
[Paper Review] 13. A Style-Based Generator Architecture for Generative Adversarial Networks
Contents
- Abstract
- Introduction
- Style-based Generator
- Properties of Style-based Generator
- Style Mixing
- Stochastic Variation
- Disentanglement studies
0. Abstract
New architecture of GAN
- a) unsupervised separation of high-level attributes
- ex) pose, identity of face..
- b) stochastic variation in the generated images
- ex) freckles, hairs ….
- c) enables intuitive, scale-specific control
1. Introduction
Problems of \(G\)
- operate as BLACK-BOX models
- properties of the latent space are poorly understood
Motivated by style-transfer…
\(\rightarrow\) redesign “\(G\) architecture” in a way that exposes novel ways to control image synthesis process
Our \(G\)…
-
embeds \(z\) into intermediate latent space ( = \(g(z)\) )
-
\(g(z)\) is free from restriction
\(\rightarrow\) allowed to be disentangled
Propose 2 new automated metrics
- 1) perceptual path length
- 2) linear separability
for quantifying these aspects of \(G\)
2. Style-based Generator
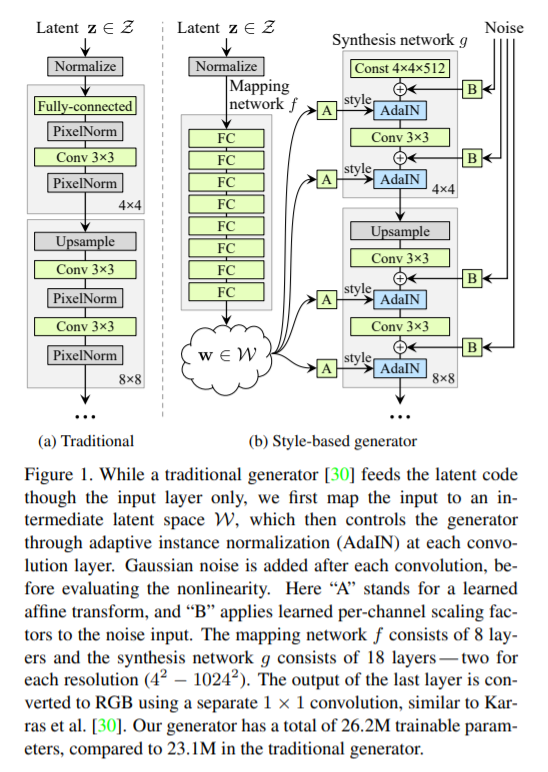
(Traditionally)
- latent code \(\rightarrow\) input layer
(Proposed)
- omitting the input layer altogether….
-
start from a learned constant instead!
- use “intermediate latent space”
- then, controls the \(G\) through AdaIN at each convolution layer
- \(A\) : learned affine transform
- specialize \(w\) to styles \(\mathbf{w}\) to styles \(\mathbf{y}=\left(\mathbf{y}_{s}, \mathbf{y}_{b}\right)\) that control AdaIN
- \(B\) : learned per-channel scaling factors to the noise input
- \(A\) : learned affine transform
AdaIN
\(\operatorname{AdaIN}\left(\mathbf{x}_{i}, \mathbf{y}\right)=\mathbf{y}_{s, i} \frac{\mathbf{x}_{i}-\mu\left(\mathbf{x}_{i}\right)}{\sigma\left(\mathbf{x}_{i}\right)}+\mathbf{y}_{b, i}\).
- each feature map \(\mathbf{x}_{i}\) is normalized separately
Compared to style transfer…
- compute the spatially invariant style \(\mathbf{y}\) from vector \(\mathbf{w}\) , instead of example image
- provide \(G\) with direct means to generate stochastic detail by introducing explicit noise
3. Properties of Style-based Generator
proposed \(G\) : able to control the image synthesis,
- via scale-specific modifications to the styles
1) Mapping Network & Affine transformation
= draw samples for each style from a learend distn
2) Synthesis network
= generate novel images, based on a collection of styles3-1. Style Mixing
-
to encourage the styles to localize… use mixing regularization
-
use 2 random latent code!
- when generating image, switch from one to another at certain time
-
ex) \(\mathbf{z}_1\) & \(\mathbf{z}_2\) through mapping network,
make \(\mathbf{w}_1\) & \(\mathbf{w}_2\) control the styles
-
this regularization prevents the network from assuming that adjacent styles are correlated
- ex) make hair style & hair color decorrelated
images synthesized by mixing two latent codes at various scales


3-2. Stochastic Variation
ex) exact placement of hairs, stubble, freckles, skin pores…
how to make variation?
\(\rightarrow\) adding per-pixel noise AFTER each convolution

4. Disentanglement studies
by NOT DIRECTLY making image from \(z\)….
( = by using MAPPING NETWORK… )
\(\rightarrow\) \(\mathbf{w}\) need not follow fixed distn!
use more flexible intermediate latent space, thus easier to control visual attribute!
