
( 참고 : 패스트 캠퍼스 , 한번에 끝내는 컴퓨터비전 초격차 패키지 )
04.Object Detection
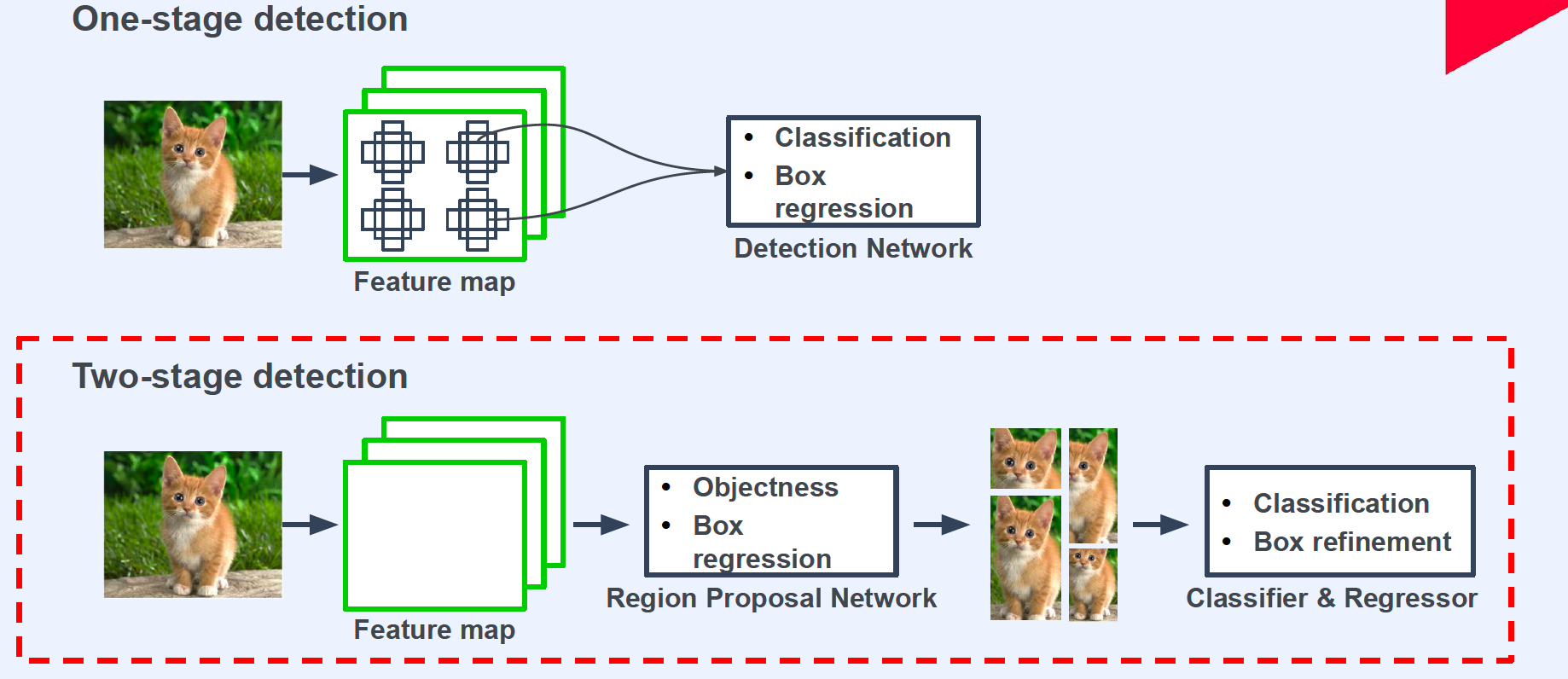
0. Two stage detection
( RCNN family )
1. Import Packages & Dataset
import os
import numpy as np
import pandas as pd
import torch
import cv2
import matplotlib.pyplot as plt
from utils import CLASS_NAME_TO_ID, visualize
CLASS_NAME_TO_ID
{'Bus': 0, 'Truck': 1}
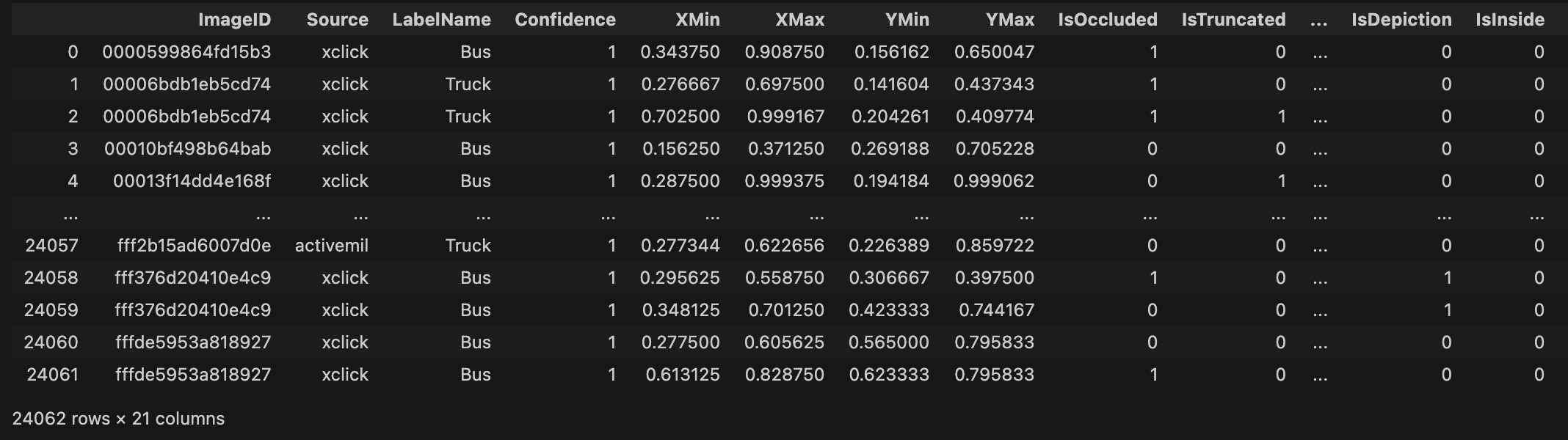
format of meta dataset :
data_dir = "../DATASET/Detection/"
data_df = pd.read_csv(os.path.join(data_dir, 'df.csv'))
data_df
(1) Images
Import image files ( .jpg )
image_files = [fn for fn in os.listdir("../DATASET/Detection/images/") if fn.endswith("jpg")]
Read example image file
index = 0
image_file = image_files[index]
image_path = os.path.join("../DATASET/Detection/images/", image_file)
img_ex = cv2.imread(image_path)
img_ex = cv2.cvtColor(img_ex, cv2.COLOR_BGR2RGB)
plt.imshow(image)

(2) Boxes
Read coordinate values (boxes) of certain image
image_id = image_file.split('.')[0]
meta_data = data_df[data_df['ImageID'] == image_id]
# (1) Label
cate_names = meta_data["LabelName"].values
# (2) Boxes
bboxes = meta_data[["XMin", "XMax", "YMin", "YMax"]].values
print(cate_names)
print(bboxes) # normalized values ( 0 ~ 1 )
array(['Truck'], dtype=object)
array([[0.259375, 0.813125, 0.549167, 0.799167]])
Unnormalize boxes
- Before )
["XMin", "XMax", "YMin", "YMax"](normalized) - After)
["X_center", "Y_center", "Width(X len)", "Height(Y len)"](unnormalized)
img_H, img_W, _ = image.shape
# bus, truck -> 0, 1
class_ids = [CLASS_NAME_TO_ID[cate_name] for cate_name in cate_names]
unnorm_bboxes = bboxes.copy()
unnorm_bboxes[:, [1,2]] = unnorm_bboxes[:, [2,1]]
unnorm_bboxes[:, 2:4] -= unnorm_bboxes[:, 0:2]
unnorm_bboxes[:, 0:2] += (unnorm_bboxes[:, 2:4] / 2)
unnorm_bboxes[:, [0,2]] *= img_W
unnorm_bboxes[:, [1,3]] *= img_H
Visualize image & boxes
canvas = visualize(image, unnorm_bboxes, class_ids)
plt.figure(figsize=(6,6))
plt.imshow(canvas)
plt.show()

2. Build Dataset
class Detection_dataset():
def __init__(self, data_dir, phase, transformer=None):
self.data_dir = data_dir # train / val
self.phase = phase
self.data_df = pd.read_csv(os.path.join(self.data_dir, 'df.csv'))
self.image_files = [fn for fn in os.listdir(os.path.join(self.data_dir, phase)) if fn.endswith("jpg")]
self.transformer = transformer
def __len__(self):
return len(self.image_files)
def __getitem__(self, index):
# (1) Read image & labels (= box & class)
filename, image = self.get_image(index)
bboxes, class_ids = self.get_label(filename) # "XMin", "YMin", "XMax", "YMax"
img_H, img_W, _ = image.shape
# (2) Transform Images
if self.transformer:
image = self.transformer(image)
_, img_H, img_W = image.shape # need to redefine, since RESIZE!
# (3) Unnormalize images
bboxes[:, [0,2]] *= img_W
bboxes[:, [1,3]] *= img_H
# (4) Convert to tensor & make as dictionary
target = {}
target["boxes"] = torch.Tensor(bboxes).float()
target["labels"] = torch.Tensor(class_ids).long()
return image, target, filename
def get_image(self, index):
filename = self.image_files[index]
image_path = os.path.join(self.data_dir, self.phase, filename)
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
return filename, image
def get_label(self, filename):
image_id = filename.split('.')[0]
meta_data = self.data_df[self.data_df['ImageID'] == image_id]
cate_names = meta_data["LabelName"].values
class_ids = np.array([CLASS_NAME_TO_ID[cate_name] for cate_name in cate_names])
bboxes = meta_data[["XMin", "XMax", "YMin", "YMax"]].values
bboxes[:, [1,2]] = bboxes[:, [2,1]]
return bboxes, class_ids
data_dir = "../DATASET/Detection/"
train_dset = Detection_dataset(data_dir=data_dir, phase="train", transformer=None)
Check one data from training dataset
- There are 2 targets
- (1) boxes ( 4 values )
- (2) class labels ( 1 value )
index = 0
image, target, filename = dataset[index]
print(image.shape)
print(target)
print(filename)
(192, 256, 3)
{'boxes': tensor([[ 66.4000, 105.4401, 208.1600, 153.4401]]), 'labels': tensor([1])}
63908fdf1f3d13fe.jpg
Check another data from training dataset
- there can be 2 objects in one image!!
index = 30
image, target, filename = dataset[index]
print(image.shape)
print(target)
print(filename)
(156, 256, 3)
{'boxes': tensor([[ 67.8400, 39.3210, 242.4000, 142.3580],
[242.0800, 92.6049, 255.8400, 112.0247]]), 'labels': tensor([0, 0])}
b58e42cf02564028.jpg
Format of boxes (in target)
- “XMin”, “YMin”, “XMax”, “YMax”
But to visualize, transform into
- “X_center”, “Y_center”, “Width(X len)”, “Height(Y len)”
# "XMin", "YMin", "XMax", "YMax"
boxes = target['boxes'].numpy()
class_ids = target['labels'].numpy()
n_obj = boxes.shape[0]
bboxes = np.zeros(shape=(n_obj, 4), dtype=np.float32)
bboxes[:, 0:2] = (boxes[:, 0:2] + boxes[:, 2:4]) / 2
bboxes[:, 2:4] = boxes[:, 2:4] - boxes[:, 0:2]
# "X_center", "Y_center", "Width(X len)", "Height(Y len)"
canvas = visualize(image, bboxes, class_ids)
plt.figure(figsize=(6,6))
plt.imshow(canvas)
plt.show()

3. Build Dataloader
def build_dataloader(data_dir, batch_size=4, image_size=448):
# (1) transform ( tensor -> resize -> normalize )
transformer = transforms.Compose([
transforms.ToTensor(),
transforms.Resize(size=(image_size, image_size)),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# (2) train & valid dataloader
dataloaders = {}
train_dataset = Detection_dataset(data_dir=data_dir, phase="train", transformer=transformer)
val_dataset = Detection_dataset(data_dir=data_dir, phase="val", transformer=transformer)
dataloaders["train"] = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn)
dataloaders["val"] = DataLoader(val_dataset, batch_size=1, shuffle=False, collate_fn=collate_fn)
return dataloaders
data_dir = "../DATASET/Detection/"
dloaders = build_dataloader(data_dir, batch_size=4, image_size=448)
for phase in ["train", "val"]:
for index, batch in enumerate(dloaders[phase]):
# 3 values in one batch!
## -- 1) image
## -- 2) target -> (1) box & (2) label
## -- 3) filename
images = batch[0]
targets = batch[1]
filenames = batch[2]
break
targets # "XMin", "YMin", "XMax", "YMax"
[{'boxes': tensor([[261.5200, 151.9468, 431.7600, 338.9868],
[ 0.0000, 157.1732, 57.1200, 304.6400],
[ 54.8800, 0.0000, 245.8400, 337.8668]]),
'labels': tensor([1, 1, 1])}]
4. Faster R-CNN
( use pre-trained model )
from torchvision import models
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
models.detection.fasterrcnn_resnet50_fpnmodels.detection.faster_rcnn.FastRCNNPredictor
def build_model(num_classes, pretrain=True):
model = models.detection.fasterrcnn_resnet50_fpn(pretrained = pretrain)
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
return model
Need to customize the “head”, since the number of otuput class is different!
NUM_CLASSES = 2
model = build_model(num_classes = NUM_CLASSES)
5. Model Output
Training mode : needs 2 input
images&targets
Test mode : need 1 input
images
phase = 'train'
model.train()
for index, batch in enumerate(dloaders[phase]):
images = batch[0]
targets = batch[1]
filenames = batch[2]
images = list(image for image in images)
targets = [{k: v for k, v in t.items()} for t in targets] # into list of dictionaries
loss = model(images, targets)
break
print(loss)
#--------------------------------
# (LOSS related to STAGE 2)
#---- (1) classification loss ( label )
#---- (2) regression loss ( box )
#--------------------------------
# (LOSS related to STAGE 1)
#---- (3) objectness loss ( 0 ~ 1 )
#---- (4) RPN box regression loss
{'loss_classifier': tensor(2.2535, grad_fn=<NllLossBackward>),
'loss_box_reg': tensor(0.0531, grad_fn=<DivBackward0>),
'loss_objectness': tensor(0.2732, grad_fn=<BinaryCrossEntropyWithLogitsBackward>),
'loss_rpn_box_reg': tensor(0.0143, grad_fn=<DivBackward0>)}
6. Training Code
from collections import defaultdict
def train_one_epoch(dataloaders, model, optimizer, device):
# since there are many kinds of loss...save is as DICTIONARY
train_loss = defaultdict(float)
val_loss = defaultdict(float)
model.train()
for phase in ["train", "val"]:
for index, batch in enumerate(dataloaders[phase]):
images = batch[0]
targets = batch[1]
filenames = batch[2]
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
with torch.set_grad_enabled(phase == "train"):
loss = model(images, targets)
total_loss = sum(each_loss for each_loss in loss.values())
#----------------------------------------------------------------#
# Back Propagation (O)
if phase == "train":
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
if (index > 0) and (index % VERBOSE_FREQ) == 0:
text = f"{index}/{len(dataloaders[phase])} - "
for k, v in loss.items():
text += f"{k}: {v.item():.4f} "
print(text)
for k, v in loss.items():
train_loss[k] += v.item()
train_loss["total_loss"] += total_loss.item()
#----------------------------------------------------------------#
# Back Propagation (X)
else:
for k, v in loss.items():
val_loss[k] += v.item()
val_loss["total_loss"] += total_loss.item()
for k in train_loss.keys():
train_loss[k] /= len(dataloaders["train"])
val_loss[k] /= len(dataloaders["val"])
return train_loss, val_loss
7. Train Models
Hyperparameters
NUM_CLASSES = 2
IMAGE_SIZE = 448
BATCH_SIZE = 6
NUM_EPOCHS = 30
VERBOSE_FREQ = 200
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
Build models ( + dataloaders, optimizer )
dataloaders = build_dataloader(data_dir=data_dir, batch_size=BATCH_SIZE, image_size=IMAGE_SIZE)
model = build_model(num_classes=NUM_CLASSES)
model = model.to(DEVICE)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
train_losses = []
val_losses = []
for epoch in range(NUM_EPOCHS):
losses = train_one_epoch(dataloaders, model, optimizer, DEVICE)
train_losses.append(losses[0])
val_losses.append(losses[1])
print(f"epoch:{epoch+1}/{num_epochs} - Train Loss: {train_loss['total_loss']:.4f}, Val Loss: {val_loss['total_loss']:.4f}")
if (epoch+1) % 10 == 0:
save_model(model.state_dict(), f'model_{epoch+1}.pth')
8. Confidence threshold & NMS (Non-maximum suppression)
model = load_model(ckpt_path='./trained_model/model_30.pth',
num_classes=NUM_CLASSES, device=DEVICE)
Confidence threshold & NMS are post-processes, after the model output!
from torchvision.ops import nms
def postprocess(prediction, conf_thres=0.2, IoU_threshold=0.1):
# 3 outputs ( box / labels / )
pred_box = prediction["boxes"].cpu().detach().numpy()
pred_label = prediction["labels"].cpu().detach().numpy()
pred_conf = prediction['scores'].cpu().detach().numpy()
# filtering 1 : CONFIDENCE THRESHOLD
valid_index = pred_conf > conf_thres
pred_box = pred_box[valid_index]
pred_label = pred_label[valid_index]
pred_conf = pred_conf[valid_index]
# filtering 2 : NMS
valid_index = nms(torch.tensor(pred_box.astype(np.float32)), torch.tensor(pred_conf), IoU_threshold)
pred_box = pred_box[valid_index.numpy()]
pred_conf = pred_conf[valid_index.numpy()]
pred_label = pred_label[valid_index.numpy()]
return np.concatenate((pred_box, pred_conf[:, np.newaxis], pred_label[:, np.newaxis]), axis=1)
9. Validation Code
from torchvision.utils import make_grid
pred_images = []
pred_labels =[]
for index, (images, _, filenames) in enumerate(dataloaders["val"]):
images = list(image.to(DEVICE) for image in images)
filename = filenames[0]
image = make_grid(images[0].cpu().detach(), normalize = True).permute(1,2,0).numpy()
image = (image * 255).astype(np.uint8)
# need only one input in validation!
# prediction contains..
# -- 1) box
# -- 2) label
# -- 3) confidence score
with torch.no_grad():
prediction = model(images)
prediction = postprocess(prediction[0])
prediction[:, 2].clip(min=0, max=image.shape[1]) # H >= 0
prediction[:, 3].clip(min=0, max=image.shape[0]) # W >= 0
#------------------------------------------------------#
# 5 prediction outputs
#---( X_center, Y_center, W, H, class )
xc = (prediction[:, 0] + prediction[:, 2])/2
yc = (prediction[:, 1] + prediction[:, 3])/2
w = prediction[:, 2] - prediction[:, 0]
h = prediction[:, 3] - prediction[:, 1]
cls_id = prediction[:, 5]
prediction_yolo = np.stack([xc,yc, w,h, cls_id], axis=1)
#------------------------------------------------------#
pred_images.append(image)
pred_labels.append(prediction_yolo)
break
10. Evaluation metric with pycocotools
(1) Import pycocotools
import json
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
(2) Read Annotation File
annFile = "../DATASET/Detection/val.json"
with open(annFile, mode='r') as f:
json_data = json.load(f)
imageToid = json_data["imageToid"]
cocoGt=COCO(annFile)
json_data
{'images': [{'file_name': 'e4527471d9fb72a6.jpg',
'height': 448,
'width': 448,
'id': 0},
{'file_name': 'e45378fc7d0fcf38.jpg', 'height': 448, 'width': 448, 'id': 1},
{'file_name': 'e4547c0f11a25f58.jpg', 'height': 448, 'width': 448, 'id': 2},
{'file_name': 'e45593017939235a.jpg', 'height': 448, 'width': 448, 'id': 3},
{'file_name': 'e45857361b6172e6.jpg', 'height': 448, 'width': 448, 'id': 4},
....
def XminYminXmaxYmax_to_XminYminWH(box):
Xmin = box[:, 0]
Ymin = box[:, 1]
W = box[:, 2] - box[:, 0]
H = box[:, 3] - box[:, 1]
return np.stack((Xmin, Ymin, W, H), axis=1)
(3) Save predicted results
COCO_anno = []
# prediction of validation dataset
for index, (images, _, filenames) in enumerate(dataloaders["val"]):
images = list(image.to(DEVICE) for image in images)
filename = filenames[0]
image = make_grid(images[0].cpu().detach(),
normalize=True).permute(1,2,0).numpy()
image = (image * 255).astype(np.uint8)
with torch.no_grad():
prediction = model(images)
prediction = postprocess(prediction[0])
# 3rd : X_max ( <= W )
# 4th : Y_max ( <= H )
prediction[:, 2].clip(min=0, max=image.shape[1])
prediction[:, 3].clip(min=0, max=image.shape[0])
box_xywh = XminYminXmaxYmax_to_XminYminWH(prediction[:, 0:4])
# 5th : confidence score
# 6th : classification result
score = prediction[:, 4][:, np.newaxis]
cls_id = prediction[:, 5][:, np.newaxis]
img_id = np.array([imageToid[filename], ] * len(cls_id))[:, np.newaxis]
COCO_anno.append(np.concatenate((img_id, box_xywh, score, cls_id), axis=1))
if index % 50 == 0:
print(f"{index}/{len(dataloaders['val'])} Done.")
COCO_anno = np.concatenate(COCO_anno, axis=0)
(4) Load predicted results
cocoDt = cocoGt.loadRes(COCO_anno)
(5) Average Precision, Average Recall
annType = "bbox"
cocoEval = COCOeval(cocoGt,cocoDt,annType)
cocoEval.evaluate()
cocoEval.accumulate()
cocoEval.summarize()
eval_stats = cocoEval.stats
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.47s).
Accumulating evaluation results...
DONE (t=0.11s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.204
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.313
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.234
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.011
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.094
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.274
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.215
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.252
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.252
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.024
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.151
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.317