( 참고 : 패스트 캠퍼스 , 한번에 끝내는 컴퓨터비전 초격차 패키지 )
MobileNet & ShuffleNet
[1] MobileNet
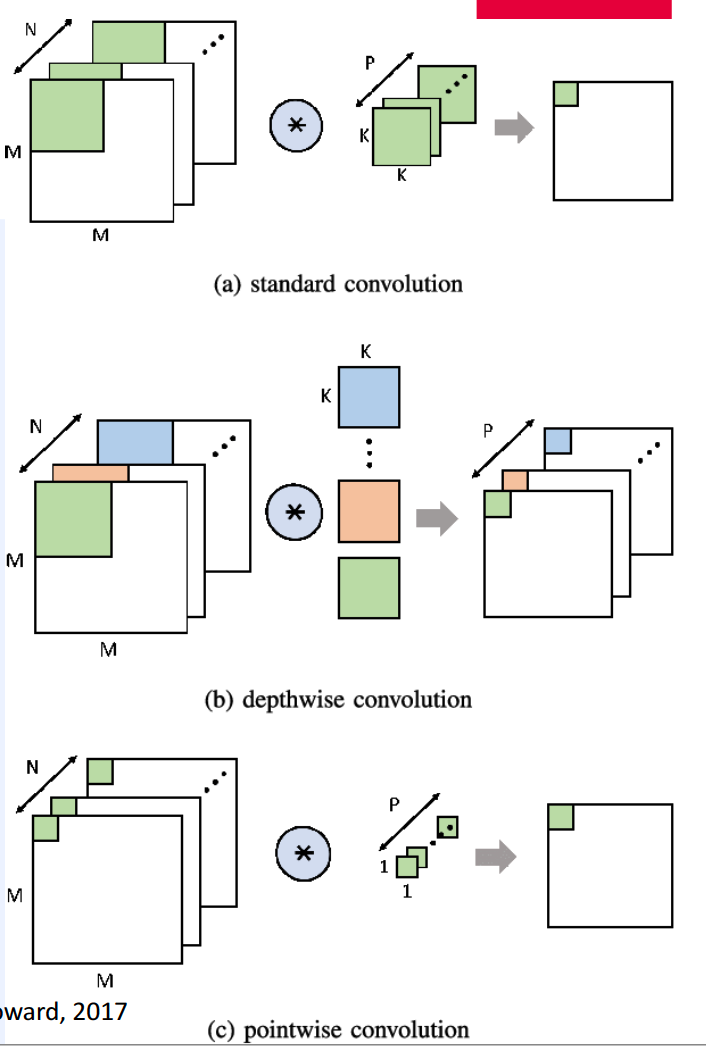
(1) Depthwise-Separable Convolution
decouples “channel-wise” feature extractor & “spatial” feature extractor
- depthwise conv : channel-wise weights
- separable conv : 1x1 conv
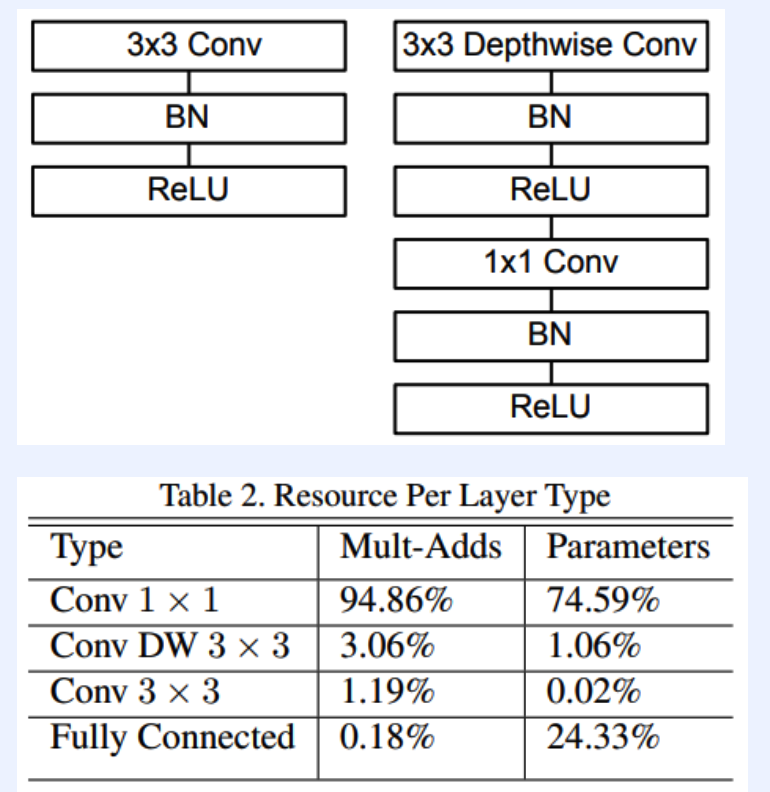
(2) Computational Cost
Standard convolution
- computational cost : \(C_{o} C_{i} H_{o} W_{o} K_{h} K_{w}\)
Depthwise-Separable Convolution
- computational cost : \(C_{i} H_{o} W_{o} K_{h} K_{w}+C_{i} C_{o} H_{o} W_{o}\)
Computational Gain :
- \(\frac{\operatorname{cost}_{d w}}{\operatorname{cost}_{f u l l}}=\frac{1}{C_{i}}+\frac{1}{K_{h} K_{w}}\).
(3) Code
mobilenet_v2 = models.mobilenet_v2()
mobilenet_v3_large = models.mobilenet_v3_large()
mobilenet_v3_small = models.mobilenet_v3_small()
[2] ShuffleNet
As shown above, 1x1 conv takes most of computation
\(\rightarrow\) how to minimize this overhead?
(1) Previous works : Grouped Convolution
“G” grouped convolution = “G” seperable convolutions
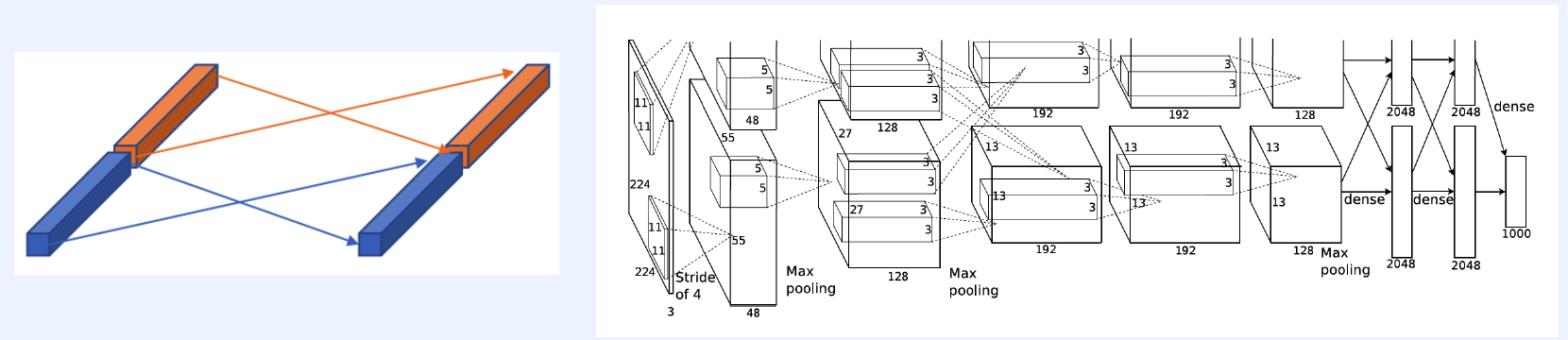
What if we use this with depth-wise convolution in MobileNet?
\(\rightarrow\) no information exchange between channels!
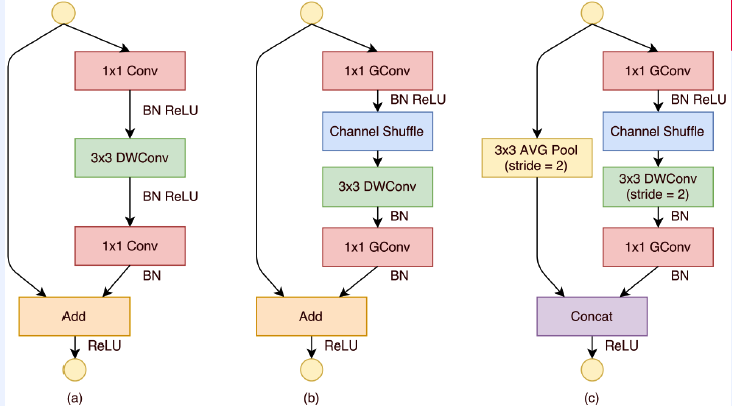
(2) ShuffleNet
let’s shuffle information among channels!
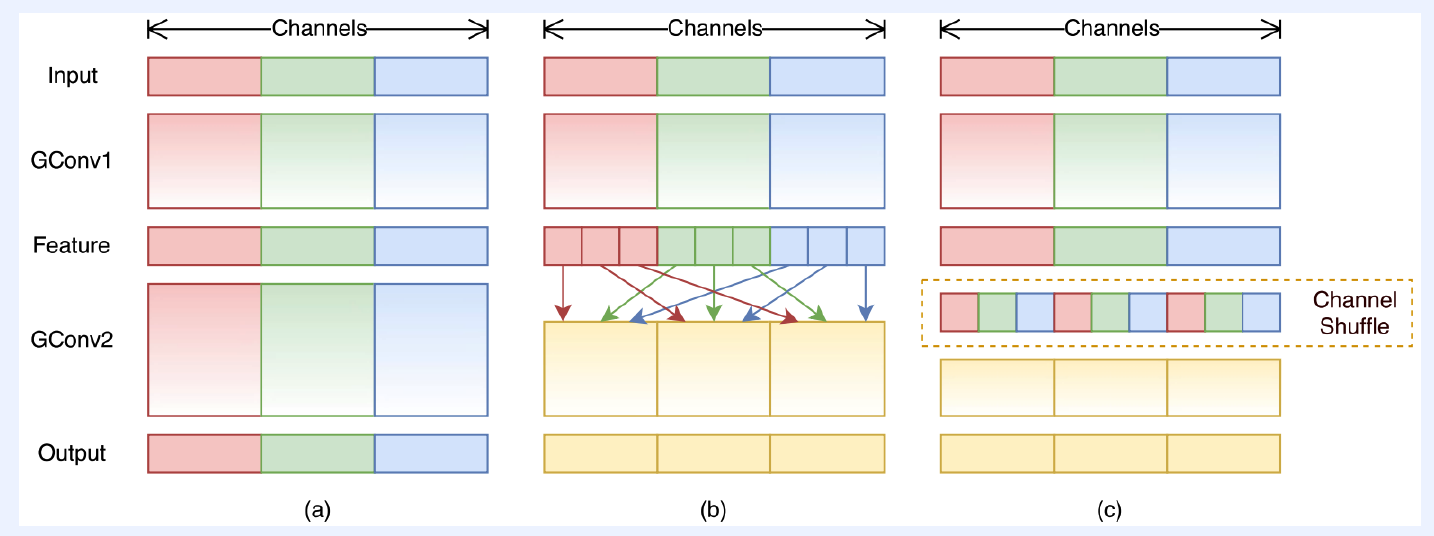
Architecture
- replace 1x1 conv to group conv + shuffle
- no ReLU after depth-wise conv
- replace element-wise addition to concatenation