Multimodal Learning (1) Multimodal Representations
참고 논문 :
Baltrušaitis, Tadas, Chaitanya Ahuja, and Louis-Philippe Morency. “Multimodal machine learning: A survey and taxonomy.” IEEE transactions on pattern analysis and machine intelligence 41.2 (2018): 423-443.
Contents
- Abstract
- Introduction
- Multimodal Representations
- Unimodal Representation
- Multimodal Representation의 2 종류
- Joint representation 모델
- Coordinated representation 모델
- 요약
- Translation
- Example-based
- Generative approaches
- Alignment
- Explicit alignment
- Implicit alignment
- 요약
- Fusion
- Model-agnostic approaches
- Model-based approaches
- 요약
- Co-learning
- Parallel data
- Non-parallel data
- Hybrid data
- 요약
- Conclusion
0. Abstract
우리가 얻게 되는 데이터는 수 많은 source에서 온다! (Multimodalities)
Multimodal Learning의 challenges :
- 1) representation
- 2) translation
- 3) alignment
- 4) fusion
- 5) co-learning
1. Introduction
이 논문에서는 3가지 multimodality에 집중!
- 1) natural language ( written & spoken )
- 2) visual signals ( images & videos )
- 3) vocal signals
Multimodal ML의 목표 :
- build models that can process/relate informations from multiple modalities
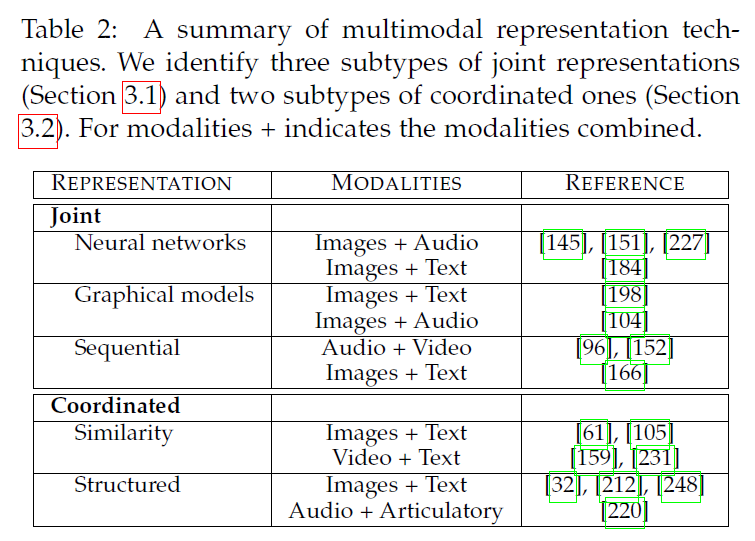
[ 5가지 challenges ]
1) representation
- multimodal data를 얼마나 잘 축약(represent/summarize)하는지
- “잘 축약하다” = 서로 다른 데이터의 “상호보완성/중복성을 잘 캐치한다”
2) Translation
- 하나의 modality에서 다른 modality로 translate!
- 단 하나의 정답만 존재하는 것은 X
3) Alignment
-
여러 modality 사이의 relation 파악
( = measure similarity )
4) Fusion
- 여러 modality의 데이터를 잘 join하여 예측을 수행
- ex) 입모양을 통해, 하고 있는 말 예측하기
5) Co-learning
- “transfer knowledge between modalities”
- 정보가 풍부한 특정 modality를 사용하여, 정보가 부족한 다른 modality 보완!
2. Multimodal Representations
핵심 : “다른 modality의 데이터를 어떻게 combine하여 좋은 representation으로 나타낼까?”
좋은 representation이란?
- smoothness
- temporal & spatial coherence
- sparsity
- Similarity in the representation space를 통해 검증하기!
(1) Unimodal Representation
- 이미지) CNN
- 음성)
- speech recognition) MFCC (Mel-frequency cepstral coefficients)
- para-linguistic analysis) RNN
- 텍스트)
- (구) count based
- (신) word-embedding
\(\rightarrow\) 여태까지는, multimodal representation이라하면. 단지 이 unimodal representation들을 concatenate하는 것에 불과했었다. 하지만 최근에 다양한 방법론들이 제안되고 있음!
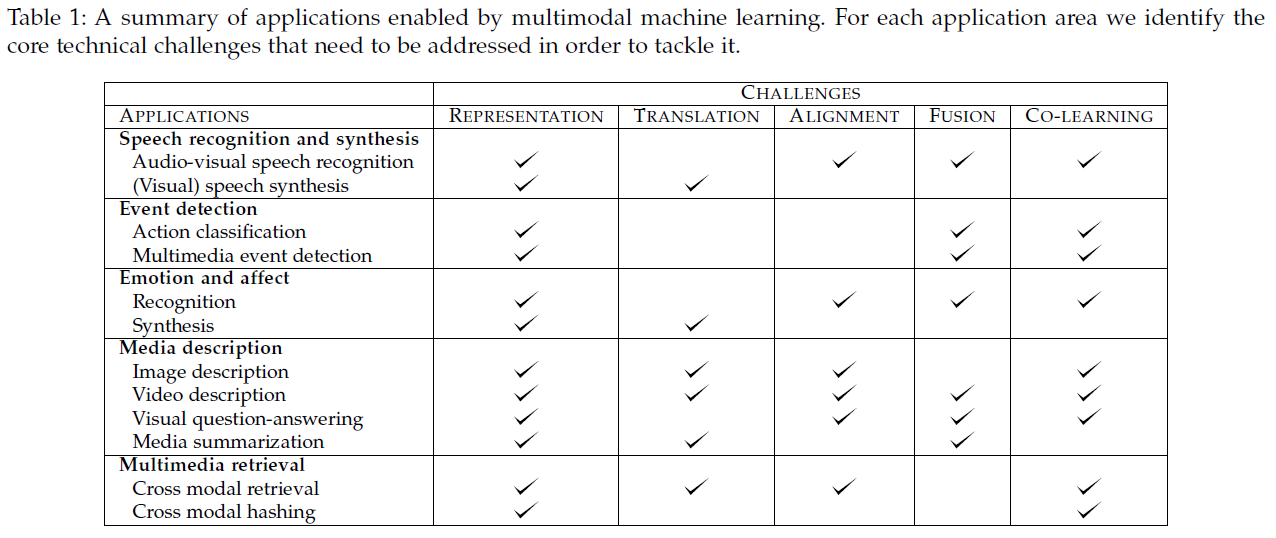
(2) Multimodal Representation의 2 종류
- Joint Representation
- Coordinated Representation
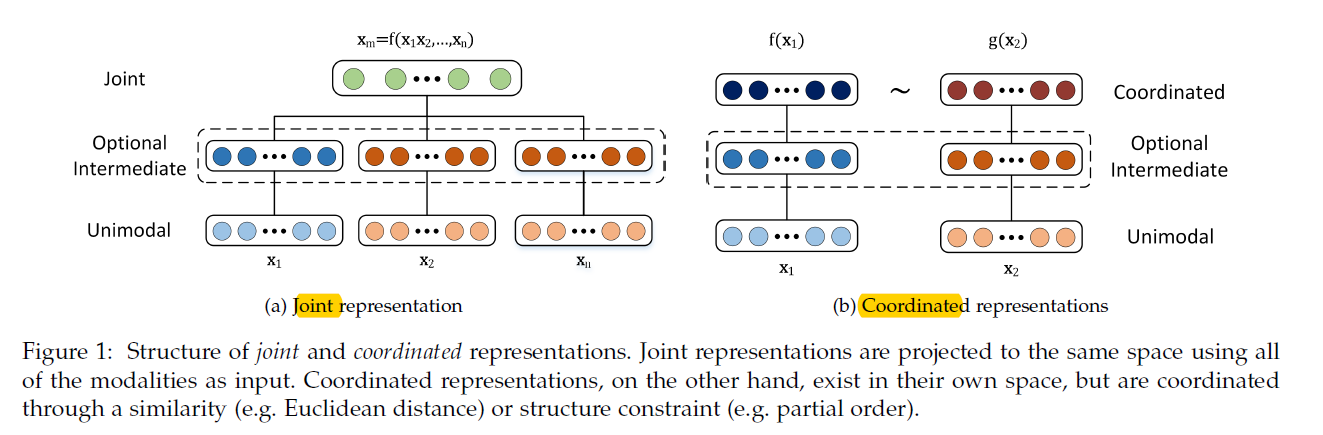
a) Joint representation
- unimodal representation을 같은 space에 combine시킴
- \(\mathbf{x}_{m}=f\left(\mathbf{x}_{1}, \ldots, \mathbf{x}_{n}\right)\).
- \(f\) : DNN, RBM, RNN,…
-
주로 사용하는 때 : training & inference step에서 모두 multimodal data가 존재할 때
- 3가지 모델
- 1) Neural Networks (NN)
- 2) Probabilistic Graphical Models (PGM)
- 3) Sequential Representation
b) Coordinated representation
- unimodal signal을 각각 따로 처리하고, 특정 similarity constraint를 사용하여 그들을 coordinated space상응로 가져옴
- \(f\left(\mathrm{x}_{1}\right) \sim g\left(\mathrm{x}_{2}\right)\).
- 각각의 modality는 자신만의 function (위의 \(f,g\))가 있음
- 각각의 결과로 나온 space는 서로 coordinated 되어 있음 ( notation : \(\sim\) )
- ex) cosine distance 최소화, correlation 최대화, 서로 다른 space간에 partial order enforce
- 주요 모델
- 4) Similarity models
- 5) Structured Coordinated Space models
(3) Joint representation 모델
모델 1) Neural Networks (NN)
-
end-to-end 학습 ( representation & prediction 한번에 )
-
Pre-train하여 사용
1) ( Ngiam et al ) Autoencoders 사용
- (1) Stacked denoising AE 사용하여 modality 각각 따로 represent
- (2) 그런 뒤 Multimodal representation로 fuse ( 또 다른 AE 사용해서 )
2) Silberer and Lapata
-
Multimodal autoencoder for the task of semantic concept grounding
-
사용 loss function :
- 요소 1) Reconstruction loss
- 요소 2) representation to predict object labels ! 여기서 발생한 loss
-
Fine-tune the resulting representation
-
NN의 장/단점
- 장) pre-train 사용가능
- 단) data 양 부족한 경우
모델 2) Probabilistic Graphical Models (PGM)
-
latent random variable 사용하여 representation 생성
-
1) DBM (deep Boltzmann machines)
-
학습 과정에서 label 달린 데이터 필요 없음!
-
probabilistic한 모델이나, determistic NN으로 바꿀 수도 있음
( but generative 속성 사라짐 )
-
-
2) Multimodal DBN (deep belief networks) ( Srivastava and Salakhutdinov )
-
3) DBN을 각 modality에 적용한 이후, combine하여 joint representation 생성 (Kim et al.)
-
4) Multimodal DBN을 Multimodal DBM으로 확장 ( Srivastava and Salakhutdinov )
- low level representation에서 modality 끼리 서로 영향 주고받음
-
그 밖에도 다양한 적용 사례…
Multimodal DBM의 장/단점
- 장점) generative 속성
- missing data 다루기 good)
- 한 modality의 데이터를 통해, 다른 modality의 데이터 생성 가능!
- 단점) computational cost
- variational training method 사용해서 해결 노력
모델 3) Sequential Representation
- fixed length 데이터가 아닌 경우! (sequential data)
- RNNS, LSTMs
- hidden state at time stamp \(t\) : \(t\)시점까지의 “summarization”으로 볼 수 있음
- 단지 unimodal domain에 국한되어 있는 건 X
- Multimodal Representation using RNNs ( Cosi et al )
(4) Coordinated representation 모델
앞서 말했듯이, 각 modality에서 각자의 representation을 학습한다 ( with constraint )
constraint : “enforce similarity between representations”
모델 4) Similarity Models
-
목표 : “minimize distance between modalities in the coordinated space”
- ex) “사진” 강아지와, “단어” 강아지의 거리가 가깝도록!
-
1) WSABIE (web scale annotation by image embedding)
- 데이터 : 이미지 & 주석(설명)
- simple linear mapping
- inner product \(\rightarrow\) cosine distance 사용
( 최근에는 Neural Networks… “end-to-end” )
-
2) DeViSE (deep visual-semantic embedding)
- WSABIE와 비슷한 inner product / ranking loss function
- NN 사용하여 더 complex한 image & word embedding
-
3) DeViSE에 LSTM 적용 & pairwise ranking loss 사용 ( Kiros et al )
-
그 밖에도, 이미지 대신 비디오 사용한 모델들도 등장
\(\rightarrow\) 지금까지 언급한 위의 모델들은 representation들 사이의 “similarity”를 enforce함.
모델 5) Structured Coordinated Space models
-
similarity enforce 보다 더 나아가서, 추가적인 constraint 부여
ex) hashing, cross-modal retrieval, image captioning
-
주로 cross-modal hashing에서 사용
- “compression of high-dimension data into compact binary codes with similar binary codes for similar objects”
-
Hashing 세 가지 요건
- a) N-차원의 Hamming Space (binary representation)
- b) 같은 object, 다른 modalities : 비슷한 hash code 가져야
- c) space는 similarity preserving해야
-
a) DNN 적용 ( Jiang and Li )
- binary space between 문장 & 이미지
-
b) LSTM ( Cao et al )
- outlier insensitive bit-wise margin loss
- relevance feedback based semantic similarity constraint
-
c) CCA based model (Canonical Correlation Analysis)
-
핵심 : random variable 사이의 correlation을 maximize하는 linear projection 계산
-
extensions ) CCA를 non-linear하게!
-
KCCA (Kernel CCA) : reproducing kernel Hilbert space 사용
( RKHS는 여기 참고 : https://hgmin1159.github.io/dimension/nonlineardr/ )
nonparametric하기 때문에 scalability 안좋음…
-
DCCA (Deep CCA)
KCCA의 scalability 문제 해결 + 더 나은 성능!
-
-
CCA 모델들 요약 :
- “unsupervised technique”
- “only optimize correlation over the representations”
-
Deep canonically correlated autoencoder
-
AE based reconstruction term 또한 추가!
( representation으로 하여금 modality specific info 또한 잡아낼 수 있게끔 함 )
-
-
그 외) Semantic correlation maximization method…
\(\rightarrow\) CCA와 cross-modal hashing의 combination 가능케함!
-
(5) 요약