAE)
- simple extension of MAE for learning visual correspondence from videos
- operates on pairs of randomly sampled video frames & asymmetrically masks them
- Model
- Encoder: these frames are processed independently by an two different encoders
- Decoder: composed of a sequence of cross-attention layers
- Goal: predicting the missing patches in the future frame
- mask ratio:
- past: 0%
- future: 95%
- encourages the network to focus on object motion and learn object-centric representations
1. Related Work
(1) Temporal correspondence
Learning fine-grained correspondence from video frames is an important
- has been studied for decades in the form of optical flow and motion estimation
\(\rightarrow\) these methods rely on costly human-annotated data
Determining object-level correspondence (i.e., visual object tracking)
- tracking-by-matching methods
- utilize deep features learned via SL or SSL on videos
- SSL: usually use CL method
- Predictive learning: by predicting the target colors for gray-scale input frame by observing a colorful reference frame. ( however, has trailed behind CL methods )
This paper: show that predictive learning based methods can be used for learning fine-grained and object-level correspondence!
2. Method
Goal: devlop SSL for learning correspondence
- study a simple extension of MAE to video dadta
(1) Patchify
Input: video clip with \(L\) frames
Sample: randomly sample 2 frames \(f_1\) and \(f_2\).
- distance between \(f_1\) & \(f_2\) : determined by selecting a random value from the predetermined range of potential frame gaps.
Patchify each frame
- by converting it into a sequence of non-overlapping \(N \times N\) patches.
Position embeddings
- added to the linear projection of the patches
- (do not use any temporal position embeddings)
[CLS] token is added
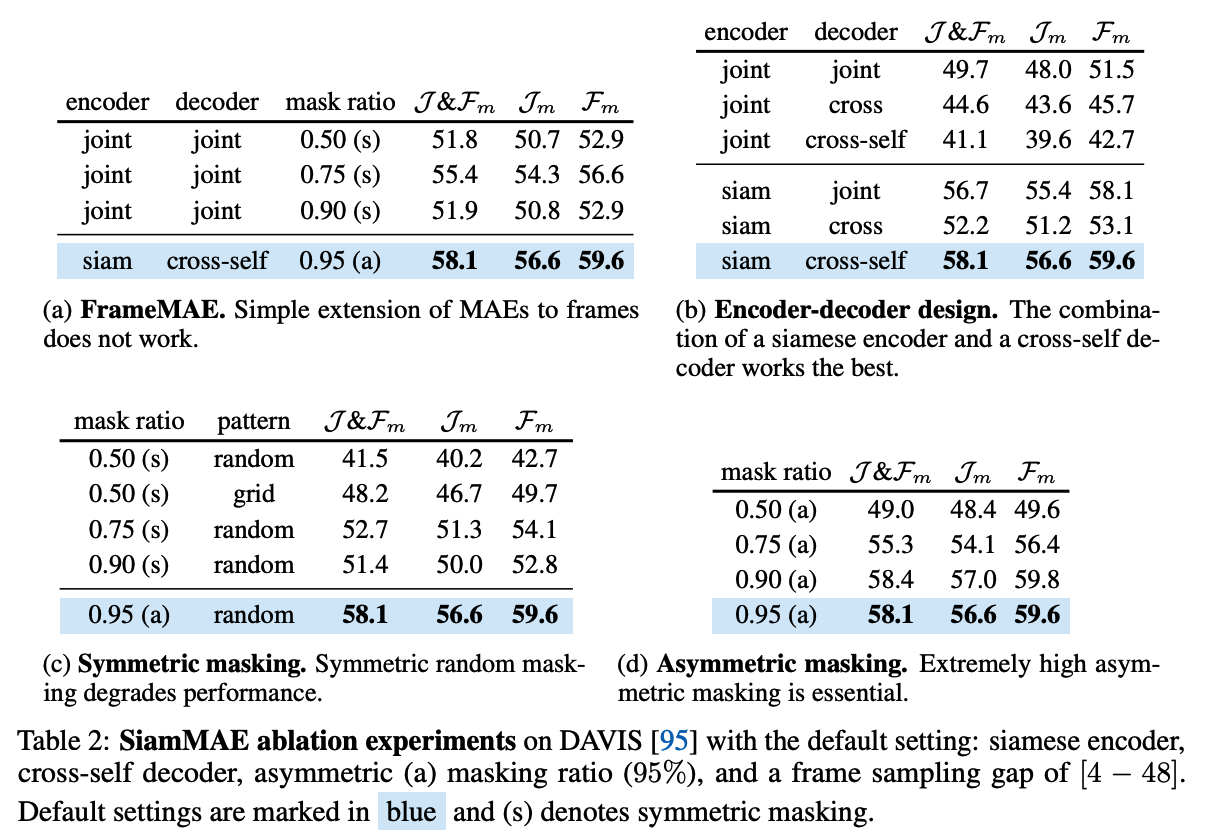
(2) Masking
In general …
-
Image: 75% & Video: 90%
-
In both images and videos, the masking strategy is symmetric
( = all frames have a similar masking ratio )
\(\rightarrow\) this deliberate design choice prevents the network from leveraging and learning temporal correspondence, leading to sub-optimal performance on correspondence learning benchmarks!
Assymetric masking
Posit that asymmetric masking can create a challenging SSL task & encourage the network to learn temporal correlations.
Details
- \(f_1\) : 0%
- \(f_2\) : 95%
By providing the entire past frame as input, the network only needs to propagate the patches from the past frames to their appropriate locations in the future frame.
\(\rightarrow\) encourages the network to model object motion and focus on object boundaries
Large temporal gap
To further increase the difficulty of the task!
\(\rightarrow\) Sample the two frames with a large temporal gap
(3) Encoder
2 different encoder configurations
3-1) Joint Encoder
-
Natural extension of image MAEs to a pair of frames.
-
Unmasked patches from the two frames are CONCATENATED
( & then processed by a standard ViT encoder )
3-2) Siamese Encoder
-
Weight-sharing neural networks
- require some information bottleneck to prevent the network from learning trivial solutions
- ex) Color channel dropout: force the network to avoid relying on colors for matching
- require some information bottleneck to prevent the network from learning trivial solutions
-
This paper uses siamese encoders to process the two frames INDEPENDENTLY (No Weight Sharing)
& asymmetric masking serves as an information bottleneck
(4) Decoder
-
full tokens
- (1) tokens 1: output from the encoder (+ linear layer)
- (2) tokens 2: [MASK] tokens
( + with position embeddings )
-
3 different decoder configurations
4-1) Joint decoder
- Applies vanilla Transformer blocks on the concatenation of full set of tokens from both frames
- Problem: substantial increase in GPU memory requirement
4-2) Cross-self decoder
- Similar to the original encoder-decoder design of the Transformer
- Each decoder block consists of ..
- (1) cross-attention layer
- (2) self-attention layer
- Step 1) Tokens from \(f_2\) attend to the tokens from \(f_1\) via the cross-attention layer
- K&V: from \(f_1\)
- Q: from \(f_2\)
- Step 2) Attend to each other via the self-attention layer
4-3) Cross decoder
- decoder blocks with only cross-attention layers
Output sequence of decoder is used to predict the NORMALIZED pixel values ( & use \(l_2\) loss )
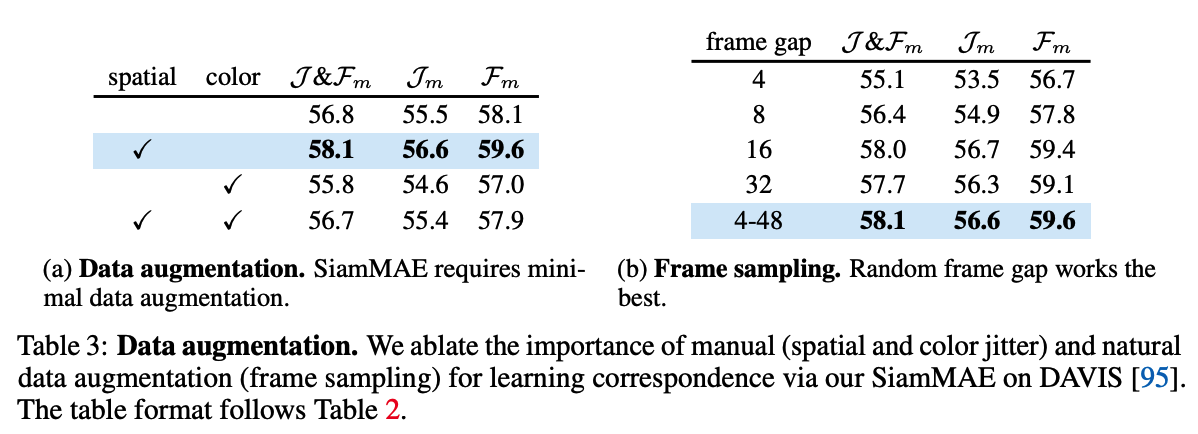
3. Ablation studies