
[Paper Review] 14. Analyzing and Improving the Image Quality of StyleGAN
Contents
- Abstract
- Introduction
- Removing Normalization Artifacts
- Generator architecture revised
- Instance Normalization Revisited
0. Abstract
StyleGAN : SOTA
- data-driven unconditional generative image modeling
This paper proposes changes in both model architecture & training methods
- redesign the generator normalization
- revisit progressive growing
- regularize generator
Result
-
improved image quality
-
\(G\) becomes easier to invert
( makes it possible to reliably attribute a generated image to a particular network )
1. Introduction
StyleGAN
Mapping network \(f\) :
-
transforms \(\mathbf{z} \in \mathcal{Z}\) into intermediate latent code \(\mathbf{w} \in \mathcal{W}\)
-
then, affine transform produces styles that control the layers of synthesis network \(g\),
via AdaIN(Adaptive Instance Normalization)
-
stochastic variation
This paper
-
solely focus on \(\mathcal{W}\),
as it is the relevant latent space from synthesis network’s point of view
-
(1) redesign the normalization used in \(G\) ( which removes the artifacts )
-
(2) analyze artifacts, related to progressive growing
-
propose an alternative design!
( = training starts by focusing on LOW-resolution…then progressively shifts to HIGH-~ )
-
2. Removing Normalization Artifacts
observe that StyleGAN exhibit characteristic blob-shaped artifacts
[ Problem of AdaIN operation ]
-
AdaIN : normalize mean/std of feature map separately,
\(\rightarrow\) destroy any info, found in the magnitudes of the features relative to each other
( proof(?) : when normalization is removed… droplet disappears! )
2-1. Generator architecture revised
Revise several details of StyleGAN
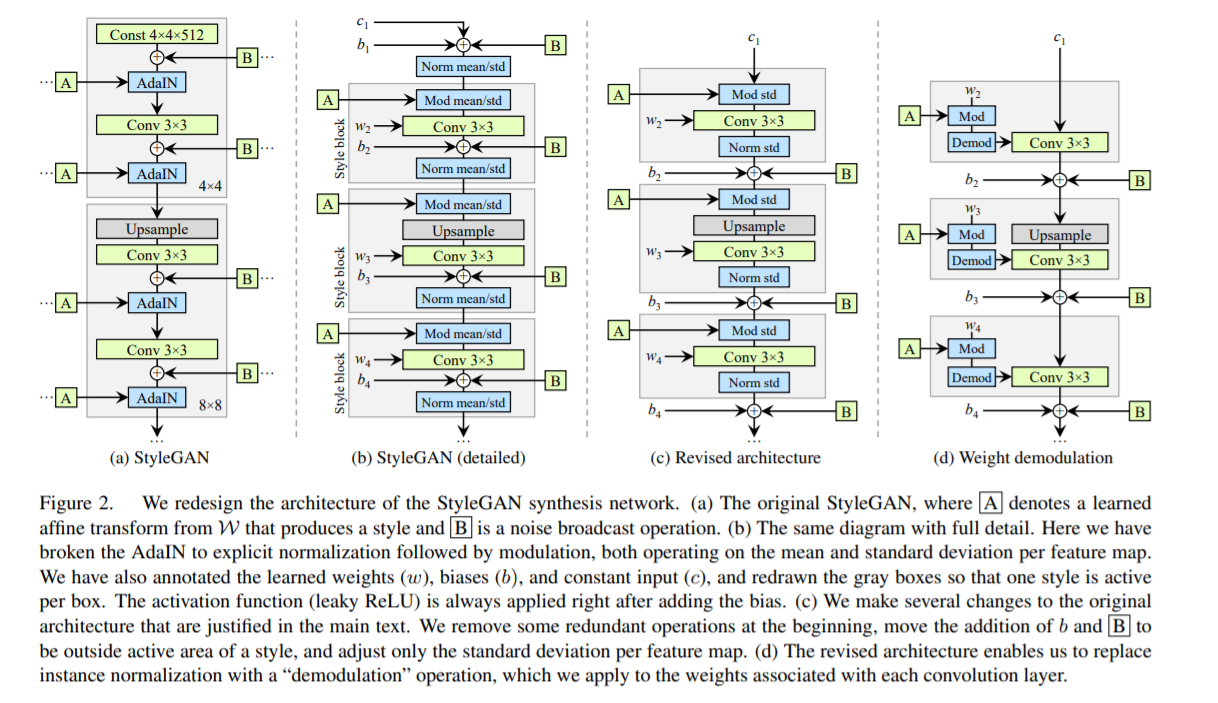
Figure 2(a)
- original Style GAN
Figure 2(b)
- expand 2(a) in full detail ( by showing weights & biases )
- [1] breaking AdaIN operation in 2 parts
- 1) Normalization
- 2) Modulation ( = linear transformation )
- [2] Style Block
- 1) [1]-2 Modulation
- 2) Convolution
- 3) Normalization
- original StyleGAN : applies bias & noise within the style block
Figure 2(c)
- proposed StyleGAN : applies bias & noise OUTSIDE the style block
- when normalizing both … only “std” is needed ( not “mean” )
2-2. Instance Normalization Revisited
Figure 2(d)
2 key points
- 1) remove the normalization
- 2) scale the convolution weights + normalize ( by std )
[ scale the convolution weights ]
\(w_{i j k}^{\prime}=s_{i} \cdot w_{i j k}\).
- \(w\) and \(w^{\prime}\) : original and modulated weights
- \(s_{i}\) : scale, corresponding to the \(i\)th input feature map
- \(j\) and \(k\) : enumerate the output feature maps and spatial footprint of the convolution
[ normalize by std ]
\(w_{i j k}^{\prime \prime}=w_{i j k}^{\prime} / \sqrt{\sum_{i, k} w_{i j k}^{\prime}{ }^{2}+\epsilon}\).
- std : \(\sigma_{j}=\sqrt{\sum_{i, k} w_{i j k}^{\prime}{ }^{2}}\)